Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
OpenDocCN
Dive-into-DL-PyTorch
提交
23ffe9e8
D
Dive-into-DL-PyTorch
项目概览
OpenDocCN
/
Dive-into-DL-PyTorch
通知
9
Star
2
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
D
Dive-into-DL-PyTorch
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
23ffe9e8
编写于
4月 29, 2019
作者:
S
ShusenTang
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
add 7.8
上级
871833e2
变更
5
展开全部
隐藏空白更改
内联
并排
Showing
5 changed file
with
1437 addition
and
2 deletion
+1437
-2
code/chapter07_optimization/7.8_adam.ipynb
code/chapter07_optimization/7.8_adam.ipynb
+1330
-0
code/d2lzh_pytorch/utils.py
code/d2lzh_pytorch/utils.py
+3
-2
docs/chapter07_optimization/7.8_adam.md
docs/chapter07_optimization/7.8_adam.md
+104
-0
img/chapter07/7.8_output1.png
img/chapter07/7.8_output1.png
+0
-0
img/chapter07/7.8_output2.png
img/chapter07/7.8_output2.png
+0
-0
未找到文件。
code/chapter07_optimization/7.8_adam.ipynb
0 → 100644
浏览文件 @
23ffe9e8
此差异已折叠。
点击以展开。
code/d2lzh_pytorch/utils.py
浏览文件 @
23ffe9e8
...
...
@@ -611,7 +611,7 @@ def train_pytorch_ch7(optimizer_fn, optimizer_hyperparams, features, labels,
optimizer
=
optimizer_fn
(
net
.
parameters
(),
**
optimizer_hyperparams
)
def
eval_loss
():
return
loss
(
net
(
features
)
,
labels
).
mean
().
item
()
return
loss
(
net
(
features
)
.
view
(
-
1
),
labels
).
item
()
/
2
ls
=
[
eval_loss
()]
data_iter
=
torch
.
utils
.
data
.
DataLoader
(
...
...
@@ -620,7 +620,8 @@ def train_pytorch_ch7(optimizer_fn, optimizer_hyperparams, features, labels,
for
_
in
range
(
num_epochs
):
start
=
time
.
time
()
for
batch_i
,
(
X
,
y
)
in
enumerate
(
data_iter
):
l
=
loss
(
net
(
X
),
y
)
# 除以2是为了和train_ch7保持一致, 因为squared_loss中除了2
l
=
loss
(
net
(
X
).
view
(
-
1
),
y
)
/
2
optimizer
.
zero_grad
()
l
.
backward
()
...
...
docs/chapter07_optimization/7.8_adam.md
0 → 100644
浏览文件 @
23ffe9e8
# 7.8 Adam算法
Adam算法在RMSProp算法基础上对小批量随机梯度也做了指数加权移动平均 [1]。下面我们来介绍这个算法。
> 所以Adam算法可以看做是RMSProp算法与动量法的结合。
## 7.8.1 算法
Adam算法使用了动量变量$
\b
oldsymbol{v}_t$和RMSProp算法中小批量随机梯度按元素平方的指数加权移动平均变量$
\b
oldsymbol{s}_t$,并在时间步0将它们中每个元素初始化为0。给定超参数$0
\l
eq
\b
eta_1 < 1$(算法作者建议设为0.9),时间步$t$的动量变量$
\b
oldsymbol{v}_t$即小批量随机梯度$
\b
oldsymbol{g}_t$的指数加权移动平均:
$$
\b
oldsymbol{v}_t
\l
eftarrow
\b
eta_1
\b
oldsymbol{v}_{t-1} + (1 -
