Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
MindSpore
docs
提交
1dba51dd
D
docs
项目概览
MindSpore
/
docs
通知
5
Star
3
Fork
2
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
D
docs
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
提交
1dba51dd
编写于
8月 11, 2020
作者:
M
mindspore-ci-bot
提交者:
Gitee
8月 11, 2020
浏览文件
操作
浏览文件
下载
差异文件
!627 Correct image link, modify tensor notes and image.
Merge pull request !627 from zhangyi/mod_tensor_doc
上级
db8d953a
5737ab54
变更
2
隐藏空白更改
内联
并排
Showing
2 changed file
with
19 addition
and
21 deletion
+19
-21
tutorials/notebook/mindinsight/images/tensor_func.png
tutorials/notebook/mindinsight/images/tensor_func.png
+0
-0
tutorials/notebook/mindinsight/mindinsight_image_histogram_scalar_tensor.ipynb
...ndinsight/mindinsight_image_histogram_scalar_tensor.ipynb
+19
-21
未找到文件。
tutorials/notebook/mindinsight/images/tensor_func.png
查看替换文件 @
db8d953a
浏览文件 @
1dba51dd
5.5 KB
|
W:
|
H:
8.1 KB
|
W:
|
H:
2-up
Swipe
Onion skin
tutorials/notebook/mindinsight/mindinsight_image_histogram_scalar_tensor.ipynb
浏览文件 @
1dba51dd
...
@@ -628,7 +628,7 @@
...
@@ -628,7 +628,7 @@
"\n",
"\n",
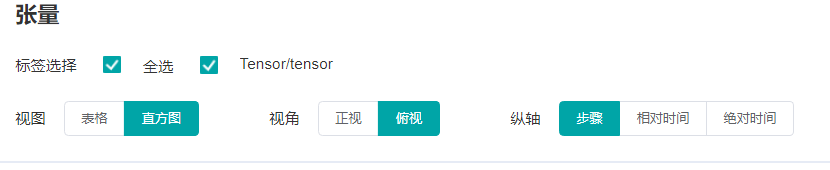
"下图为直方图功能区。\n",
"下图为直方图功能区。\n",
"\n",
"\n",
"\n",
"\n",
"\n",
"\n",
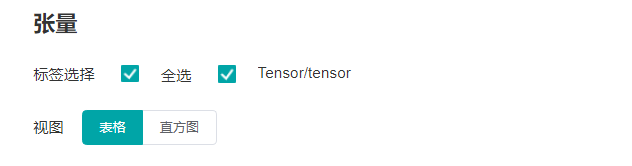
"上图展示直方图的功能区,包含以下内容:\n",
"上图展示直方图的功能区,包含以下内容:\n",
"\n",
"\n",
...
@@ -1219,30 +1219,28 @@
...
@@ -1219,30 +1219,28 @@
"source": [
"source": [
"## 注意事项和规格\n",
"## 注意事项和规格\n",
"\n",
"\n",
"-
为了控制列出summary列表的用时,MindInsight最多支持发现999个summary列表条目
。\n",
"-
在训练中使用Summary算子收集数据时,`HistogramSummary`算子会影响性能,所以请尽量少地使用
。\n",
"- 为了控制内存占用,MindInsight对标签(tag)数目和步骤(step)数目进行了限制:\n",
"- 为了控制内存占用,MindInsight对标签(tag)数目和步骤(step)数目进行了限制:\n",
"\n",
" - 每个训练看板的最大标签数量为300个标签。标量标签、图片标签、计算图标签、参数分布图(直方图)标签、张量标签的数量总和不得超过300个。特别地,每个训练看板最多有10个计算图标签、6个张量标签。当实际标签数量超过这一限制时,将依照MindInsight的处理顺序,保留最近处理的300个标签。\n",
" - 每个训练看板的最大标签数量为300个标签。标量标签、图片标签、计算图标签、参数分布图(直方图)标签的数量总和不得超过300个。特别地,每个训练看板最多有10个计算图标签。当实际标签数量超过这一限制时,将依照MindInsight的处理顺序,保留最近处理的300个标签。\n",
" - 每个训练看板的每个标量标签最多有1000个步骤的数据。当实际步骤的数目超过这一限制时,将对数据进行随机采样,以满足这一限制。\n",
" - 每个训练看板的每个标量标签最多有1000个步骤的数据。当实际步骤的数目超过这一限制时,将对数据进行随机采样,以满足这一限制。\n",
" - 每个训练看板的每个图片标签最多有10个步骤的数据。当实际步骤的数目超过这一限制时,将对数据进行随机采样,以满足这一限制。
\n",
" - 每个训练看板的每个图片标签最多有10个步骤的数据。当实际步骤的数目超过这一限制时,将对数据进行随机采样,以满足这一限制。\n",
" - 每个训练看板的每个参数分布图(直方图)标签最多有50个步骤的数据。当实际步骤的数目超过这一限制时,将对数据进行随机采样,以满足这一限制。\n",
