Merge branch 'docs/arch' into 'develop'
docs: add architecture See merge request platform/CloudNative4AI/cluster-lifecycle/nervex-operator!28
Showing
docs/architecture-cn.md
0 → 100644
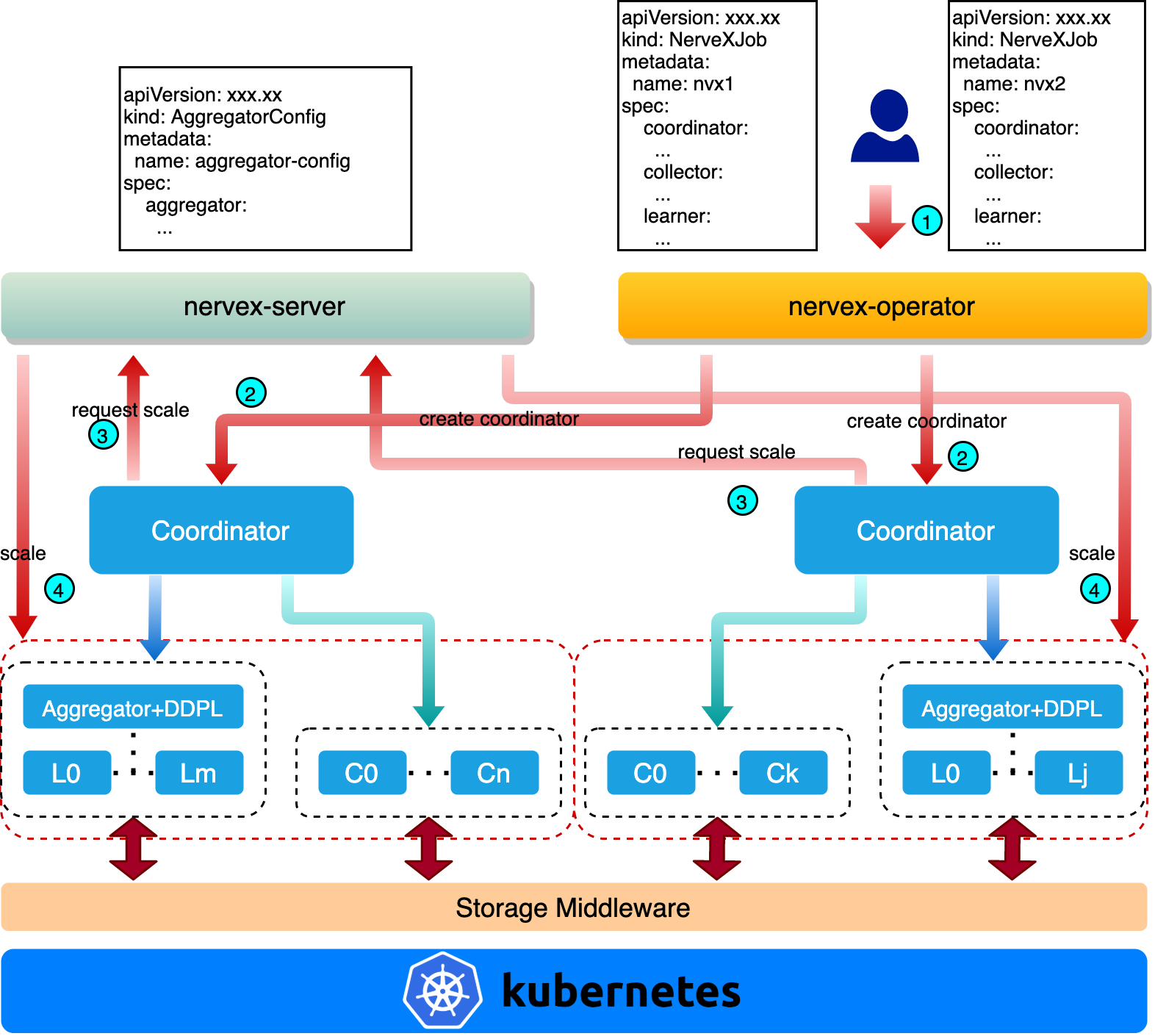
docs/architecture.md
