fix bug on train_pytorch_ch7
Showing
{kind=link}
{kind=link}
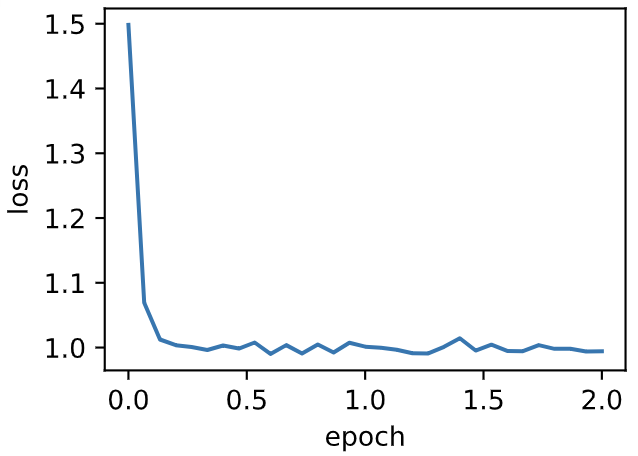
| W: | H:
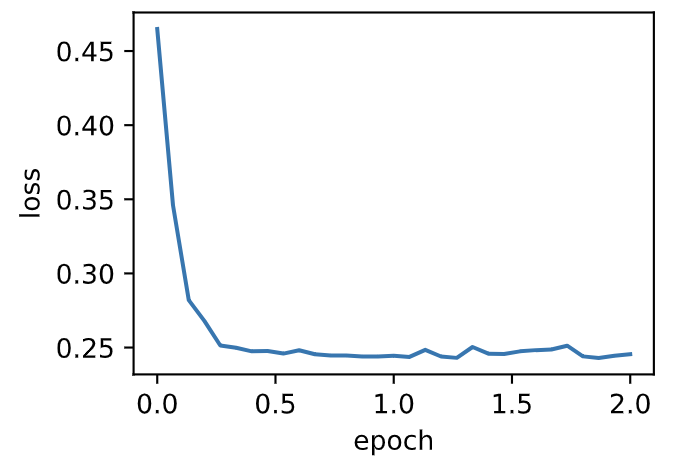
| W: | H:
{kind=link}
{kind=link}
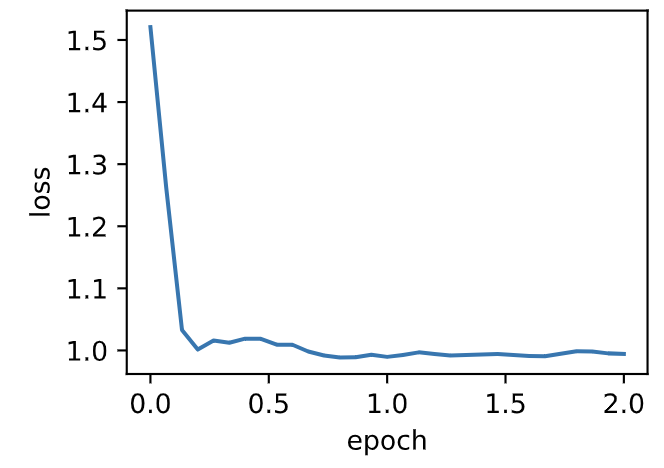
| W: | H:
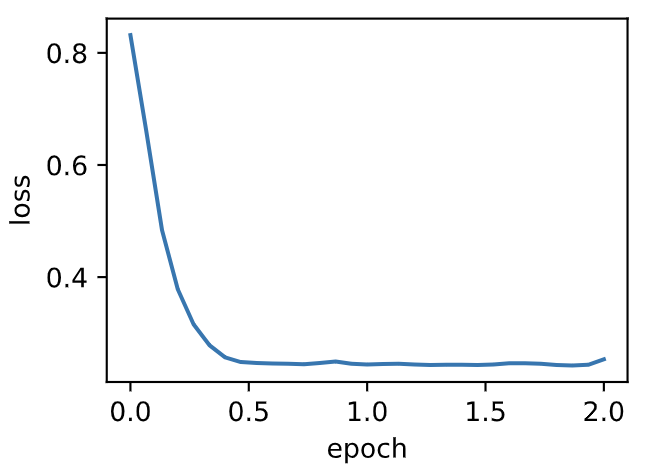
| W: | H:
{kind=link}
{kind=link}
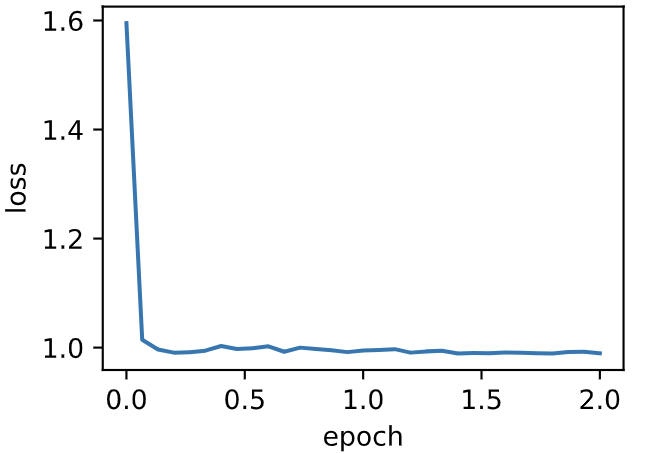
| W: | H:
