Merge pull request #654 from PaddlePaddle/revert-653-ernie-doc
Revert "add ernie-doc to ernie develop"
Showing
ernie-doc/.gitignore
已删除
100644 → 0
ernie-doc/.meta/framework.pdf
已删除
100644 → 0
文件已删除
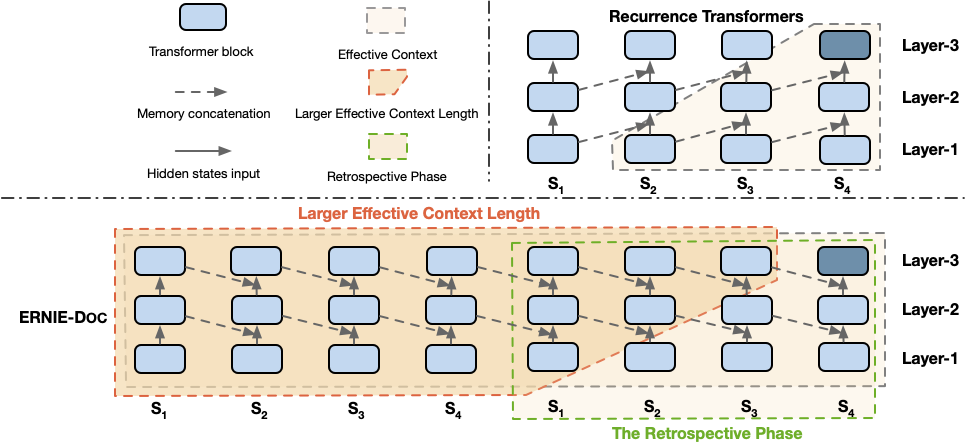
ernie-doc/.meta/framework.png
已删除
100644 → 0
{kind=link}
83.4 KB
ernie-doc/README.md
已删除
100644 → 0
ernie-doc/README_zh.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
ernie-doc/configs/vocab.bpe
已删除
100644 → 0
此差异已折叠。
ernie-doc/data/imdb/README.md
已删除
100644 → 0
ernie-doc/finetune/mrc.py
已删除
100644 → 0
ernie-doc/lanch.py
已删除
100644 → 0
ernie-doc/model/__init__.py
已删除
100644 → 0
ernie-doc/reader/__init__.py
已删除
100644 → 0
ernie-doc/reader/batching.py
已删除
100644 → 0
此差异已折叠。
ernie-doc/requirements.txt
已删除
100644 → 0
ernie-doc/run_classifier.py
已删除
100644 → 0
ernie-doc/run_mrc.py
已删除
100644 → 0
ernie-doc/scripts/run_imdb.sh
已删除
100644 → 0
ernie-doc/utils/__init__.py
已删除
100644 → 0
ernie-doc/utils/args.py
已删除
100644 → 0
ernie-doc/utils/init.py
已删除
100644 → 0
ernie-doc/utils/metrics.py
已删除
100644 → 0
此差异已折叠。
此差异已折叠。