@@ -30,13 +30,13 @@ The newly released PGL supports heterogeneous graph learning on both walk based
...
@@ -30,13 +30,13 @@ The newly released PGL supports heterogeneous graph learning on both walk based
## Highlight: Efficiency - Support Scatter-Gather and LodTensor Message Passing
## Highlight: Efficiency - Support Scatter-Gather and LodTensor Message Passing
One of the most important benefits of graph neural networks compared to other models is the ability to use node-to-node connectivity information, but coding the communication between nodes is very cumbersome. At PGL we adopt **Message Passing Paradigm** similar to [DGL](https://github.com/dmlc/dgl) to help to build a customize graph neural network easily. Users only need to write ```send``` and ```recv``` functions to easily implement a simple GCN. As shown in the following figure, for the first step the send function is defined on the edges of the graph, and the user can customize the send function  to send the message from the source to the target node. For the second step, the recv function  is responsible for aggregating  messages together from different sources.
One of the most important benefits of graph neural networks compared to other models is the ability to use node-to-node connectivity information, but coding the communication between nodes is very cumbersome. At PGL we adopt **Message Passing Paradigm** similar to [DGL](https://github.com/dmlc/dgl) to help to build a customize graph neural network easily. Users only need to write ```send``` and ```recv``` functions to easily implement a simple GCN. As shown in the following figure, for the first step the send function is defined on the edges of the graph, and the user can customize the send function 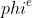 to send the message from the source to the target node. For the second step, the recv function 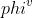 is responsible for aggregating  messages together from different sources.
<imgsrc="./docs/source/_static/message_passing_paradigm.png"alt="The basic idea of message passing paradigm"width="800">
<imgsrc="./docs/source/_static/message_passing_paradigm.png"alt="The basic idea of message passing paradigm"width="800">
As shown in the left of the following figure, to adapt general user-defined message aggregate functions, DGL uses the degree bucketing method to combine nodes with the same degree into a batch and then apply an aggregate function  on each batch serially. For our PGL UDF aggregate function, we organize the message as a [LodTensor](http://www.paddlepaddle.org/documentation/docs/en/1.4/user_guides/howto/basic_concept/lod_tensor_en.html) in [PaddlePaddle](https://github.com/PaddlePaddle/Paddle) taking the message as variable length sequences. And we **utilize the features of LodTensor in Paddle to obtain fast parallel aggregation**.
As shown in the left of the following figure, to adapt general user-defined message aggregate functions, DGL uses the degree bucketing method to combine nodes with the same degree into a batch and then apply an aggregate function  on each batch serially. For our PGL UDF aggregate function, we organize the message as a [LodTensor](http://www.paddlepaddle.org/documentation/docs/en/1.4/user_guides/howto/basic_concept/lod_tensor_en.html) in [PaddlePaddle](https://github.com/PaddlePaddle/Paddle) taking the message as variable length sequences. And we **utilize the features of LodTensor in Paddle to obtain fast parallel aggregation**.
<imgsrc="./docs/source/_static/parallel_degree_bucketing.png"alt="The parallel degree bucketing of PGL"width="800">
<imgsrc="./docs/source/_static/parallel_degree_bucketing.png"alt="The parallel degree bucketing of PGL"width="800">
@@ -6,54 +6,32 @@ information (e.g., text attributes) to efficiently generate node embeddings for
...
@@ -6,54 +6,32 @@ information (e.g., text attributes) to efficiently generate node embeddings for
For purpose of high scalability, we use redis as distribute graph storage solution and training graphsage against redis server.
For purpose of high scalability, we use redis as distribute graph storage solution and training graphsage against redis server.
### Datasets(Quickstart)
### Datasets(Quickstart)
The reddit dataset should be downloaded from [reddit_adj.npz](https://drive.google.com/open?id=174vb0Ws7Vxk_QTUtxqTgDHSQ4El4qDHt) and [reddit.npz](https://drive.google.com/open?id=19SphVl_Oe8SJ1r87Hr5a6znx3nJu1F2Jthe). The details for Reddit Dataset can be found [here](https://cs.stanford.edu/people/jure/pubs/graphsage-nips17.pdf).
The reddit dataset should be downloaded from [reddit_adj.npz](https://drive.google.com/open?id=174vb0Ws7Vxk_QTUtxqTgDHSQ4El4qDHt) and [reddit.npz](https://drive.google.com/open?id=19SphVl_Oe8SJ1r87Hr5a6znx3nJu1F2J). The details for Reddit Dataset can be found [here](https://cs.stanford.edu/people/jure/pubs/graphsage-nips17.pdf).
Alternatively, reddit dataset has been preprocessed and packed into docker image, which can be instantly pulled using following commands.
@@ -32,10 +32,14 @@ Thanks to the flexibility and usability of PGL, **ERNIESage** can be quickly imp
...
@@ -32,10 +32,14 @@ Thanks to the flexibility and usability of PGL, **ERNIESage** can be quickly imp
- pgl>=1.1
- pgl>=1.1
## Dataformat
## Dataformat
In the example data ```data.txt```, part of NLPCC2016-DBQA is used, and the format is "query \t answer" for each line.
```text
NLPCC2016-DBQA is a sub-task of NLPCC-ICCPOL 2016 Shared Task which is hosted by NLPCC(Natural Language Processing and Chinese Computing), this task targets on selecting documents from the candidates to answer the questions. [url: http://tcci.ccf.org.cn/conference/2016/dldoc/evagline2.pdf]
```
## How to run
## How to run
We adopt [PaddlePaddle Fleet](https://github.com/PaddlePaddle/Fleet) as our distributed training frameworks ```config/*.yaml``` are some example config files for hyperparameters.
We adopt [PaddlePaddle Fleet](https://github.com/PaddlePaddle/Fleet) as our distributed training frameworks ```config/*.yaml``` are some example config files for hyperparameters. Among them, the ERNIE model checkpoint ```ckpt_path``` and the vocabulary ```ernie_vocab_file``` can be downloaded on the [ERNIE](https://github.com/PaddlePaddle/ERNIE) page.