\b
eta_1)
\b
oldsymbol{g}_t. $$
和RMSProp算法中一样,给定超参数$0
\l
eq
\b
eta_2 < 1$(算法作者建议设为0.999),
将小批量随机梯度按元素平方后的项$
\b
oldsymbol{g}_t
\o
dot
\b
oldsymbol{g}_t$做指数加权移动平均得到$
\b
oldsymbol{s}_t$:
$$
\b
oldsymbol{s}_t
\l
eftarrow
\b
eta_2
\b
oldsymbol{s}_{t-1} + (1 -
\b
eta_2)
\b
oldsymbol{g}_t
\o
dot
\b
oldsymbol{g}_t. $$
由于我们将$
\b
oldsymbol{v}_0$和$
\b
oldsymbol{s}_0$中的元素都初始化为0,
在时间步$t$我们得到$
\b
oldsymbol{v}_t = (1-
\b
eta_1)
\s
um_{i=1}^t
\b
eta_1^{t-i}
\b
oldsymbol{g}_i$。将过去各时间步小批量随机梯度的权值相加,得到 $(1-
\b
eta_1)
\s
um_{i=1}^t
\b
eta_1^{t-i} = 1 -
\b
eta_1^t$。需要注意的是,当$t$较小时,过去各时间步小批量随机梯度权值之和会较小。例如,当$
\b
eta_1 = 0.9$时,$
\b
oldsymbol{v}_1 = 0.1
\b
oldsymbol{g}_1$。为了消除这样的影响,对于任意时间步$t$,我们可以将$
\b
oldsymbol{v}_t$再除以$1 -
\b
eta_1^t$,从而使过去各时间步小批量随机梯度权值之和为1。这也叫作偏差修正。在Adam算法中,我们对变量$
\b
oldsymbol{v}_t$和$
\b
oldsymbol{s}_t$均作偏差修正:
$$
\h
at{
\b
oldsymbol{v}}_t
\l
eftarrow
\f
rac{
\b
oldsymbol{v}_t}{1 -
\b
eta_1^t}, $$
$$
\h
at{
\b
oldsymbol{s}}_t
\l
eftarrow
\f
rac{
\b
oldsymbol{s}_t}{1 -
\b
eta_2^t}. $$
接下来,Adam算法使用以上偏差修正后的变量$
\h
at{
\b
oldsymbol{v}}_t$和$
\h
at{
\b
oldsymbol{s}}_t$,将模型参数中每个元素的学习率通过按元素运算重新调整:
$$
\b
oldsymbol{g}_t'
\l
eftarrow
\f
rac{
\e
ta
\h
at{
\b
oldsymbol{v}}_t}{
\s
qrt{
\h
at{
\b
oldsymbol{s}}_t} +
\e
psilon},$$
其中$
\e
ta$是学习率,$
\e
psilon$是为了维持数值稳定性而添加的常数,如$10^{-8}$。和AdaGrad算法、RMSProp算法以及AdaDelta算法一样,目标函数自变量中每个元素都分别拥有自己的学习率。最后,使用$
\b
oldsymbol{g}_t'$迭代自变量:
$$
\b
oldsymbol{x}_t
\l
eftarrow
\b
oldsymbol{x}_{t-1} -
\b
oldsymbol{g}_t'. $$
## 7.8.2 从零开始实现
我们按照Adam算法中的公式实现该算法。其中时间步$t$通过
`hyperparams`
参数传入
`adam`
函数。
```
python
%
matplotlib
inline
import
torch
import
sys
sys
.
path
.
append
(
".."
)
import
d2lzh_pytorch
as
d2l
features
,
labels
=
d2l
.
get_data_ch7
()
def
init_adam_states
():
v_w
,
v_b
=
torch
.
zeros
((
features
.
shape
[
1
],
1
),
dtype
=
torch
.
float32
),
torch
.
zeros
(
1
,
dtype
=
torch
.
float32
)
s_w
,
s_b
=
torch
.
zeros
((
features
.
shape
[
1
],
1
),
dtype
=
torch
.
float32
),
torch
.
zeros
(
1
,
dtype
=
torch
.
float32
)
return
((
v_w
,
s_w
),
(
v_b
,
s_b
))
def
adam
(
params
,
states
,
hyperparams
):
beta1
,
beta2
,
eps
=
0.9
,
0.999
,
1e-6
for
p
,
(
v
,
s
)
in
zip
(
params
,
states
):
v
[:]
=
beta1
*
v
+
(
1
-
beta1
)
*
p
.
grad
.
data
s
[:]
=
beta2
*
s
+
(
1
-
beta2
)
*
p
.
grad
.
