initial version
上级
Showing
.gitee/PULL_REQUEST_TEMPLATE.md
0 → 100644
.gitignore
0 → 100644
CONTRIBUTING_DOC.md
0 → 100644
LICENSE
0 → 100644
LICENSE-CC-BY-4.0
0 → 100644
NOTICE
0 → 100644
README.md
0 → 100644
api/Makefile
0 → 100644
api/numpy_objects.inv
0 → 100644
文件已添加
api/python_objects.inv
0 → 100644
文件已添加
api/requirements.txt
0 → 100644
api/run.sh
0 → 100644
api/source_en/conf.py
0 → 100644
api/source_en/index.rst
0 → 100644
api/source_zh_cn/conf.py
0 → 100644
api/source_zh_cn/index.rst
0 → 100644
docs/Makefile
0 → 100644
docs/requirements.txt
0 → 100644
docs/source_en/architecture.md
0 → 100644
docs/source_en/conf.py
0 → 100644
docs/source_en/glossary.md
0 → 100644
文件已添加
{kind=link}

40.0 KB
docs/source_en/index.rst
0 → 100644
docs/source_en/operator_list.md
0 → 100644
此差异已折叠。
docs/source_en/roadmap.md
0 → 100644
docs/source_zh_cn/architecture.md
0 → 100644
docs/source_zh_cn/conf.py
0 → 100644
docs/source_zh_cn/glossary.md
0 → 100644
文件已添加
{kind=link}
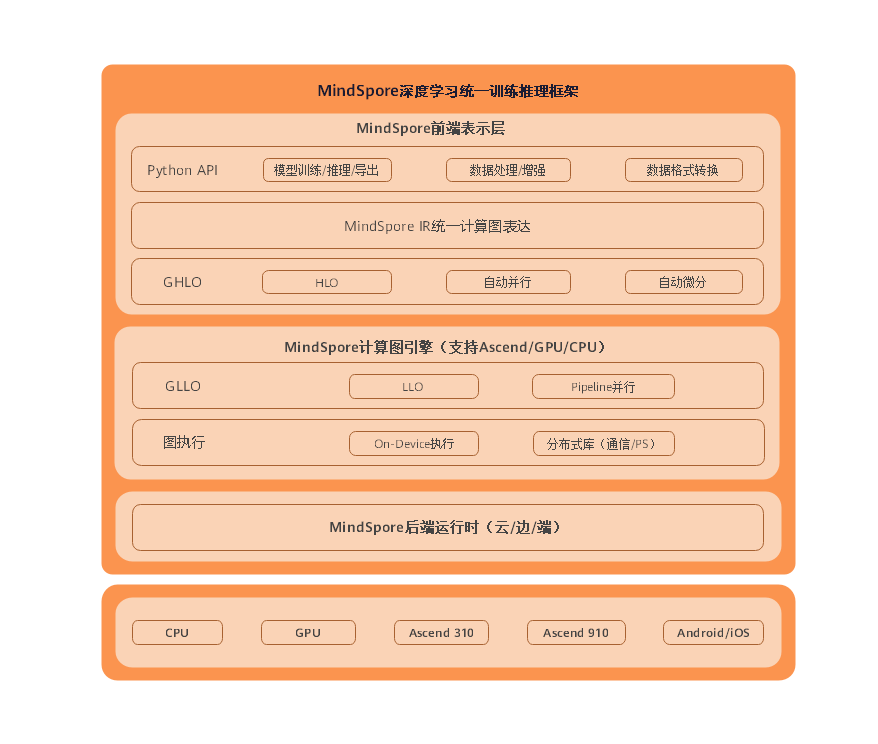
34.3 KB
docs/source_zh_cn/index.rst
0 → 100644
此差异已折叠。
docs/source_zh_cn/roadmap.md
0 → 100644
install/mindspore_cpu_install.md
0 → 100644
install/mindspore_d_install.md
0 → 100644
install/mindspore_d_install_en.md
0 → 100644
install/mindspore_gpu_install.md
0 → 100644
resource/MindSpore-logo.png
0 → 100644
{kind=link}
12.6 KB
resource/jieba.txt
0 → 100644
tutorials/Makefile
0 → 100644
tutorials/requirements.txt
0 → 100644
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tutorials/source_en/conf.py
0 → 100644
此差异已折叠。
tutorials/source_en/index.rst
0 → 100644
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
tutorials/source_zh_cn/conf.py
0 → 100644
此差异已折叠。
tutorials/source_zh_cn/index.rst
0 → 100644
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
tutorials/tutorial_code/lenet.py
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。