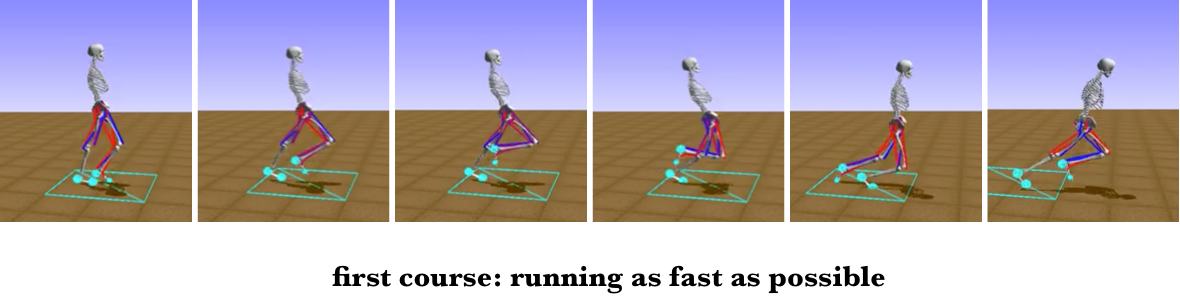
This folder contains the winning solution of our team `Firework` in the NeurIPS 2018: AI for Prosthetics Challenge. It consists of three parts. The first part is our final submitted model, a sensible controller that can follow random target velocity. The second part is used for curriculum learning, to learn a natural and efficient gait at low-speed walking. The last part learns the final agent in the random velocity environment for round2 evaluation.
For more technical details about our solution, we provide:
1.[[Link]](https://youtu.be/RT4JdMsZaTE) An interesting video demonstrating the training process visually.
2.[[Link]](https://docs.google.com/presentation/d/1n9nTfn3EAuw2Z7JichqMMHB1VzNKMgExLJHtS4VwMJg/edit?usp=sharing) A PowerPoint Presentation briefly introducing our solution in NeurIPS2018 competition workshop.
3.[[Link]](https://drive.google.com/file/d/1W-FmbJu4_8KmwMIzH0GwaFKZ0z1jg_u0/view?usp=sharing) A poster briefly introducing our solution in NeurIPS2018 competition workshop.
3. (coming soon)A full academic paper detailing our solution, including entire training pipline, related work and experiments that analyze the importance of each key ingredient.
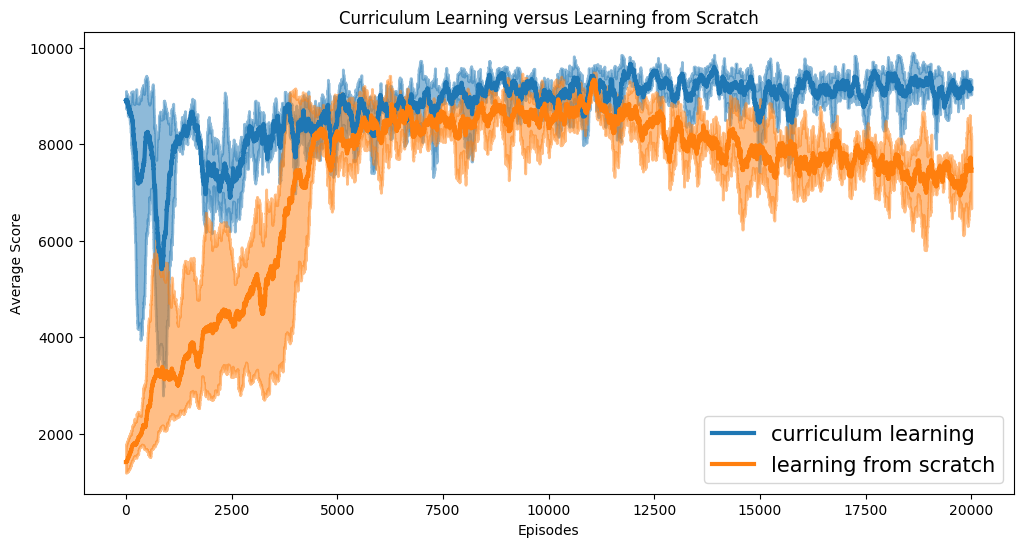
**Note**: Reproducibility is a long-standing issue in reinforcement learning field. We have tried to guarantee that our code is reproducible, testing each training sub-task three times. However, there are still some factors that prevent us from achieving the same performance. One problem is the choice time of a convergence model during curriculum learning. Choosing a sensible and natural gait visually is crucial for subsequent training, but the definition of what is a good gait varies from different people.
<palign="center">
<imgsrc="image/demo.gif"alt="PARL"width="500"/>
</p>
This folder contains the code used to train the winning models for the [NeurIPS 2018: AI for Prosthetics Challenge](https://www.crowdai.org/challenges/neurips-2018-ai-for-prosthetics-challenge) along with the resulting models.
