add TD3 (#175)
* add TD3 * update * yapf..... * Update train.py
Showing
examples/TD3/.benchmark/merge.png
0 → 100644
{kind=link}
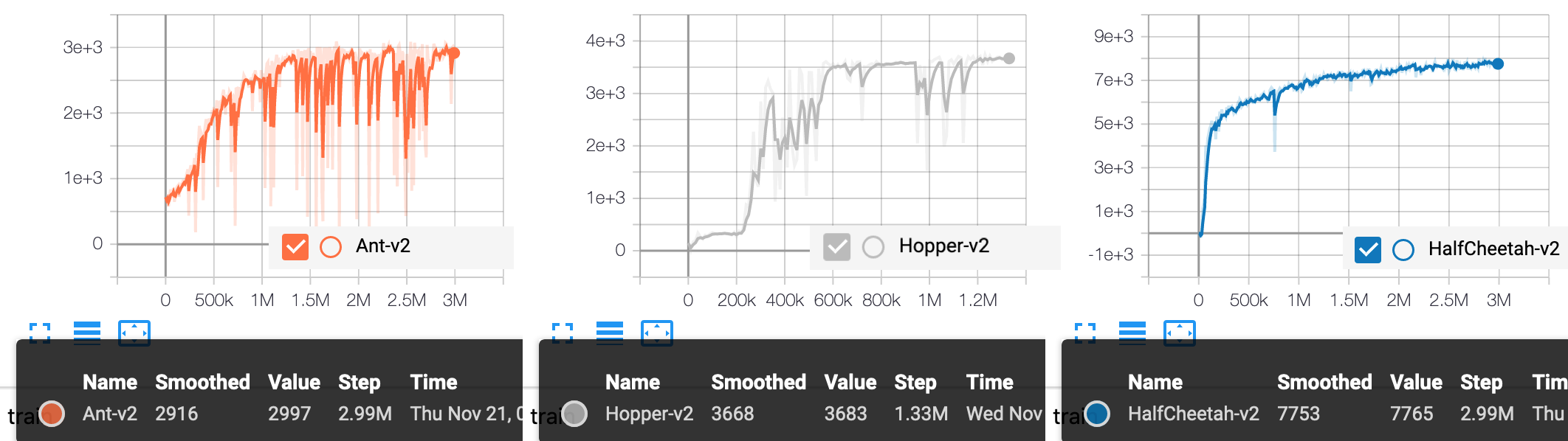
172.1 KB
examples/TD3/README.md
0 → 100644
examples/TD3/mujoco_agent.py
0 → 100644
examples/TD3/mujoco_model.py
0 → 100644
examples/TD3/train.py
0 → 100644
parl/algorithms/fluid/td3.py
0 → 100644