Add new mindinsight profiler components
Showing
{kind=link}

78.7 KB
{kind=link}

84.5 KB
{kind=link}

902.7 KB
{kind=link}

556.4 KB
{kind=link}
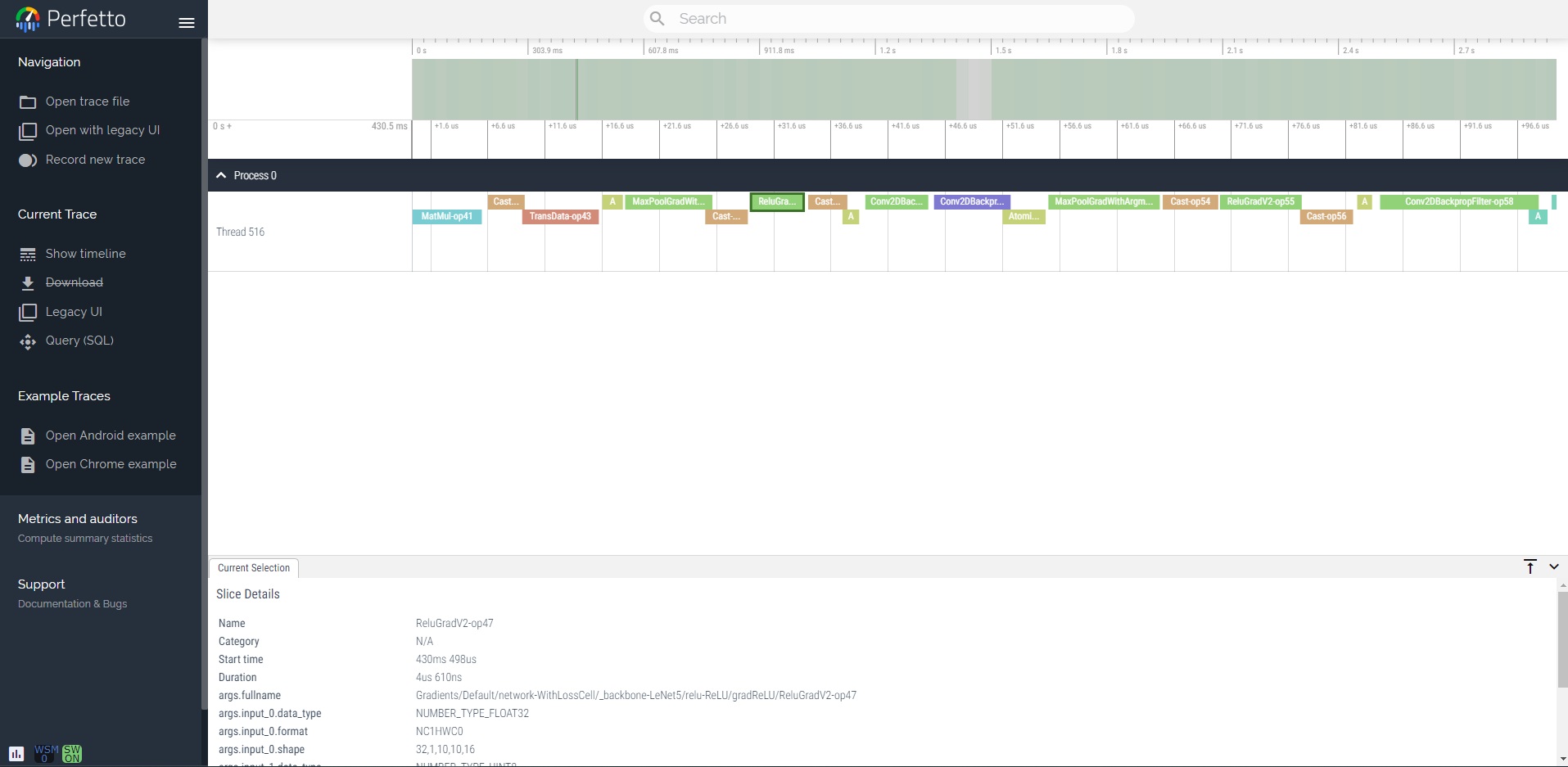
118.8 KB
{kind=link}

78.7 KB
{kind=link}

84.5 KB
{kind=link}

902.7 KB
{kind=link}

556.4 KB
{kind=link}

118.8 KB
78.7 KB
84.5 KB
902.7 KB
556.4 KB
118.8 KB
78.7 KB
84.5 KB
902.7 KB
556.4 KB
118.8 KB