Merge pull request #75 from typhoonzero/add_train_on_baidu_cloud
Add train on baidu cloud
Showing
{kind=link}
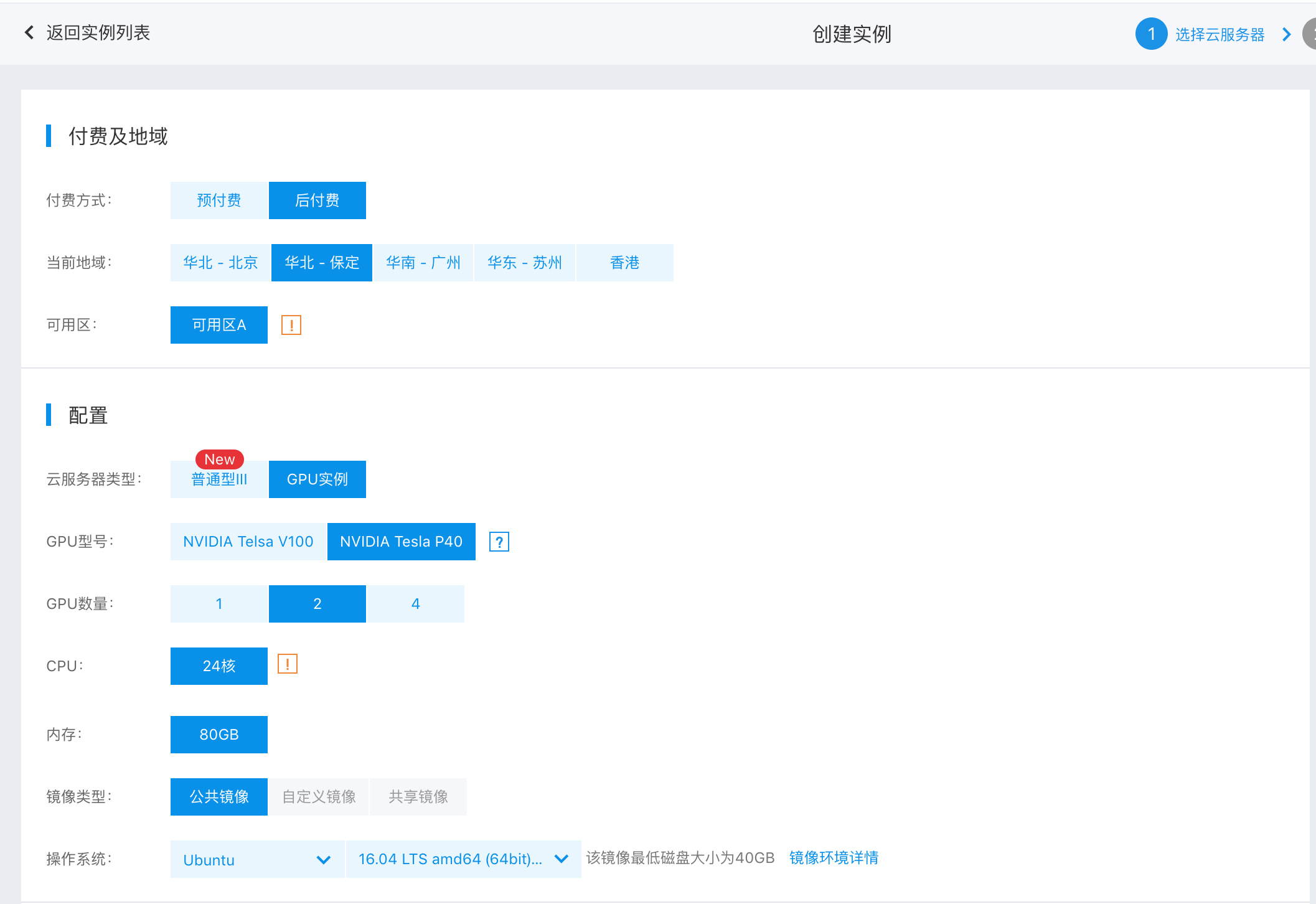
182.4 KB
{kind=link}
