
Merge pull request #30 from longdafeng/issue29
fixed #29 add lecture to documents
Showing
docs/lectures/copyright.md
0 → 100644
docs/lectures/images/1-1.png
0 → 100644
{kind=link}
126.3 KB
{kind=link}
1.9 KB
{kind=link}
1.9 KB
docs/lectures/images/2-1.png
0 → 100644
{kind=link}
27.5 KB
docs/lectures/images/2-2.png
0 → 100644
{kind=link}
39.2 KB
docs/lectures/images/2-3.png
0 → 100644
{kind=link}
29.6 KB
docs/lectures/images/2-4.png
0 → 100644
{kind=link}
23.7 KB
docs/lectures/images/2-5.png
0 → 100644
{kind=link}
31.6 KB
docs/lectures/images/2-6.png
0 → 100644
{kind=link}
20.0 KB
docs/lectures/images/2-7.png
0 → 100644
{kind=link}
15.7 KB
docs/lectures/images/2-8.png
0 → 100644
{kind=link}
25.0 KB
docs/lectures/images/3-1.png
0 → 100644
{kind=link}
14.8 KB
docs/lectures/images/3-2-a.png
0 → 100644
{kind=link}
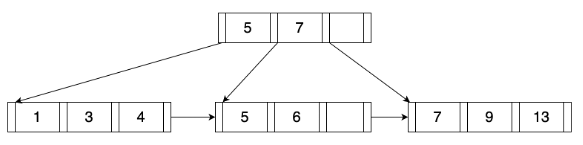
11.1 KB
docs/lectures/images/3-2-b.png
0 → 100644
{kind=link}

18.0 KB
docs/lectures/images/3-2-c.png
0 → 100644
{kind=link}
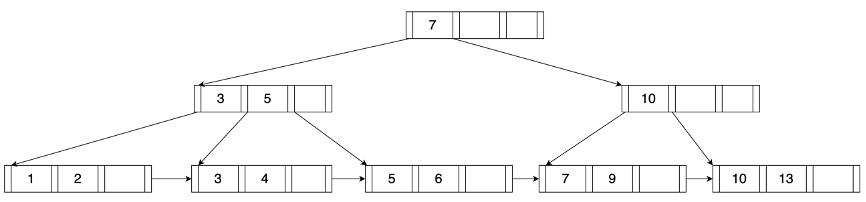
19.5 KB
docs/lectures/images/3-3-a.png
0 → 100644
{kind=link}
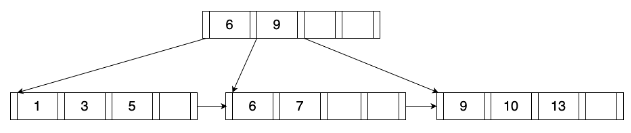
10.2 KB
docs/lectures/images/3-3-b.png
0 → 100644
{kind=link}

20.1 KB
docs/lectures/images/3-3-c.png
0 → 100644
{kind=link}
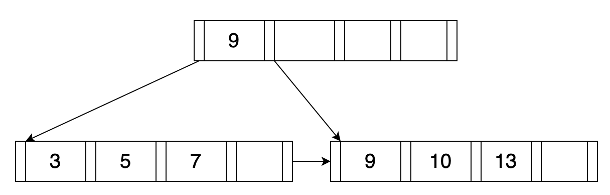
9.8 KB
docs/lectures/images/3-4.png
0 → 100644
{kind=link}

