add New data graph and calculation graph
new file: tutorials/notebook/mindinsight/calculate.ipynb new file: tutorials/notebook/mindinsight/datagraphic.ipynb new file: tutorials/notebook/mindinsight/images/001.png new file: tutorials/notebook/mindinsight/images/002.png new file: tutorials/notebook/mindinsight/images/003.png new file: tutorials/notebook/mindinsight/images/004.png new file: tutorials/notebook/mindinsight/images/005.png new file: tutorials/notebook/mindinsight/calculate.ipynb new file: tutorials/notebook/mindinsight/datagraphic.ipynb
Showing
{kind=link}
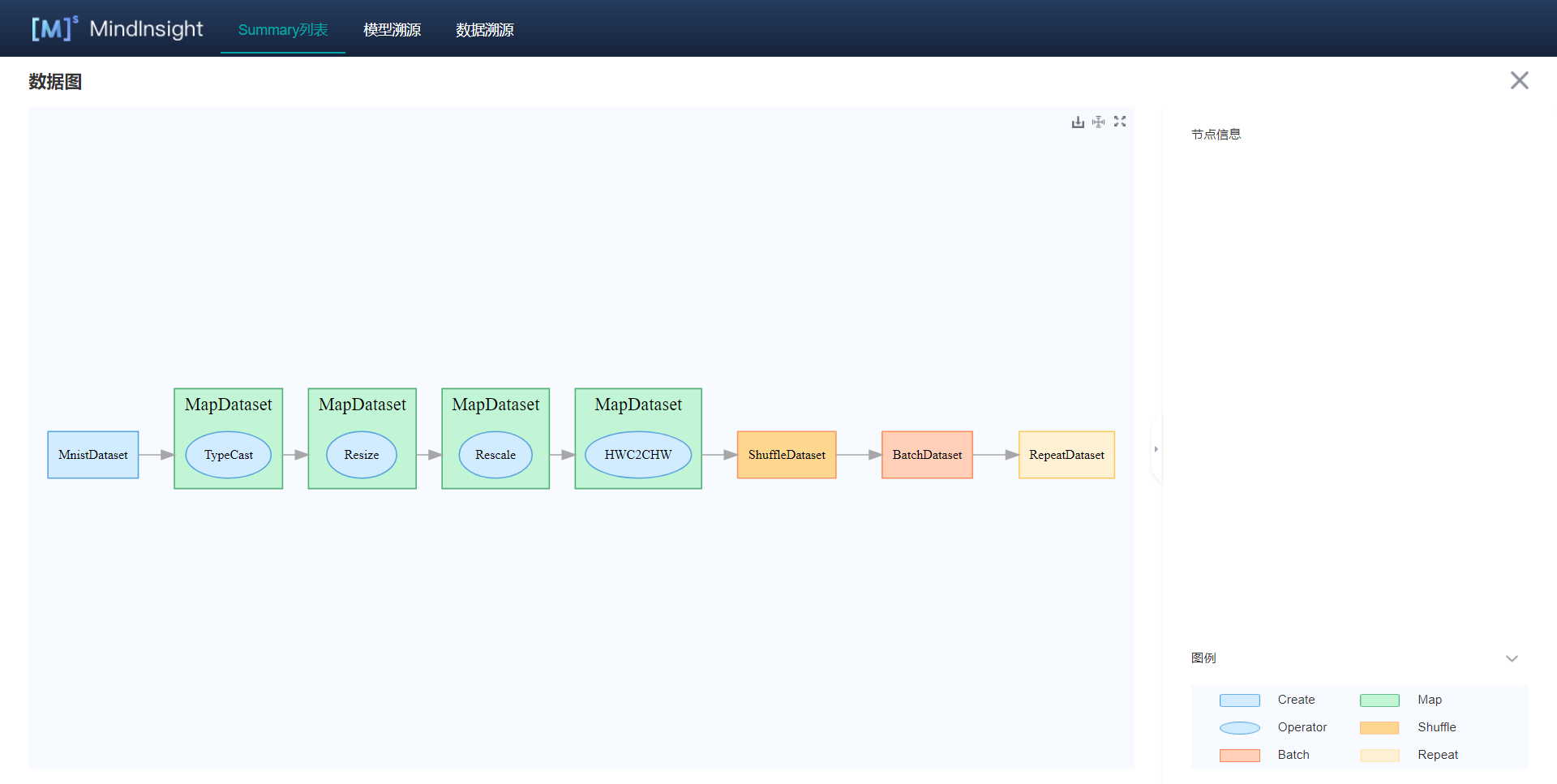
59.4 KB
