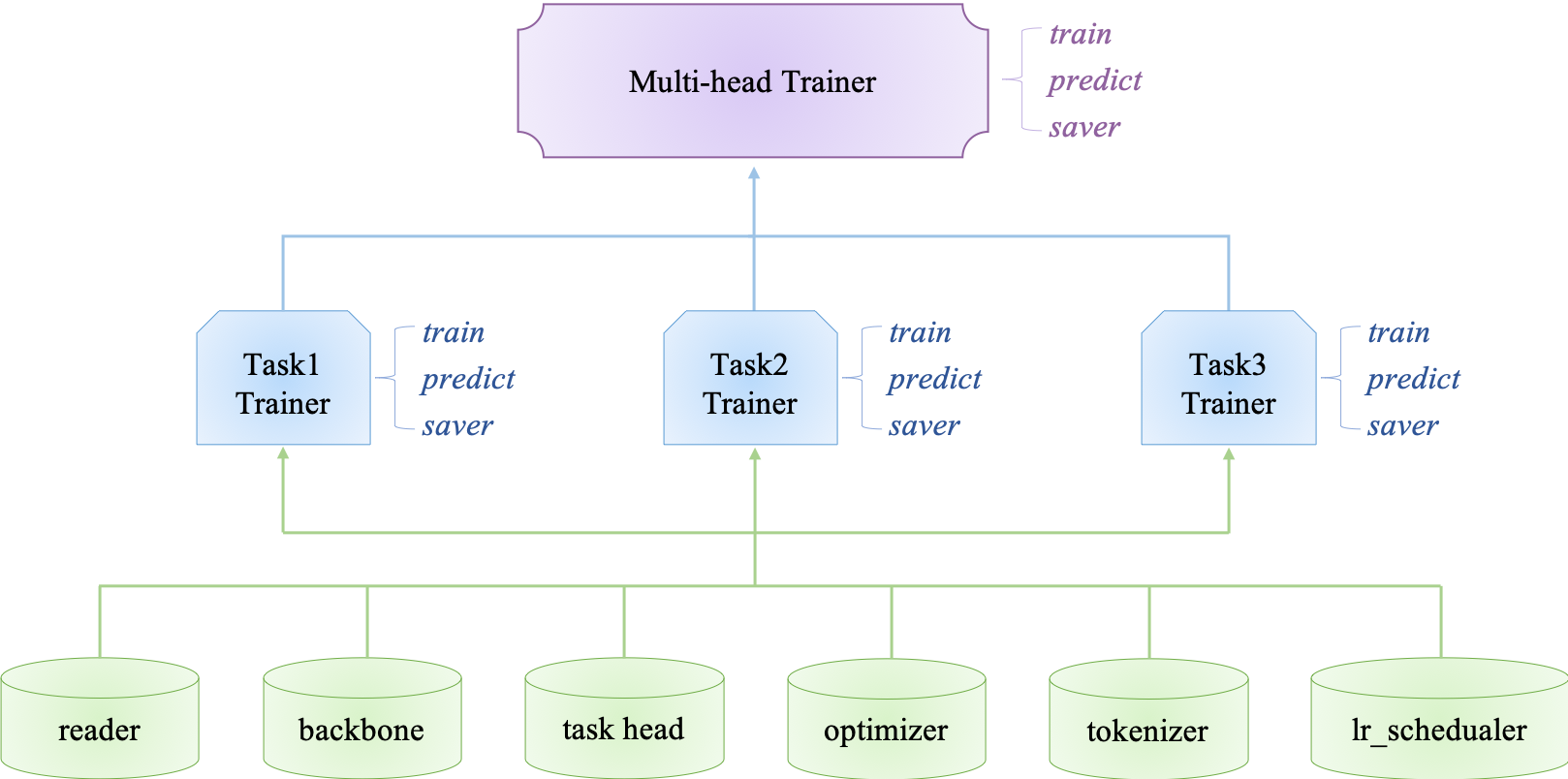
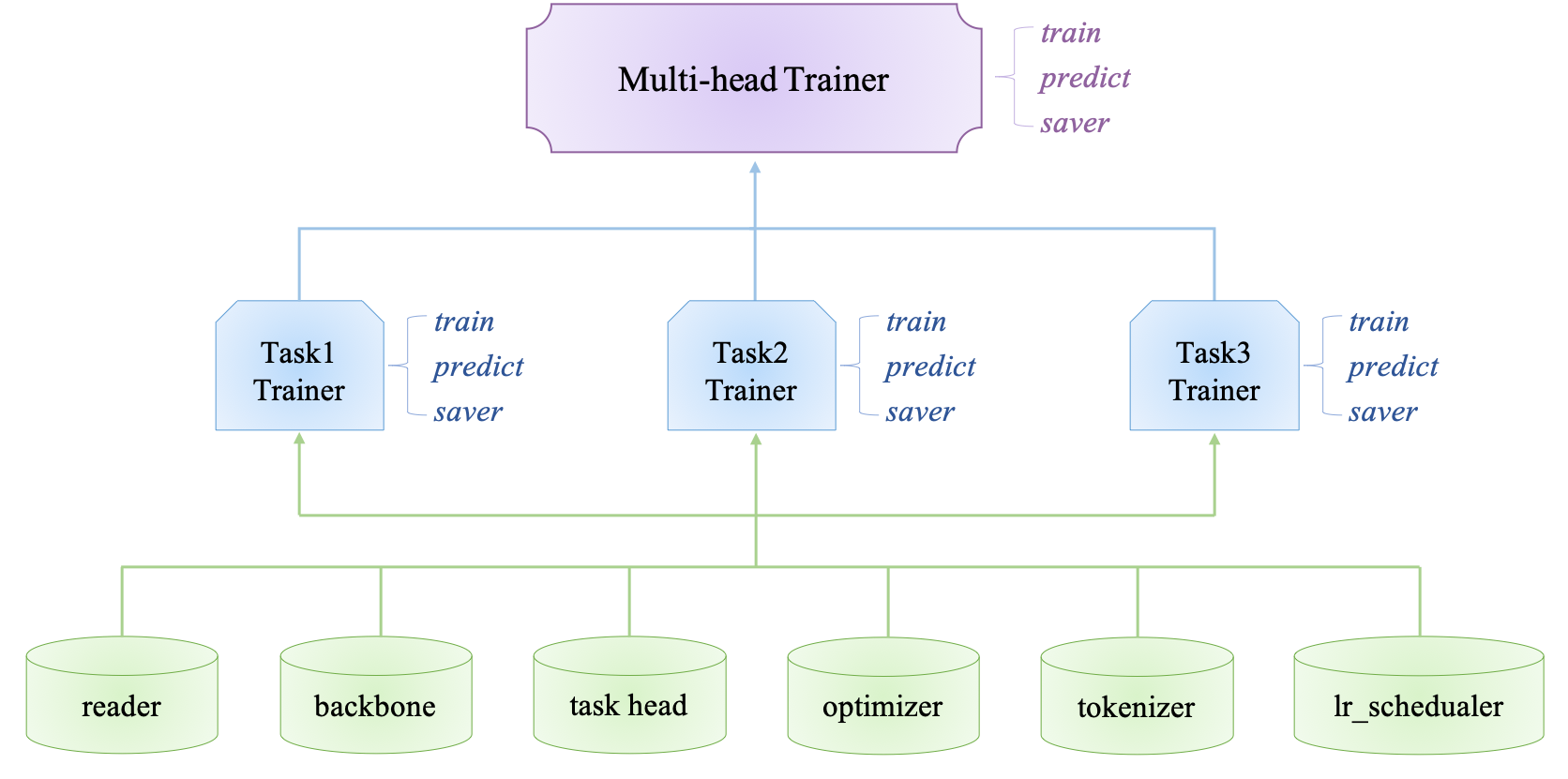
PaddlePALM (PArallel Learning from Multi-tasks) is a fast, flexible, extensible and easy-to-use NLP large-scale pretraining and multi-task learning framework. PaddlePALM is a high level framework aiming at **fastly** developing **high-performance** NLP models.
PaddlePALM (PArallel Learning from Multi-tasks) is a fast, flexible, extensible and easy-to-use NLP large-scale pretraining and multi-task learning framework. PaddlePALM is a high level framework aiming at **fastly** developing **high-performance** NLP models.
...
@@ -115,7 +115,7 @@ You can easily re-produce following competitive results with minor codes, which
...
@@ -115,7 +115,7 @@ You can easily re-produce following competitive results with minor codes, which
{kind=link}
{kind=link}