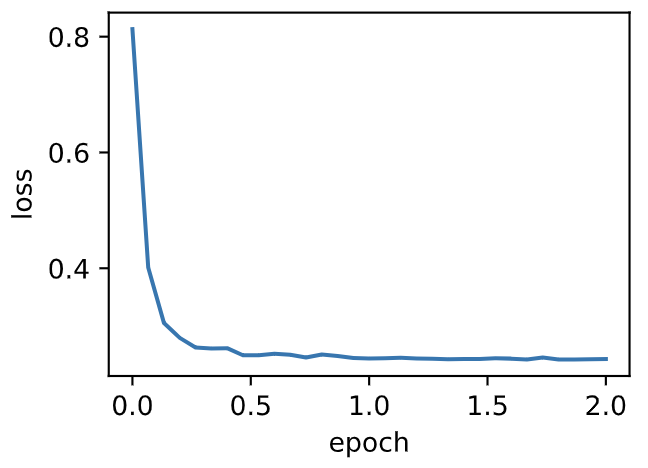
| W: | H:
{kind=link}
{kind=link}
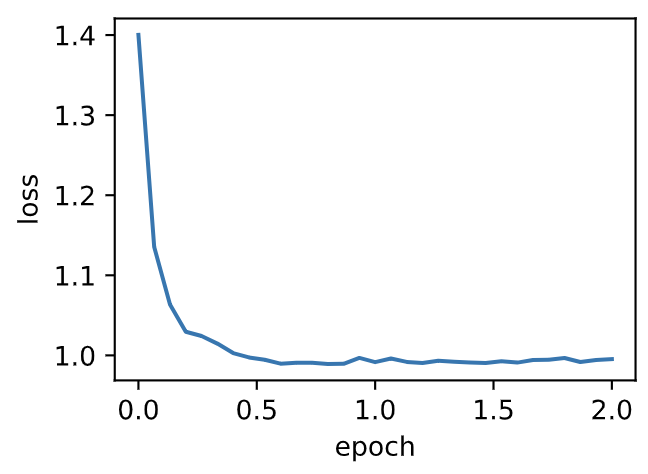
| W: | H:
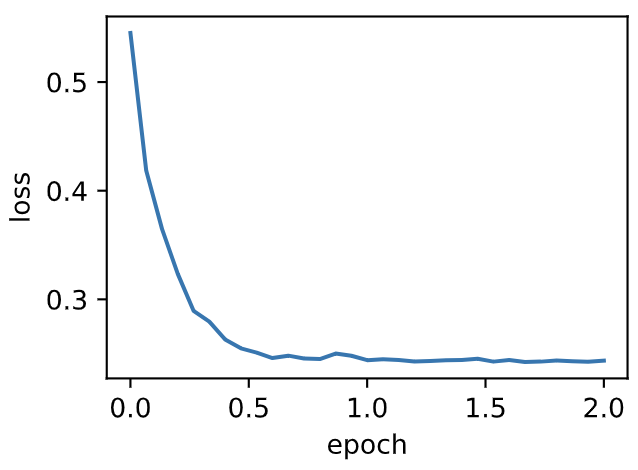
| W: | H:
{kind=link}
{kind=link}
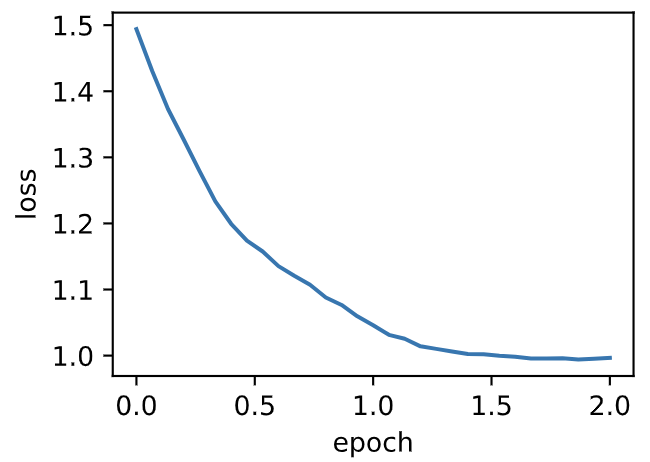
| W: | H:
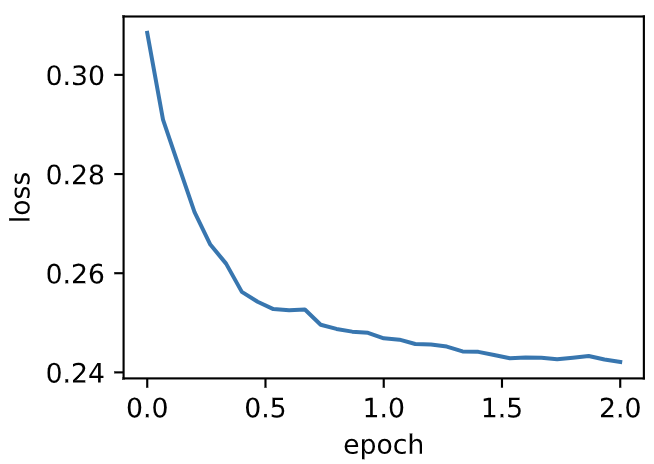
| W: | H:
| W: | H:
| W: | H:
| W: | H:
| W: | H:
| W: | H:
| W: | H:
| W: | H:
| W: | H:
| W: | H:
| W: | H: