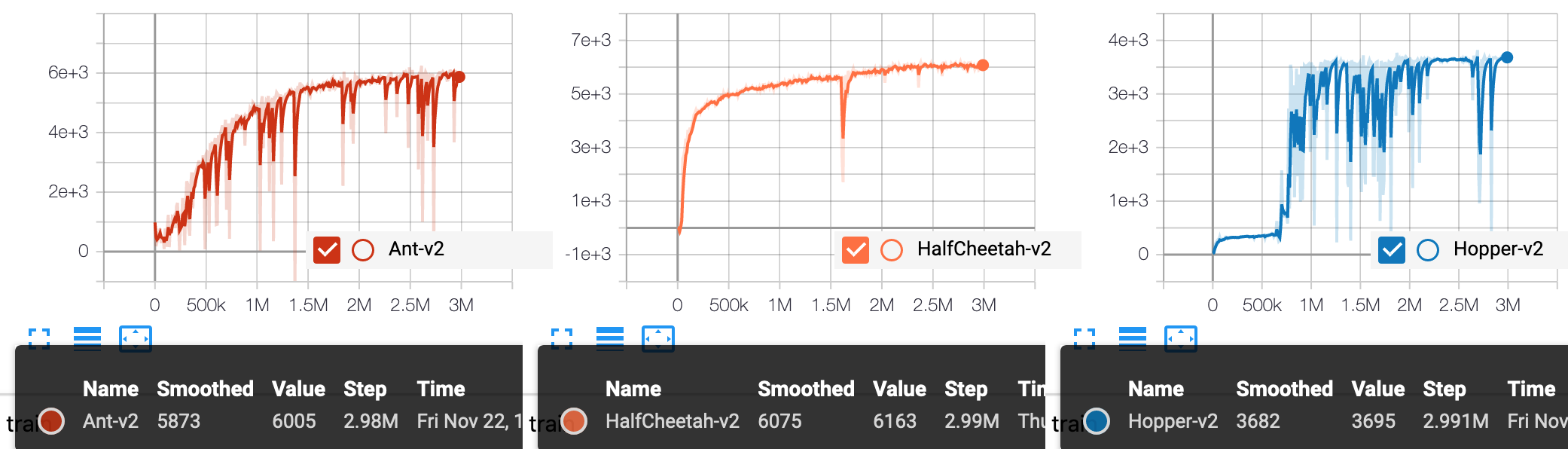
Based on PARL, the TD3 algorithm of deep reinforcement learning has been reproduced, reaching the same level of indicators as the paper in Mujoco benchmarks.
Include following approaches:
+ Clipped Double Q-learning
+ Target Networks and Delayed Policy Update
+ Target Policy Smoothing Regularization
> TD3 in
[Addressing Function Approximation Error in Actor-Critic Methods](https://arxiv.org/abs/1802.09477)
### Mujoco games introduction
Please see [here](https://github.com/openai/mujoco-py) to know more about Mujoco games.
{kind=link}