11.8 KB
docs/lectures/images/3-5.png
0 → 100644
{kind=link}
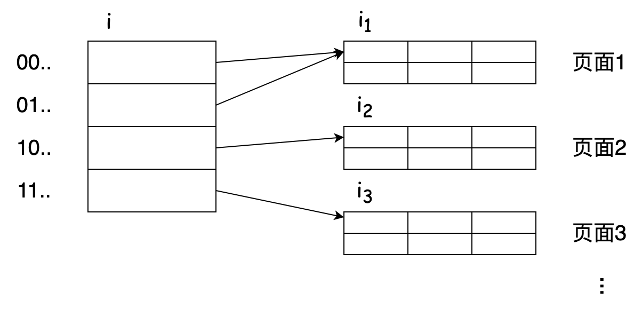
18.2 KB
docs/lectures/images/3-6-a.png
0 → 100644
{kind=link}
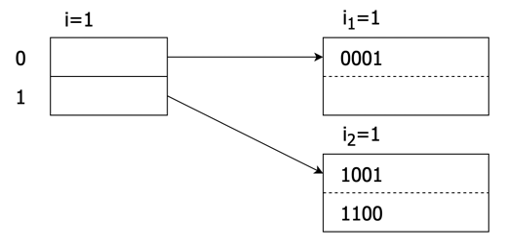
16.3 KB
docs/lectures/images/3-6-b.png
0 → 100644
{kind=link}
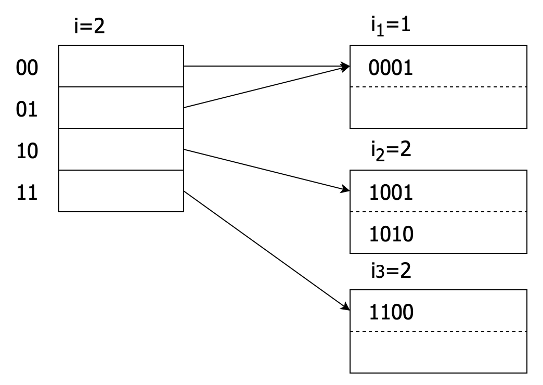
22.0 KB
docs/lectures/images/3-7-a.png
0 → 100644
{kind=link}
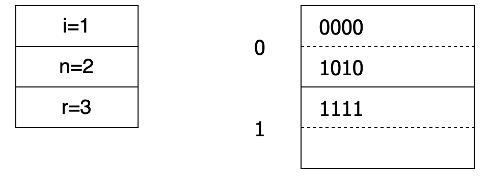
8.2 KB
docs/lectures/images/3-7-b.png
0 → 100644
{kind=link}
13.6 KB
docs/lectures/images/3-7-c.png
0 → 100644
{kind=link}
20.0 KB
docs/lectures/images/4-1.png
0 → 100644
{kind=link}
51.1 KB
docs/lectures/images/4-2.png
0 → 100644
{kind=link}
156.5 KB
docs/lectures/images/4-3.png
0 → 100644
{kind=link}

70.7 KB
docs/lectures/images/4-4.png
0 → 100644
{kind=link}
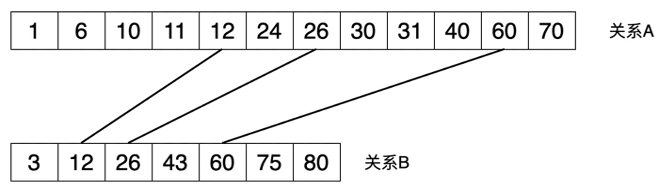
34.6 KB
docs/lectures/images/4-5.png
0 → 100644
{kind=link}
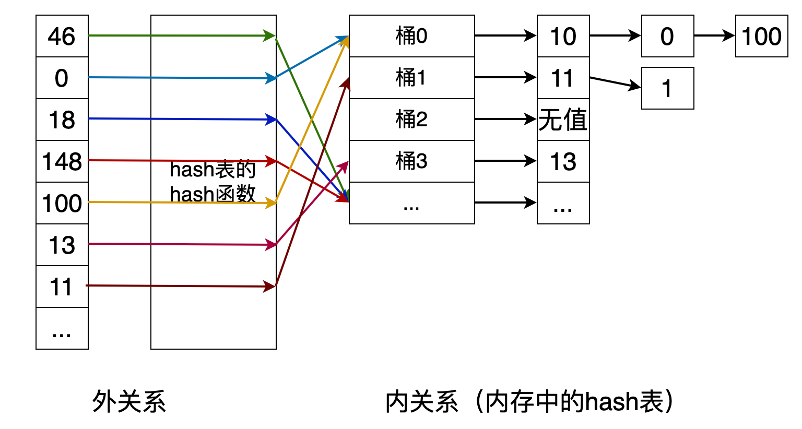
57.2 KB
docs/lectures/images/4-6.png
0 → 100644
{kind=link}
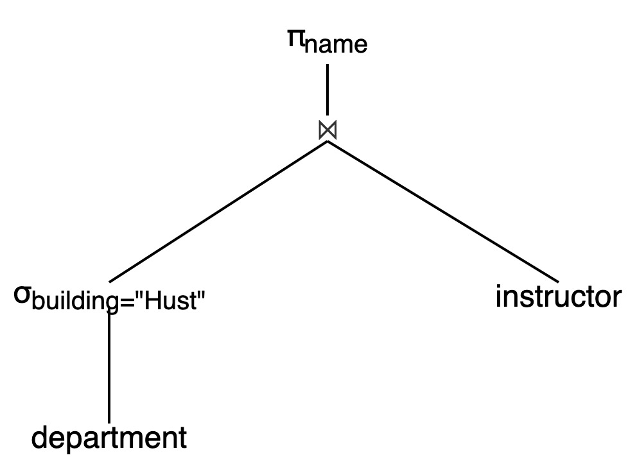
37.3 KB
docs/lectures/images/5-1.png
0 → 100644
{kind=link}
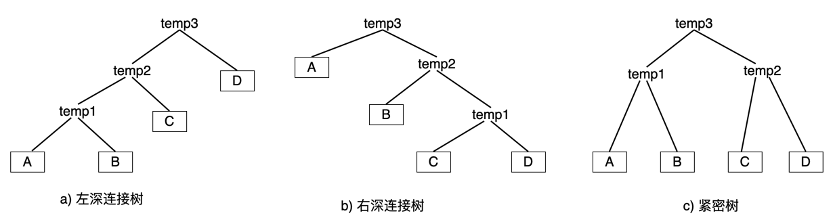
32.8 KB
{kind=link}
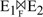
1.4 KB
{kind=link}
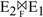
1.3 KB
{kind=link}
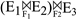
2.6 KB
{kind=link}