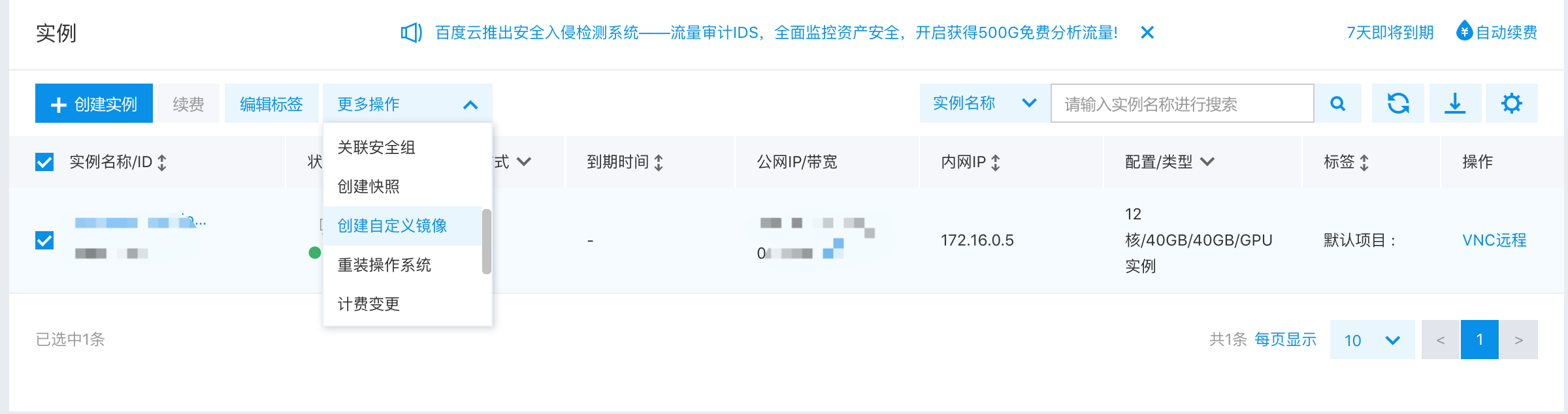
164.0 KB
{kind=link}
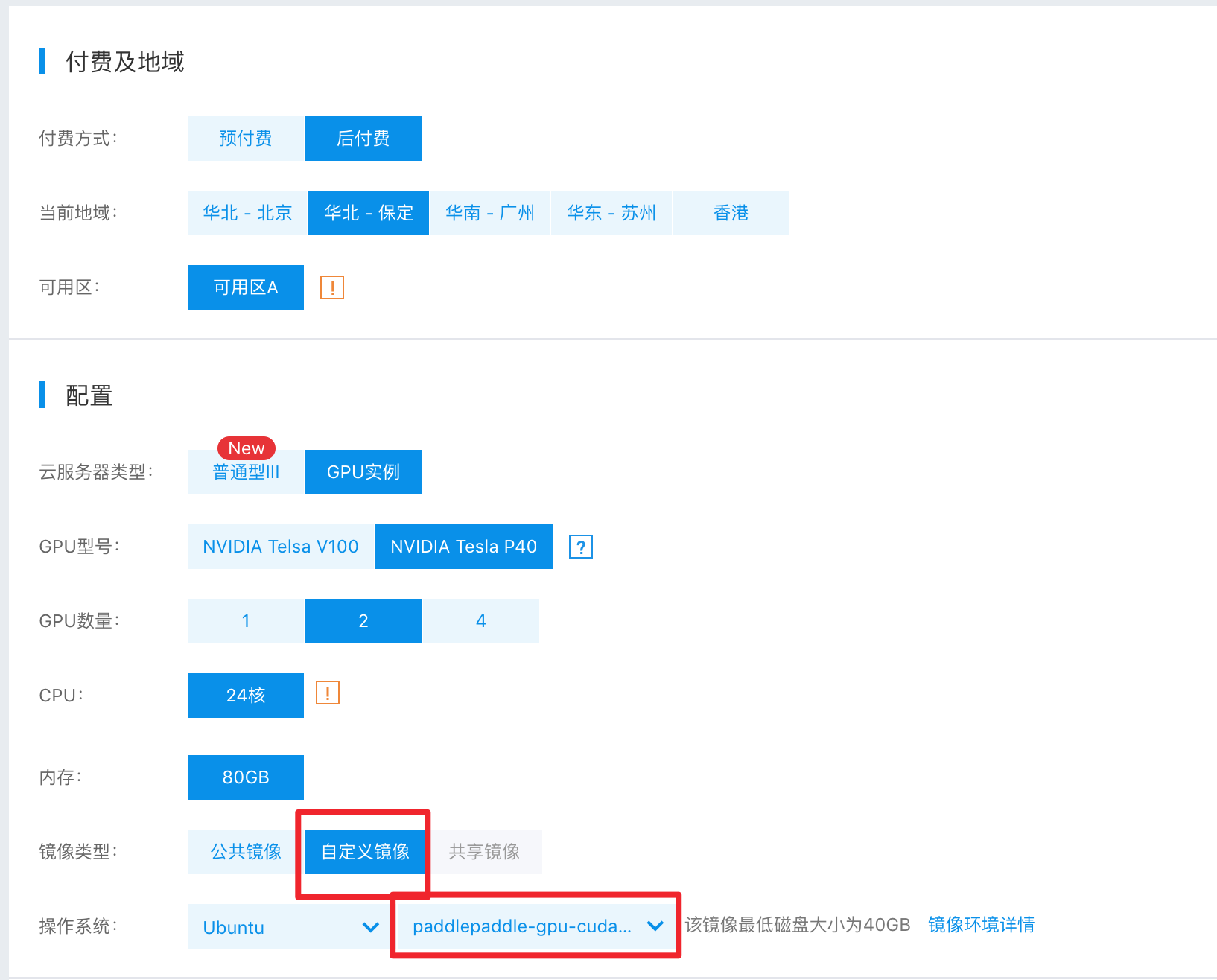
146.2 KB
{kind=link}
{kind=link}
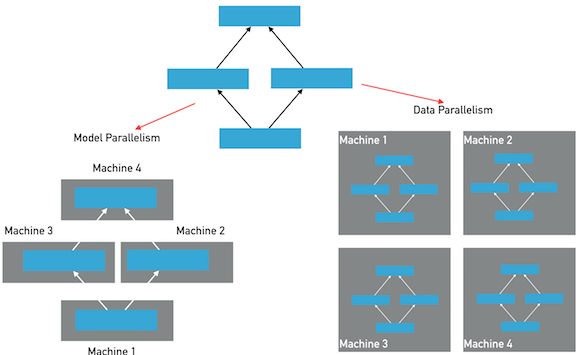
| W: | H:
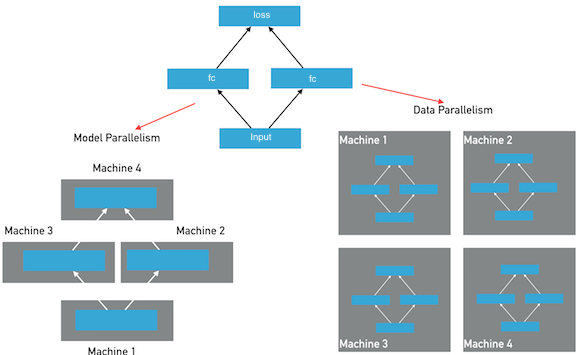
| W: | H:
{kind=link}
209.0 KB
Add train on baidu cloud
182.4 KB
164.0 KB
146.2 KB
| W: | H:
| W: | H:
209.0 KB