" - 每个训练看板的每个参数分布图(直方图)标签最多有50个步骤的数据。当实际步骤的数目超过这一限制时,将对数据进行随机采样,以满足这一限制。\n",
" \n",
"
- 每个训练看板的每个张量标签最多有20个步骤的数据。当实际步骤的数目超过这一限制时,将对数据进行随机采样,以满足这一限制。
\n",
"- 出于性能上的考虑,MindInsight对比看板使用缓存机制加载训练的标量曲线数据,并进行以下限制:\n",
"- 出于性能上的考虑,MindInsight对比看板使用缓存机制加载训练的标量曲线数据,并进行以下限制:\n",
" \n",
" - 对比看板只支持在缓存中的训练进行比较标量曲线对比。\n",
" - 对比看板只支持在缓存中的训练进行比较标量曲线对比。 \n",
" - 缓存最多保留最新(按修改时间排列)的15个训练。\n",
" - 缓存最多保留最新(按修改时间排列)的15个训练。 \n",
" - 用户最多同时对比5个训练的标量曲线。\n",
" - 用户最多同时对比5个训练的标量曲线。\n",
"
\n",
"
- 由于`TensorSummary`会记录完整Tensor数据,数据量通常会比较大,为了控制内存占用和出于性能上的考虑,MindInsight对Tensor的大小以及返回前端展示的数值个数进行以下限制:
\n",
"
- 由于张量可视(`TensorSummary`)会记录原始张量数据,需要的存储空间较大。使用`TensorSummary`前和训练过程中请注意检查系统存储空间充足。 通过以下方法可以降低张量可视功能的存储空间占用:
\n",
"
- MindInsight最大支持加载含有1千万个数值的Tensor。
\n",
"\n",
"
- Tensor加载后,在张量可视的表格视图下,最大支持查看10万个数值,如果所选择的维度查询得到的数值超过这一限制,则无法显示。
\n",
"
- 避免使用`TensorSummary`记录较大的Tensor。
\n",
"
- 由于张量可视(`TensorSummary`)会记录原始张量数据,需要的存储空间较大。使用`TensorSummary`前和训练过程中请注意检查系统存储空间充足。 通过以下方法可以降低张量可视功能的存储空间占用:\\
\n",
"
- 减少网络中`TensorSummary`算子的使用个数。
\n",
"
  1)避免使用`TensorSummary`记录较大的Tensor。\\
\n",
"
- 功能使用完毕后,请及时清理不再需要的训练日志,以释放磁盘空间
。\n",
"
  2)减少网络中`TensorSummary`算子的使用个数
。\n",
"\n",
"
- 功能使用完毕后,请及时清理不再需要的训练日志,以释放磁盘空间。
\n",
"
备注:估算`TensorSummary`空间使用量的方法如下:
\n",
"\n",
"\n",
"
- 备注:估算`TensorSummary`空间使用量的方法如下:
\n",
"
- 一个T`ensorSummary`数据的大小 = Tensor中的数值个数 * 4 bytes。假设使用`TensorSummary`记录的Tensor大小为32 * 1 * 256 * 256,则一个TensorSummary数据大约需要32 * 1 * 256 * 256 * 4 bytes = 8,388,608 bytes = 8MiB。又假设SummaryCollector
的`collect_freq`设置为1,且训练了50个迭代。则记录这50组数据需要的空间约为50 * 8 MiB = 400MiB。需要注意的是,由于数据结构等因素的开销,实际使用的存储空间会略大于400MiB。\n",
"
- 一个`TensorSummary`数据的大小 = Tensor中的数值个数 * 4 bytes。假设使用`TensorSummary`记录的Tensor大小为32 * 1 * 256 * 256,则一个`TensorSummary`数据大约需要32 * 1 * 256 * 256 * 4 bytes = 8,388,608 bytes = 8MiB。又假设`SummaryCollector`
的`collect_freq`设置为1,且训练了50个迭代。则记录这50组数据需要的空间约为50 * 8 MiB = 400MiB。需要注意的是,由于数据结构等因素的开销,实际使用的存储空间会略大于400MiB。\n",
"- 当使用`TensorSummary`时,由于记录完整Tensor数据,训练日志文件较大,MindInsight需要更多时间解析训练日志文件,请耐心等待。"
"
- 当使用`TensorSummary`时,由于记录完整Tensor数据,训练日志文件较大,MindInsight需要更多时间解析训练日志文件,请耐心等待。"
]
]
},
},
{
{
...
@@ -1278,4 +1276,4 @@
...
@@ -1278,4 +1276,4 @@
},
},
"nbformat": 4,
"nbformat": 4,
"nbformat_minor": 4
"nbformat_minor": 4
}
}
\ No newline at end of file
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}