!856 Add a new markdown
Merge pull request !856 from JunYuLiu/master
Showing
{kind=link}

45.6 KB
{kind=link}
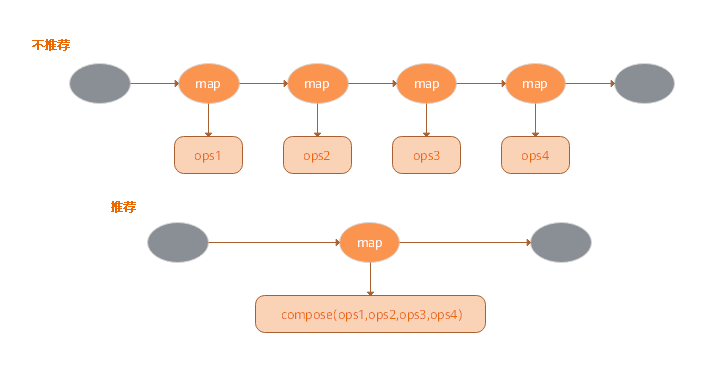
17.4 KB
{kind=link}
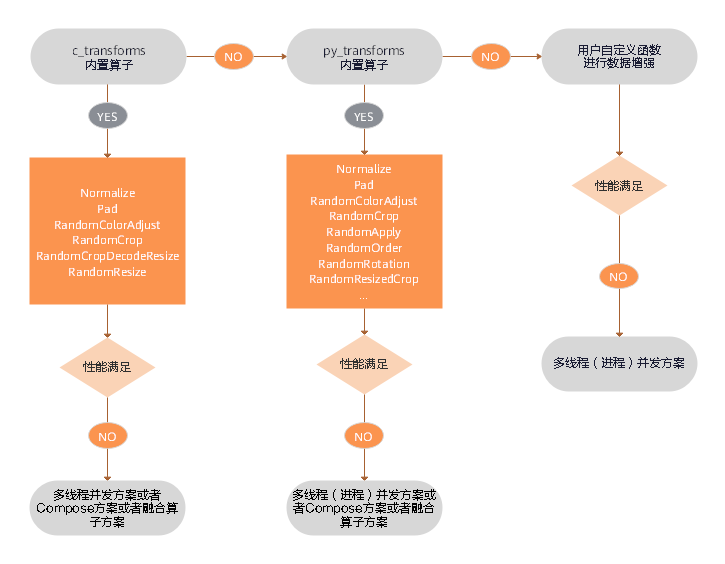
30.8 KB
{kind=link}
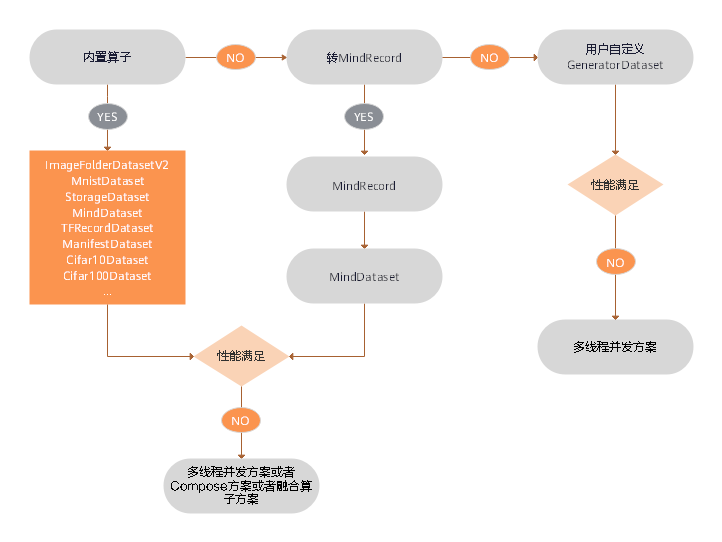
32.3 KB
{kind=link}
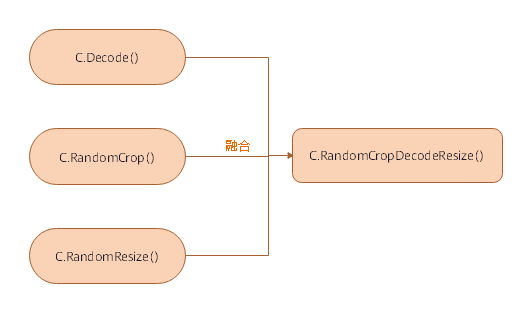
12.8 KB
{kind=link}

5.7 KB
{kind=link}
17.7 KB
Merge pull request !856 from JunYuLiu/master
45.6 KB
17.4 KB
30.8 KB
32.3 KB
12.8 KB
5.7 KB
17.7 KB