0 → 100644
{kind=link}
109.2 KB
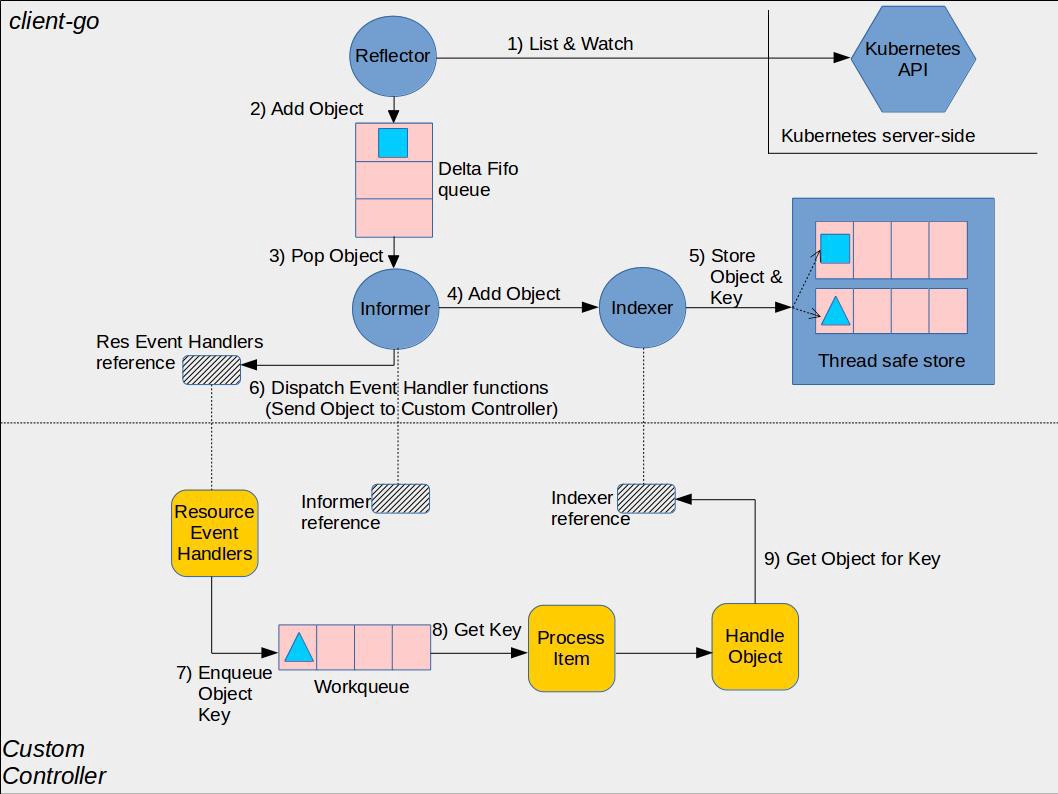
docs/images/nervex-api.png
0 → 100644
{kind=link}
235.0 KB
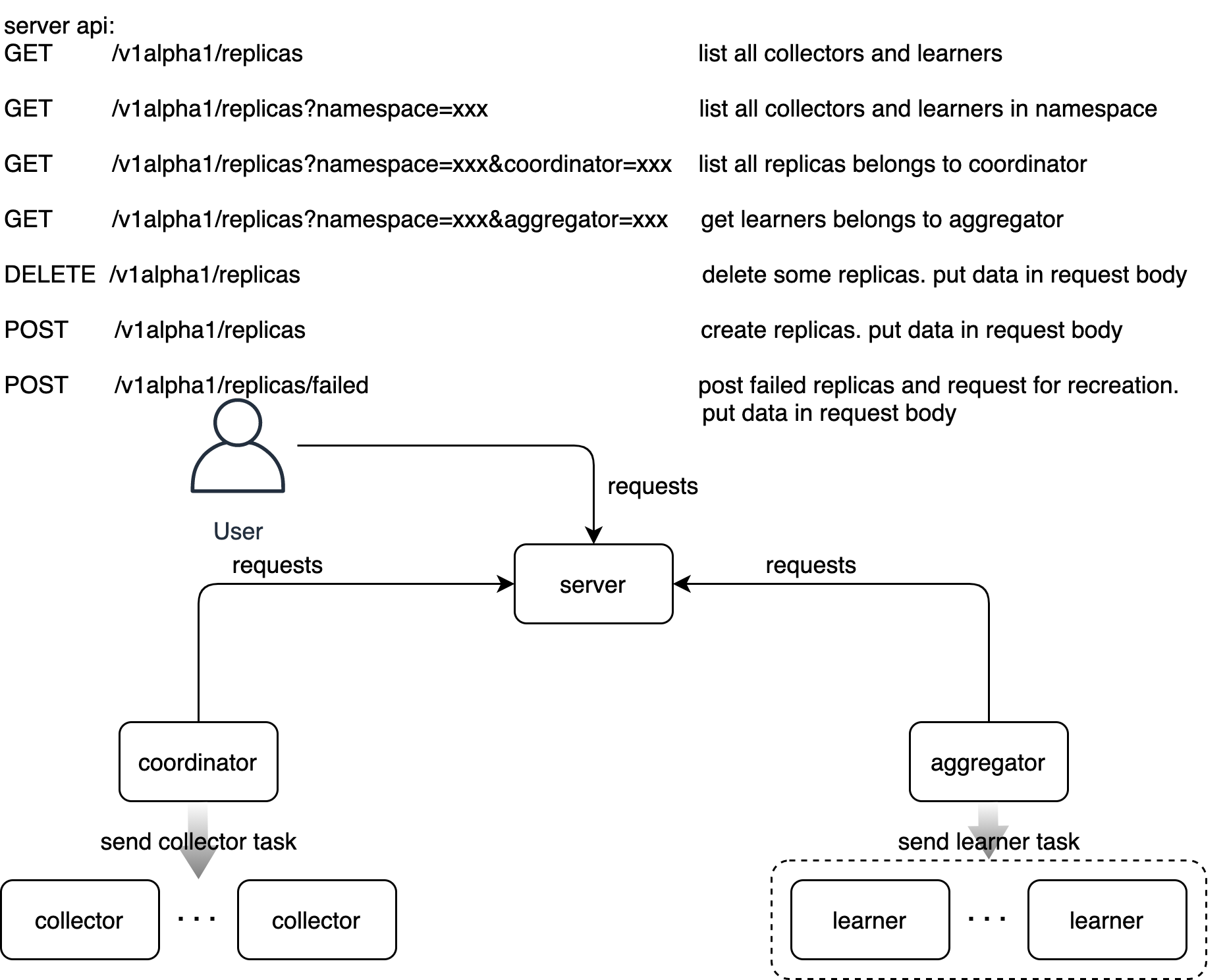
docs/images/nervex-arch.png
0 → 100644
{kind=link}
1.0 MB