Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
PaddlePaddle
PLSC
提交
1db4c85c
P
PLSC
项目概览
PaddlePaddle
/
PLSC
通知
12
Star
3
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
5
列表
看板
标记
里程碑
合并请求
4
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PLSC
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
5
Issue
5
列表
看板
标记
里程碑
合并请求
4
合并请求
4
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
未验证
提交
1db4c85c
编写于
5月 12, 2020
作者:
L
lilong12
提交者:
GitHub
5月 12, 2020
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
add a pic to show how plsc works (#54)
* add a pic to show how plsc works * modify image size
上级
bd3f00ce
变更
2
隐藏空白更改
内联
并排
Showing
2 changed file
with
6 addition
and
0 deletion
+6
-0
README.md
README.md
+6
-0
images/plsc_overview.png
images/plsc_overview.png
+0
-0
未找到文件。
README.md
浏览文件 @
1db4c85c
...
@@ -7,6 +7,12 @@
...
@@ -7,6 +7,12 @@
2.
参数量较大,同步训练方式下通信开销较大:数据并行训练方式下,所有GPU卡之间需要同步参数的梯度信息,以完成参数值的同步更新。当参数数量较大时,参数的梯度信息数据量同样较大,从而导致参数梯度信息的通信开销较大,影响训练速度。
2.
参数量较大,同步训练方式下通信开销较大:数据并行训练方式下,所有GPU卡之间需要同步参数的梯度信息,以完成参数值的同步更新。当参数数量较大时,参数的梯度信息数据量同样较大,从而导致参数梯度信息的通信开销较大,影响训练速度。
考虑到全接连层的线性可分性,可以将全连接层参数切分到多张GPU卡,减少每张GPU卡的参数存储量。
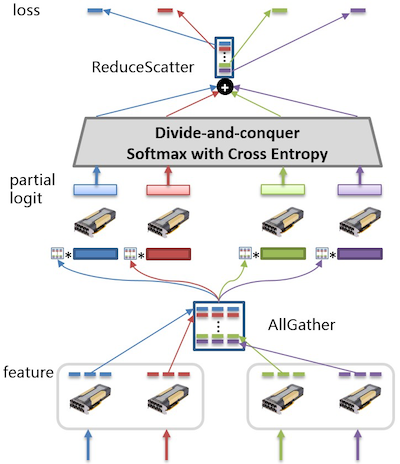
以下图为例,全连接层参数按行切分到不同的GPU卡上。每次训练迭代过程中,各张GPU卡分别以各自的训练数据计算隐层的输出特征,并通过集合通信操作AllGather得到汇聚后的特征。接着,各张GPU卡以汇聚后的特征和部分全连接层参数计算部分logit值(partial logit),并基于此计算神经网络的损失值。

飞桨大规模分类(PLSC:
**P**
addlePaddle
**L**
arge
**S**
cale
**C**
lassification)库是基于
[
飞桨平台
](
https://github.com/PaddlePaddle/Paddle
)
构建的超大规模分类库,为用户提供从训练到部署的大规模分类问题全流程解决方案。
飞桨大规模分类(PLSC:
**P**
addlePaddle
**L**
arge
**S**
cale
**C**
lassification)库是基于
[
飞桨平台
](
https://github.com/PaddlePaddle/Paddle
)
构建的超大规模分类库,为用户提供从训练到部署的大规模分类问题全流程解决方案。
## PLSC特性
## PLSC特性
...
...
images/plsc_overview.png
0 → 100644
浏览文件 @
1db4c85c
138.9 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}