Merge branch 'master' into master
Showing
docs/mixed_precision.md
已删除
100755 → 0
images/fc_computing.png
0 → 100644
{kind=link}
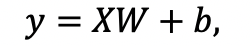
11.8 KB
images/fc_computing_block.png
0 → 100644
{kind=link}
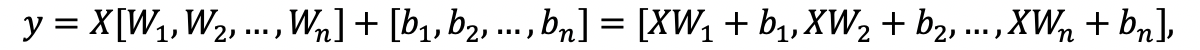
39.4 KB
{kind=link}
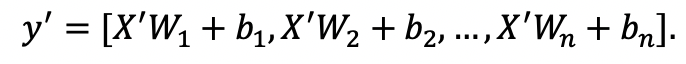
26.4 KB
images/softmax_computing.png
0 → 100644
{kind=link}
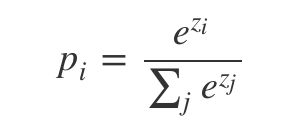
9.7 KB
| numpy>=1.12, <=1.16.4 ; python_version<"3.5" | numpy>=1.12, <=1.16.4 ; python_version<"3.5" | ||
| numpy>=1.12 ; python_version>="3.5" | numpy>=1.12 ; python_version>="3.5" | ||
| scipy>=0.19.0, <=1.2.1 ; python_version<"3.5" | scipy>=0.19.0, <=1.2.1 ; python_version<"3.5" | ||
| paddlepaddle>=1.6.2 | |||
| scipy ; python_version>="3.5" | scipy ; python_version>="3.5" | ||
| Pillow | Pillow | ||
| sklearn | sklearn | ||
| ... | ... |