data
**
2
v_bias_corr
=
v
/
(
1
-
beta1
**
hyperparams
[
't'
])
s_bias_corr
=
s
/
(
1
-
beta2
**
hyperparams
[
't'
])
p
.
data
-=
hyperparams
[
'lr'
]
*
v_bias_corr
/
(
torch
.
sqrt
(
s_bias_corr
)
+
eps
)
hyperparams
[
't'
]
+=
1
```
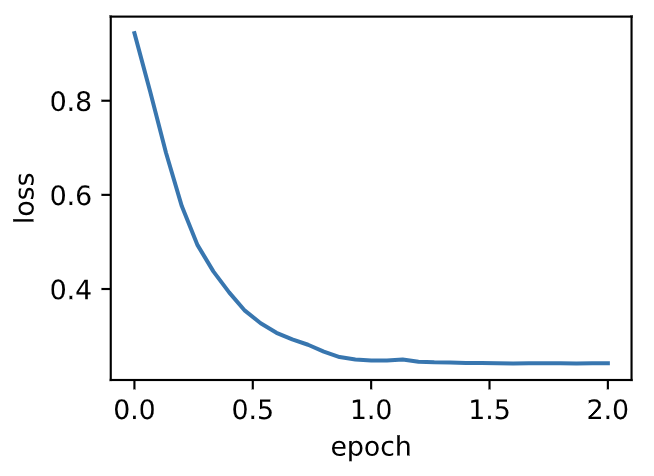
使用学习率为0.01的Adam算法来训练模型。
```
python
d2l
.
train_ch7
(
adam
,
init_adam_states
(),
{
'lr'
:
0.01
,
't'
:
1
},
features
,
labels
)
```
输出:
```
loss: 0.245370, 0.065155 sec per epoch
```
<div
align=
center
>
<img
width=
"300"
src=
"../../img/chapter07/7.8_output1.png"
/>
</div>
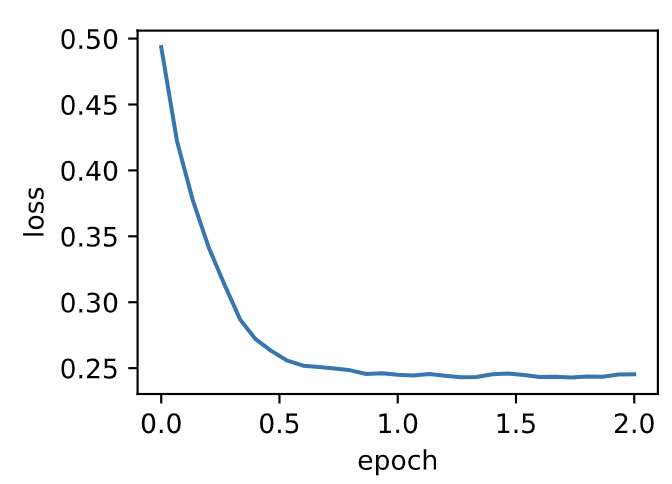
## 7.8.3 简洁实现
通过名称为“adam”的
`Trainer`
实例,我们便可使用Gluon提供的Adam算法。
```
python
d2l
.
train_pytorch_ch7
(
torch
.
optim
.
Adam
,
{
'lr'
:
0.01
},
features
,
labels
)
```
输出:
```
loss: 0.242066, 0.056867 sec per epoch
```
<div
align=
center
>
<img
width=
"300"
src=
"../../img/chapter07/7.8_output2.png"
/>
</div>
## 小结
*
Adam算法在RMSProp算法的基础上对小批量随机梯度也做了指数加权移动平均。
*
Adam算法使用了偏差修正。
## 参考文献
[1] Kingma, D. P., & Ba, J. (2014). Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
-----------
> 注:除代码外本节与原书此节基本相同,[原书传送门](https://zh.d2l.ai/chapter_optimization/adam.html)
img/chapter07/7.8_output1.png
0 → 100644
浏览文件 @
23ffe9e8
33.6 KB
img/chapter07/7.8_output2.png
0 → 100644
浏览文件 @
23ffe9e8
28.5 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}