2. Download the model file from online stroage service, [Baidu Pan](https://pan.baidu.com/s/1NN1auY2eDblGzUiqR8Bfqw) or [Google Drive](https://drive.google.com/open?id=1DQHrwtXzgFbl9dE7jGOe9ZbY0G9-qfq3)
> You can download models file from [Baidu Pan](https://pan.baidu.com/s/1NN1auY2eDblGzUiqR8Bfqw) or [Google Drive](https://drive.google.com/open?id=1DQHrwtXzgFbl9dE7jGOe9ZbY0G9-qfq3)
## Part3: Training in random velocity environment for round2 evaluation
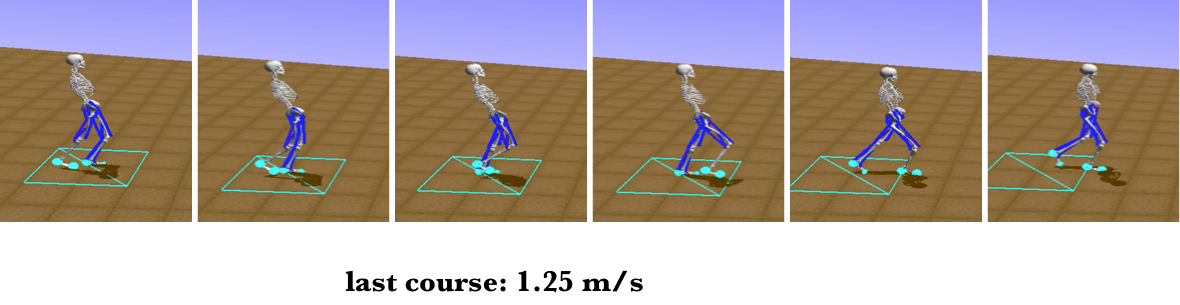
As mentioned before, the selection of model that used to fine-tune influence later training. For those who can not obtain expected performance by former steps, a pre-trained model that walk naturally at 1.25m/s is provided. ([Baidu Pan](https://pan.baidu.com/s/1PVDgIe3NuLB-4qI5iSxtKA) or [Google Drive](https://drive.google.com/open?id=1jWzs3wvq7_ierIwGZXc-M92bv1X5eqs7))
> You can download resulting 1.25m/s model in Stage I from [Baidu Pan](https://pan.baidu.com/s/1PVDgIe3NuLB-4qI5iSxtKA) or [Google Drive](https://drive.google.com/open?id=1jWzs3wvq7_ierIwGZXc-M92bv1X5eqs7)
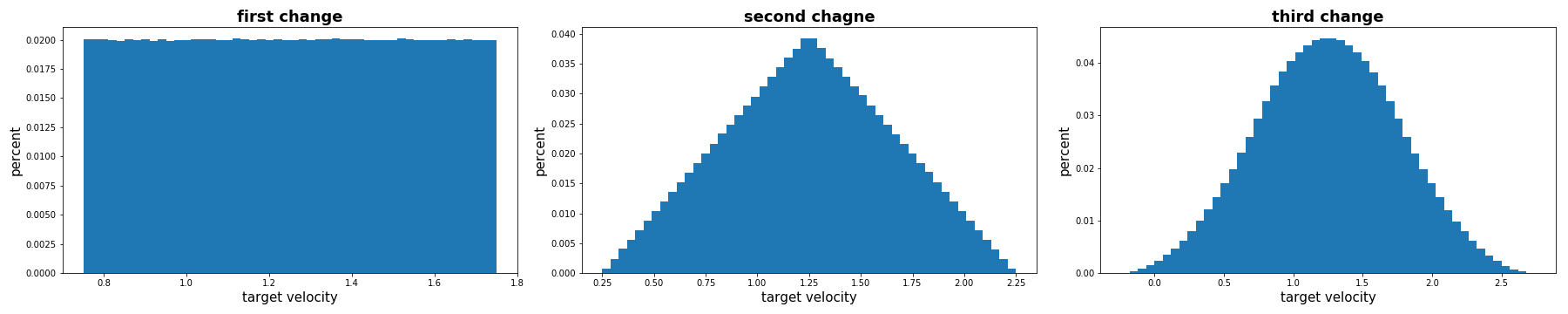
> To get a higher score, you need train a seperate model for every stage (target_v change times), and fix trained model of previous stage. It's omitted here.
Following the above steps correctly, you can get an agent that scores around 9960 in round2. Its performance is slightly poorer than our final submitted model. The score gap results from the multi-stage paradigm. As shown in the above Firgure, the target velocity distribution varies after each change of the target velocity. Thus we actually have 4 models for each stage, they are trained for launch stage, first change stage, second change stage, third change stage respectively. These four models are trained successively, this is, the first stage model is trained while the parameters of launch stage are fixed.We do not provide this part of the code, since it reduces the readability of the code. Feel free to post issue if you have any problem:)
## Acknowledgments
We would like to thank Zhihua Wu, Jingzhou He, Kai Zeng for providing stable computation resources and other colleagues on the Online Learning team for insightful discussions. We are grateful to Tingru Hong, Wenxia Zheng and others for creating a vivid and popular demonstration video.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}