Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
erosXXX
uni-app
提交
c48e8710
U
uni-app
项目概览
erosXXX
/
uni-app
与 Fork 源项目一致
Fork自
DCloud / uni-app
通知
1
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
DevOps
流水线
流水线任务
计划
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
U
uni-app
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
DevOps
DevOps
流水线
流水线任务
计划
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
流水线任务
提交
Issue看板
体验新版 GitCode,发现更多精彩内容 >>
未验证
提交
c48e8710
编写于
9月 29, 2020
作者:
W
wanganxp
提交者:
GitHub
9月 29, 2020
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
Update cf-database.md
上级
4e6863c1
变更
1
隐藏空白更改
内联
并排
Showing
1 changed file
with
55 addition
and
57 deletion
+55
-57
docs/uniCloud/cf-database.md
docs/uniCloud/cf-database.md
+55
-57
未找到文件。
docs/uniCloud/cf-database.md
浏览文件 @
c48e8710
...
@@ -99,47 +99,47 @@ uniCloud会在每天备份一次数据库,最多保留7天。
...
@@ -99,47 +99,47 @@ uniCloud会在每天备份一次数据库,最多保留7天。
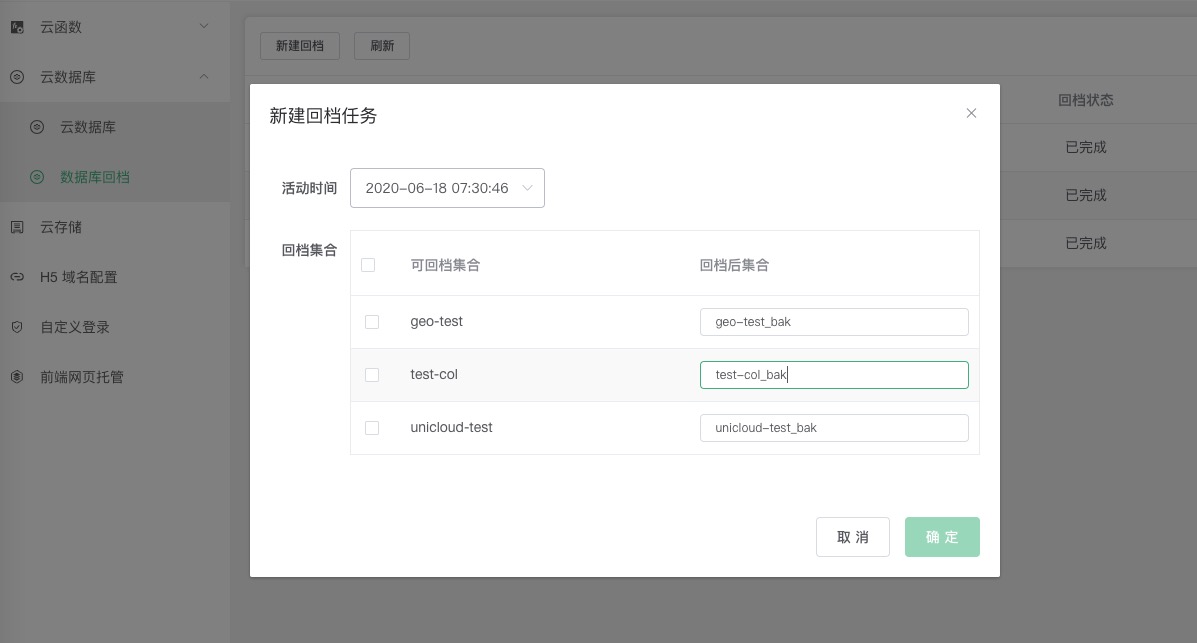
3.
选择可回档时间
3.
选择可回档时间
4.
选择需要回档的集合(注意:回档后集合不能与现有集合重名,如需对集合重命名可以在集合列表处操作)
4.
选择需要回档的集合(注意:回档后集合不能与现有集合重名,如需对集合重命名可以在集合列表处操作)

## 数据导出@export
## 数据导出@export
**此功能暂时只有阿里云支持**
**此功能暂时只有阿里云支持**
此功能主要用于导出整个集合的数据
此功能主要用于导出整个集合的数据
**用法**
**用法**
1.
