Merge pull request #348 from loopyme/master
更新调整1,2章
Showing
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs/img/cluster01.png
0 → 100644
{kind=link}
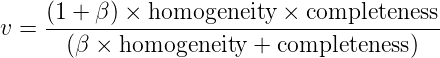
2.7 KB
{kind=link}
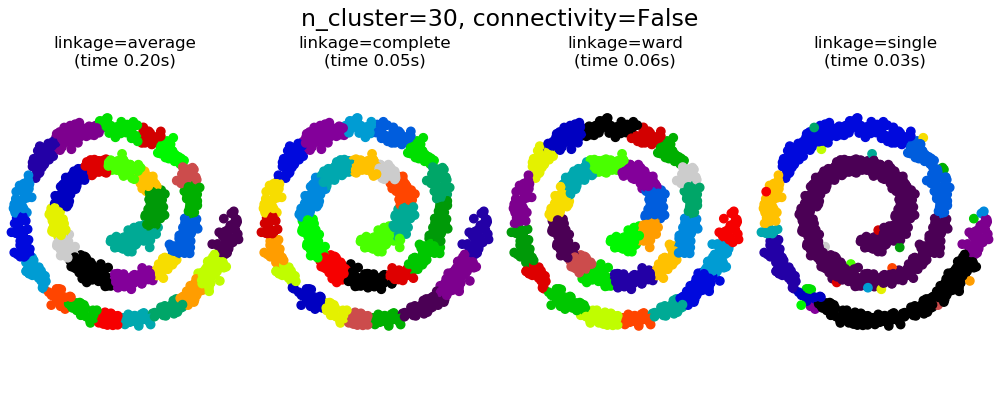
108.2 KB
{kind=link}

75.8 KB
{kind=link}
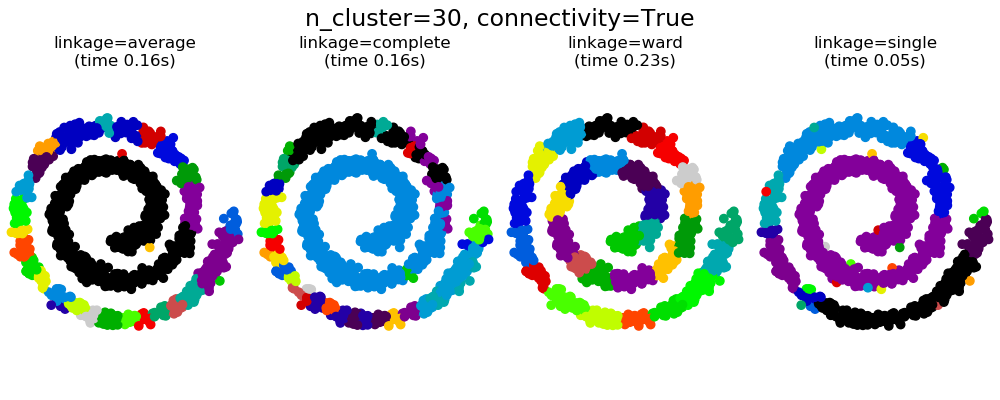
108.8 KB
{kind=link}
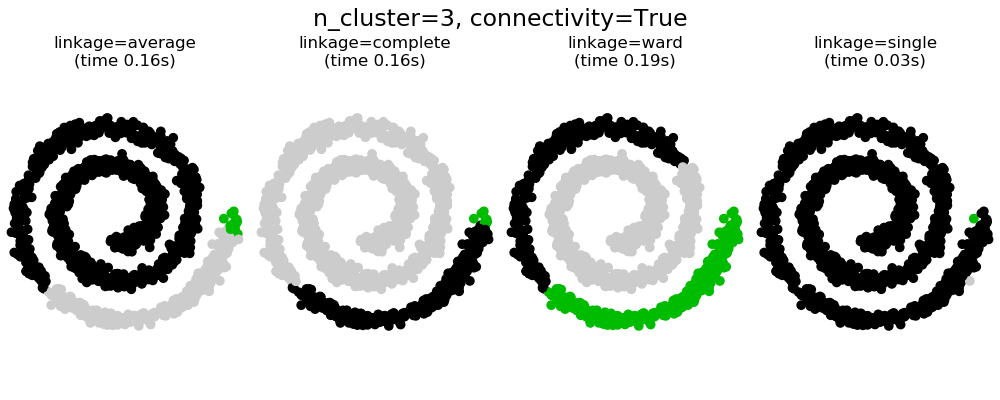
71.9 KB
{kind=link}
427.4 KB
{kind=link}
640.6 KB
{kind=link}
55.6 KB
{kind=link}
46.9 KB
{kind=link}
133.5 KB