3.6 KB
{kind=link}
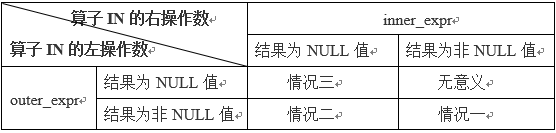
7.7 KB
{kind=link}
2.5 KB
docs/lectures/images/6-1.png
0 → 100644
{kind=link}
28.6 KB
docs/lectures/images/6-2.png
0 → 100644
{kind=link}
24.6 KB
docs/lectures/images/6-3.png
0 → 100644
{kind=link}
62.6 KB
docs/lectures/images/6-4.png
0 → 100644
{kind=link}
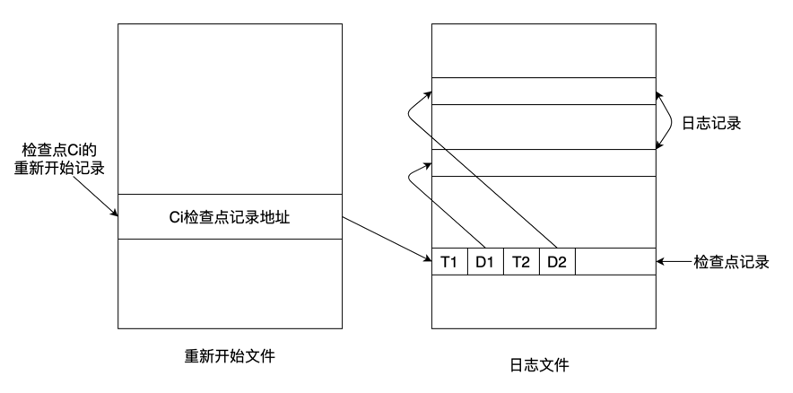
35.5 KB
docs/lectures/index.md
0 → 100644
docs/lectures/lecture-1.md
0 → 100644
docs/lectures/lecture-2.md
0 → 100644
此差异已折叠。
docs/lectures/lecture-3.md
0 → 100644
此差异已折叠。
docs/lectures/lecture-4.md
0 → 100644
docs/lectures/lecture-5.md
0 → 100644
此差异已折叠。
docs/lectures/lecture-6.md
0 → 100644
此差异已折叠。
docs/lectures/references.md
0 → 100644