{kind=link}
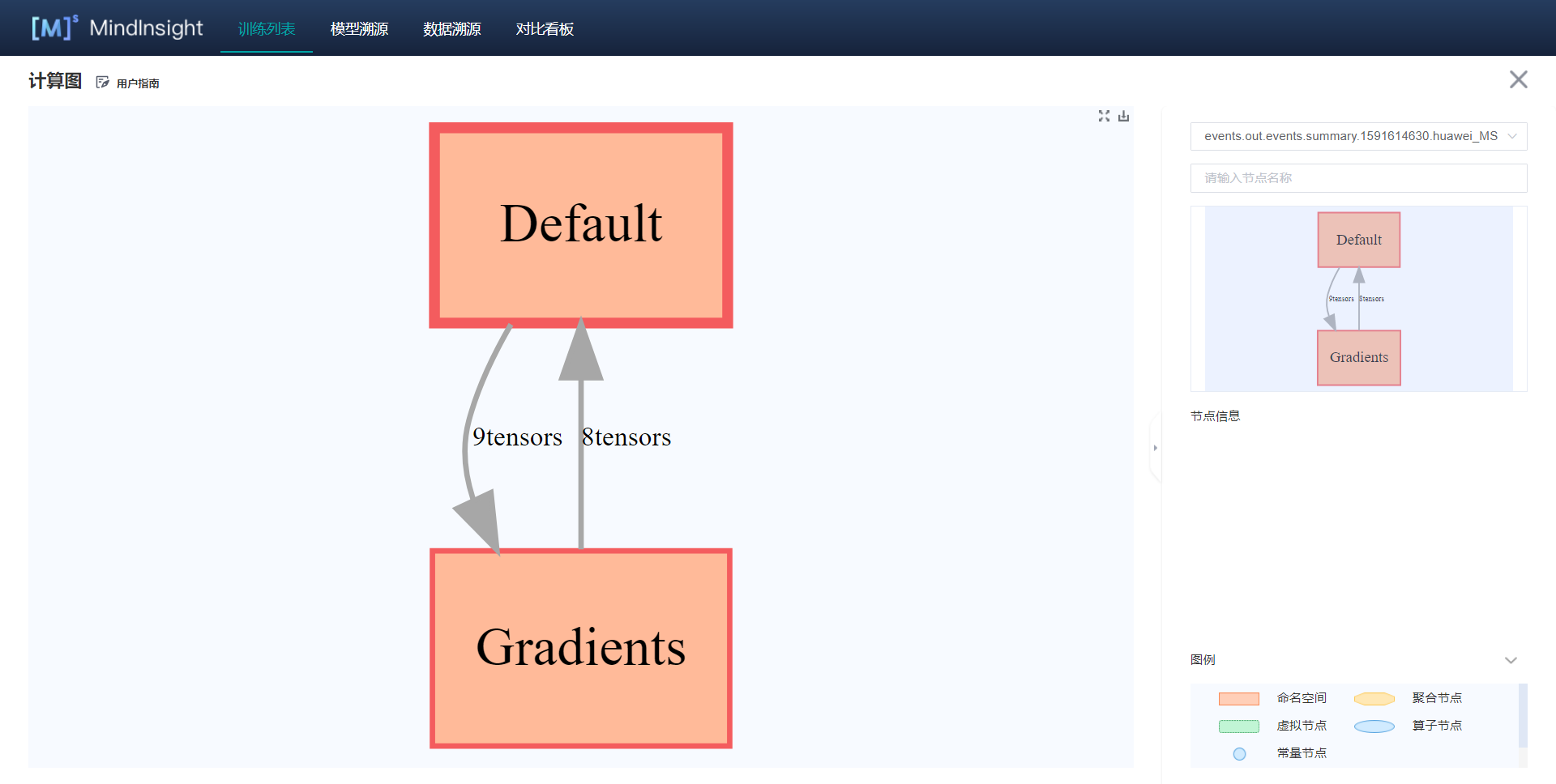
71.6 KB
{kind=link}
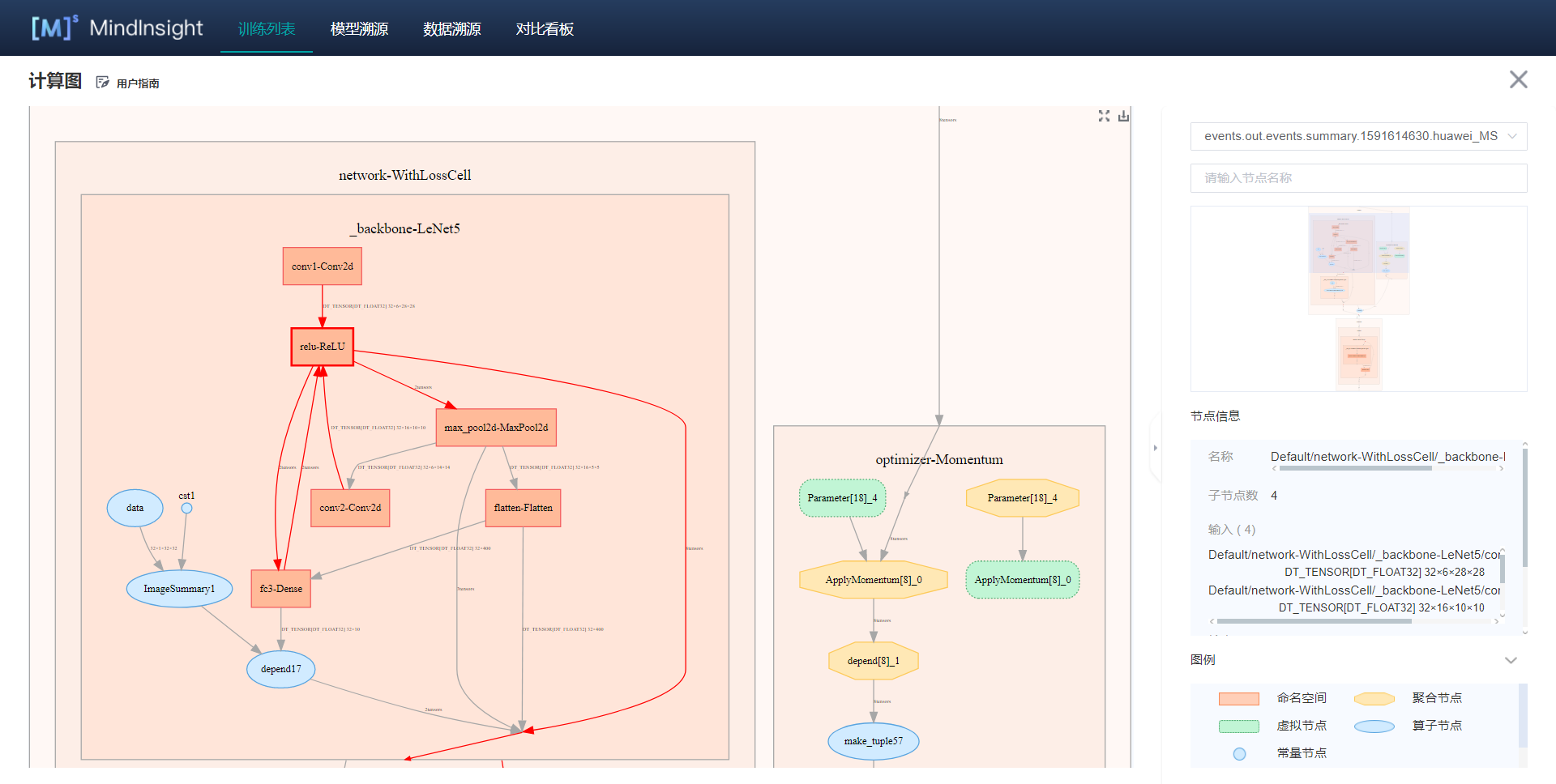
140.7 KB
{kind=link}
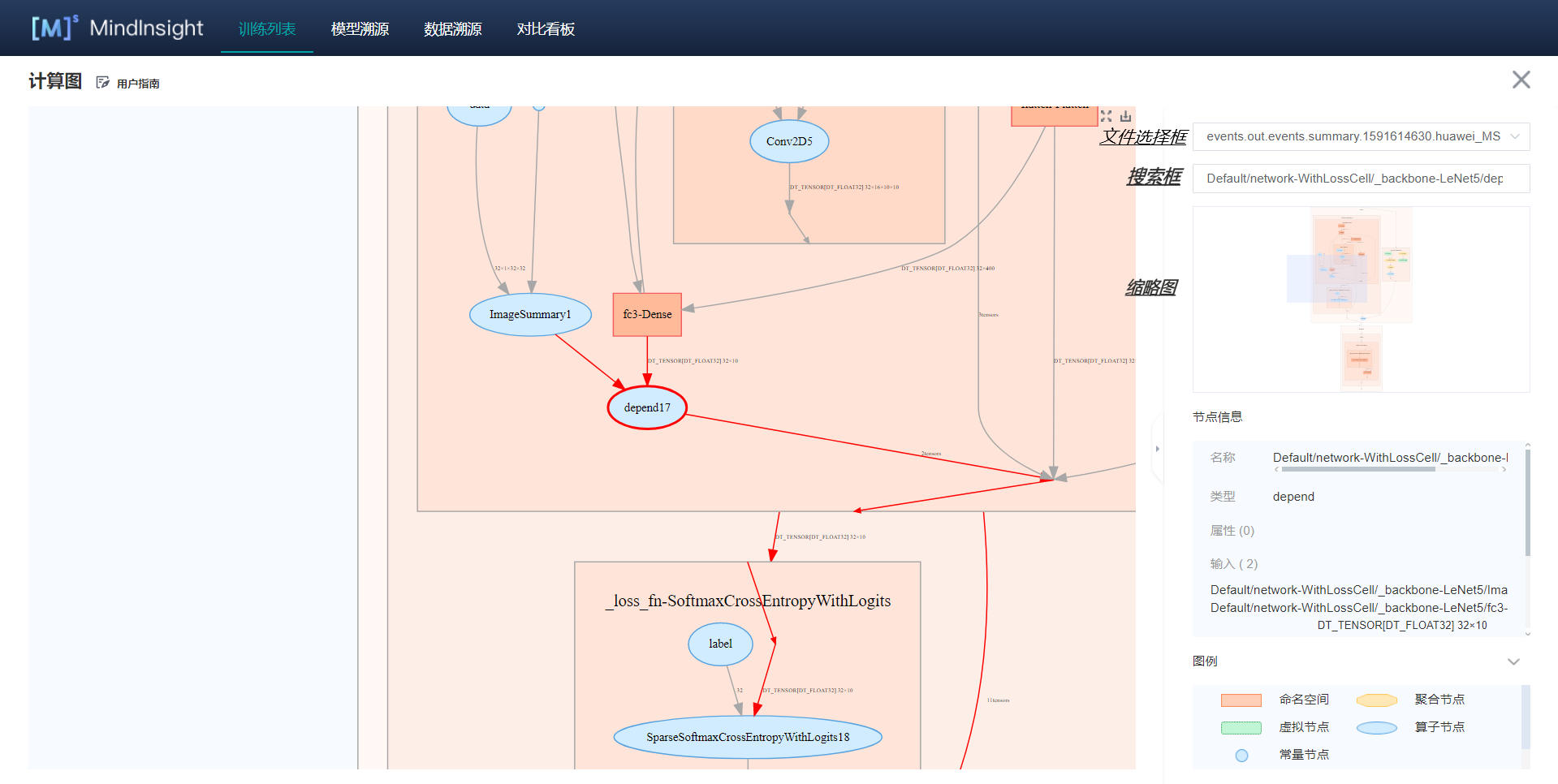
163.0 KB
{kind=link}

31.5 KB