refactoring
Showing
LICENSE
0 → 100644
此差异已折叠。
cnocr/__init__.py
0 → 100644
cnocr/data_utils/__init__.py
0 → 100644
cnocr/data_utils/data_iter.py
0 → 100644
cnocr/fit/__init__.py
0 → 100644
cnocr/fit/ctc_loss.py
0 → 100644
cnocr/fit/ctc_metrics.py
0 → 100644
cnocr/fit/fit.py
0 → 100644
cnocr/fit/lstm.py
0 → 100644
cnocr/hyperparams/__init__.py
0 → 100644
cnocr/hyperparams/hyperparams2.py
0 → 100644
cnocr/symbols/__init__.py
0 → 100644
文件已添加
文件已添加
文件已添加
cnocr/symbols/crnn.py
0 → 100644
examples/00010965.jpg
0 → 100644
{kind=link}

2.8 KB
examples/00010994.jpg
0 → 100644
{kind=link}

6.1 KB
examples/20457890_2399557098.jpg
0 → 100644
{kind=link}

1.9 KB
examples/rand_cn1.png
0 → 100644
{kind=link}

4.5 KB
examples/rand_cn2.png
0 → 100644
{kind=link}
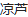
516 字节
requirements.txt
0 → 100644
scripts/infer_ocr.py
0 → 100644
scripts/run_crnn.sh
0 → 100644
scripts/train_ocr.py
0 → 100644
setup.py
0 → 100644