Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
爱吃血肠
leetcode
提交
58a8c787
L
leetcode
项目概览
爱吃血肠
/
leetcode
通知
1
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
L
leetcode
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
58a8c787
编写于
4月 08, 2019
作者:
L
luzhipeng
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
feat: 增加布隆过滤器
上级
aba01199
变更
3
隐藏空白更改
内联
并排
Showing
3 changed file
with
49 addition
and
2 deletion
+49
-2
README.md
README.md
+1
-2
assets/thinkings/bloom-filter-url.png
assets/thinkings/bloom-filter-url.png
+0
-0
thinkings/bloom-filter.md
thinkings/bloom-filter.md
+48
-0
未找到文件。
README.md
浏览文件 @
58a8c787
...
...
@@ -67,6 +67,7 @@ leetcode 题解,记录自己的 leecode 解题之路。
-
[
binary-tree-traversal
](
./thinkings/binary-tree-traversal.md
)
-
[
dynamic-programming
](
./thinkings/dynamic-programming.md
)
-
[
哈夫曼编码和游程编码
](
./thinkings/run-length-encode-and-huffman-encode.md
)
-
[
布隆过滤器
](
./thinkings/bloom-filter.md
)
### anki 卡片
...
...
@@ -82,6 +83,4 @@ TODO
[React fiber]
[一个非常简单,但是有效的算法 - 布隆过滤器]
> 从这个算法可以对 tradeoff 有更入的理解。
assets/thinkings/bloom-filter-url.png
0 → 100644
浏览文件 @
58a8c787
99.9 KB
thinkings/bloom-filter.md
0 → 100644
浏览文件 @
58a8c787
## 场景
假设你现在要处理这样一个问题,你有一个网站并且拥有
`很多`
访客,每当有用户访问时,你想知道这个ip是不是第一次访问你的网站。
### hashtable 可以么
一个显而易见的答案是将所有的ip用hashtable存起来,每次访问都去hashtable中取,然后判断即可。但是题目说了网站有
`很多`
访客,
假如有10亿个用户访问过,每个ip的长度是4 byte,那么你一共需要4
*
1000000000 = 4000000000Bytes = 4G , 如果是判断URL黑名单,
由于每个URL会更长,那么需要的空间可能会远远大于你的期望。
### bit
另一个稍微难想到的解法是bit, 我们知道bit有0和1两种状态,那么用来表示存在,不存在再合适不过了。
加入有10亿个ip,我们就可以用10亿个bit来存储,那么你一共需要 1
*
1000000000 = (4000000000 / 8) Bytes = 128M, 变为原来的1/32,
如果是存储URL这种更长的字符串,效率会更高。
基于这种想法,我们只需要两个操作,set(ip) 和 has(ip)
这样做有两个非常致命的缺点:
1.
当样本分布极度不均匀的时候,会造成很大空间上的浪费
> 我们可以通过散列函数来解决
2.
当元素不是整型(比如URL)的时候,BitSet就不适用了
> 我们还是可以使用散列函数来解决, 甚至可以多hash几次
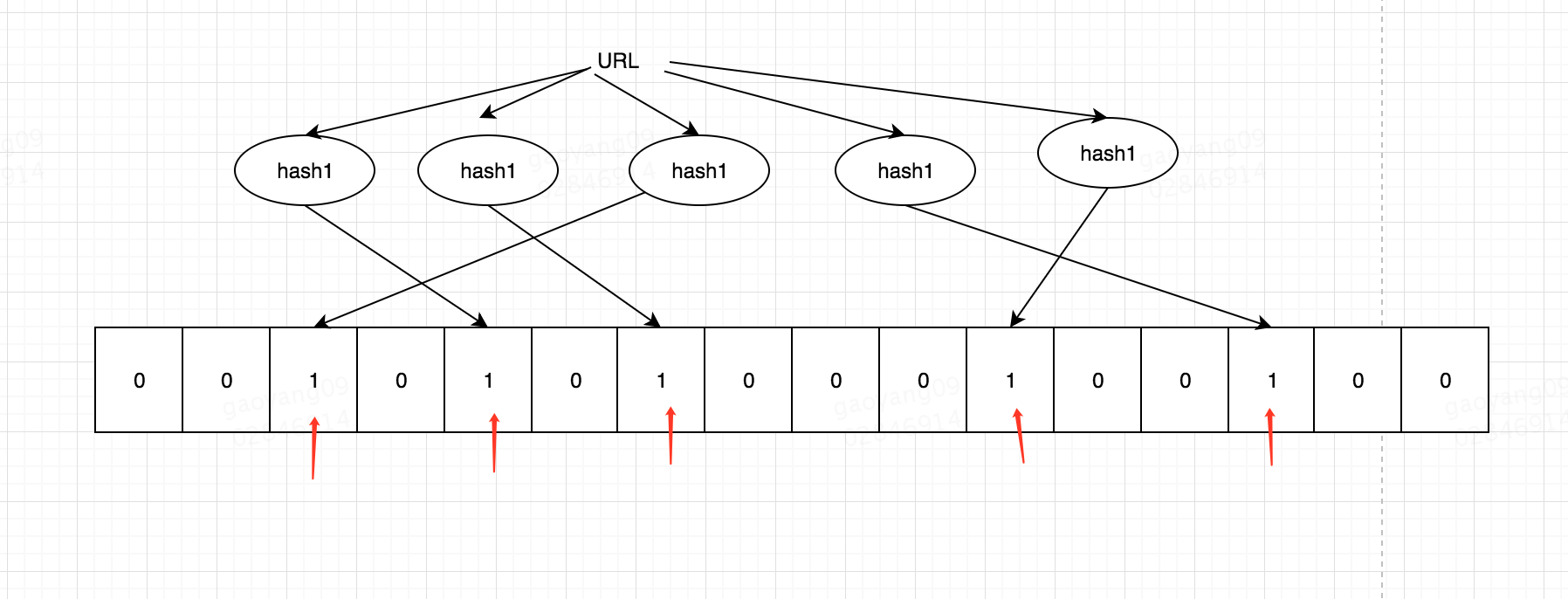
### 布隆过滤器
布隆过滤器其实就是
`bit + 多个散列函数`
, 如果经过多次散列的值再bit上都为1,那么可能存在(可能有冲突)。 如果
有一个不为1,那么一定不存在(一个值经过散列函数得到的值一定是唯一的),这也是布隆过滤器的一个重要特点。

### 布隆过滤器的应用
1.
网络爬虫
判断某个URL是否已经被爬取过
2.
K-V数据库 判断某个key是否存在
比如Hbase的每个Region中都包含一个BloomFilter,用于在查询时快速判断某个key在该region中是否存在。
3.
钓鱼网站识别
浏览器有时候会警告用户,访问的网站很可能是钓鱼网站,用的就是这种技术
> 从这个算法大家可以对 tradeoff(取舍) 有更入的理解。
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}