Merge pull request #349 from loopyme/master
用户指南更新完成
Showing
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs/29.md
0 → 100644
docs/30.md
0 → 100644
此差异已折叠。
docs/31.md
0 → 100644
docs/32.md
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs/41.md
0 → 100644
此差异已折叠。
docs/47.md
0 → 100644
此差异已折叠。
此差异已折叠。
docs/56.md
已删除
100644 → 0
此差异已折叠。
docs/57.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
docs/65.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs/img/3-5-001.png
0 → 100644
{kind=link}
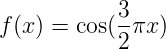
1.0 KB
{kind=link}
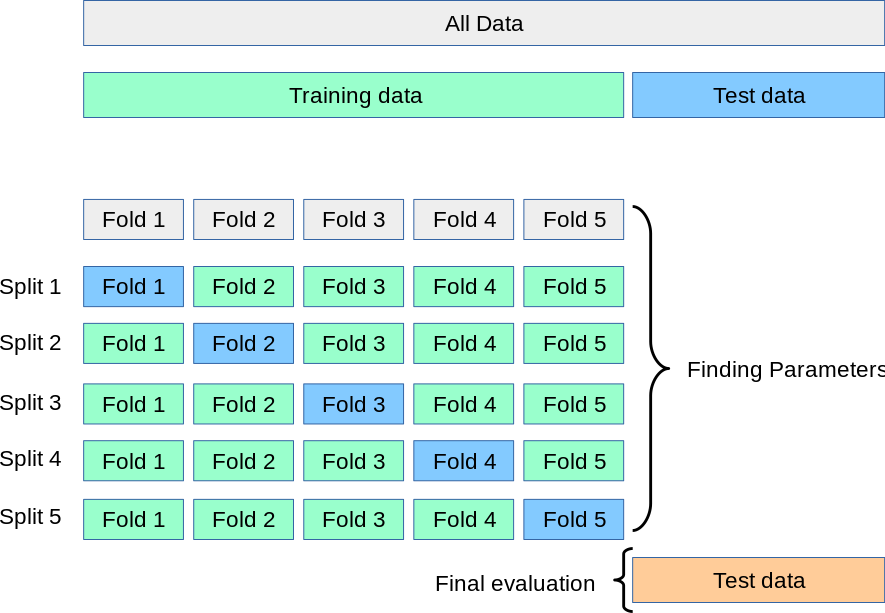
44.1 KB
docs/img/grid_search_workflow.png
0 → 100644
{kind=link}
此差异已折叠。
docs/img/preprocessing001.png
0 → 100644
{kind=link}
此差异已折叠。
docs/img/preprocessing002.png
0 → 100644
{kind=link}
此差异已折叠。
docs/img/projection001.png
0 → 100644
{kind=link}
此差异已折叠。
docs/img/projection002.png
0 → 100644
{kind=link}
此差异已折叠。
docs/img/score001.png
0 → 100644
{kind=link}
此差异已折叠。
docs/img/score002.png
0 → 100644
{kind=link}
此差异已折叠。
docs/img/score003.png
0 → 100644
{kind=link}
此差异已折叠。
docs/img/score004.png
0 → 100644
{kind=link}
此差异已折叠。
docs/img/score005.png
0 → 100644
{kind=link}
此差异已折叠。
docs/img/score006.png
0 → 100644
{kind=link}
此差异已折叠。
docs/img/score007.png
0 → 100644
{kind=link}
此差异已折叠。
docs/img/score008.png
0 → 100644
{kind=link}
此差异已折叠。
docs/img/score009.png
0 → 100644
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。