进入
[
uniCloud web控制台
](
https://unicloud.dcloud.net.cn/home
)
,选择服务空间,或者直接在HBuilderX云函数目录
`cloudfunctions`
上右键打开uniCloud web控制台
1.
进入
[
uniCloud web控制台
](
https://unicloud.dcloud.net.cn/home
)
,选择服务空间,或者直接在HBuilderX云函数目录
`cloudfunctions`
上右键打开uniCloud web控制台
2.
进入云数据库选择希望导入数据的集合
2.
进入云数据库选择希望导入数据的集合
3.
点击导出按钮
3.
点击导出按钮
4.
选择导出格式,如果选择csv格式还需要选择导出字段
4.
选择导出格式,如果选择csv格式还需要选择导出字段
5.
点击确定按钮等待下载开始即可
5.
点击确定按钮等待下载开始即可
**注意**
**注意**
-
导出的json文件并非一般情况下的json,而是每行一条json数据的文本文件
-
导出的json文件并非一般情况下的json,而是每行一条json数据的文本文件
-
导出为csv时必须填写字段选项。字段之间使用英文逗号隔开。例如:
`_id, name, age, gender`
-
导出为csv时必须填写字段选项。字段之间使用英文逗号隔开。例如:
`_id, name, age, gender`
-
数据量较大时可能需要等待一段时间才可以开始下载
-
数据量较大时可能需要等待一段时间才可以开始下载
## 数据导入@import
## 数据导入@import
**此功能暂时只有阿里云支持**
**此功能暂时只有阿里云支持**
uniCloud提供的
`db_init.json`
主要是为了对数据库进行初始化,并不适合导入大量数据。与
`db_init.json`
不同,数据导入功能可以导入大量数据,目前支持导入 CSV、JSON 格式的文件数据。
uniCloud提供的
`db_init.json`
主要是为了对数据库进行初始化,并不适合导入大量数据。与
`db_init.json`
不同,数据导入功能可以导入大量数据,目前支持导入 CSV、JSON 格式的文件数据。
**用法**
**用法**
1.
进入
[
uniCloud web控制台
](
https://unicloud.dcloud.net.cn/home
)
,选择服务空间,或者直接在HBuilderX云函数目录
`cloudfunctions`
上右键打开uniCloud web控制台
1.
进入
[
uniCloud web控制台
](
https://unicloud.dcloud.net.cn/home
)
,选择服务空间,或者直接在HBuilderX云函数目录
`cloudfunctions`
上右键打开uniCloud web控制台
2.
进入云数据库选择希望导入数据的集合
2.
进入云数据库选择希望导入数据的集合
3.
点击导入,选择json文件或csv文件
3.
点击导入,选择json文件或csv文件
4.
选择处理冲突模式(关于处理冲突模式请看下方注意事项)
4.
选择处理冲突模式(关于处理冲突模式请看下方注意事项)
5.
点击确定按钮等待导入完成即可
5.
点击确定按钮等待导入完成即可
**注意**
**注意**
-
目前导入文件最大限制为50MB
-
目前导入文件最大限制为50MB
-
导入csv时数据类型会丢失,即所有字段均会作为字符串导入
-
导入csv时数据类型会丢失,即所有字段均会作为字符串导入
-
冲突处理模式为设定记录_id冲突时的处理方式,
`insert`
表示冲突时依旧导入记录但是是新插入一条,
`upsert`
表示冲突时更新已存在的记录
-
冲突处理模式为设定记录_id冲突时的处理方式,
`insert`
表示冲突时依旧导入记录但是是新插入一条,
`upsert`
表示冲突时更新已存在的记录
## 获取集合的引用
## 获取集合的引用
...
@@ -275,8 +275,6 @@ exports.main = async (event, context) => {
...
@@ -275,8 +275,6 @@ exports.main = async (event, context) => {
### 地理位置
### 地理位置
**阿里云升级mongoDB为4.0版本后已支持地理位置**
参考:
[
GEO地理位置
](
#GEO地理位置
)
参考:
[
GEO地理位置
](
#GEO地理位置
)
### Null
### Null
...
@@ -479,11 +477,11 @@ collection.orderBy()
...
@@ -479,11 +477,11 @@ collection.orderBy()
| --------- | ------ | ---- | ----------------------------------- |
| --------- | ------ | ---- | ----------------------------------- |
| field | string | 是 | 排序的字段 |
| field | string | 是 | 排序的字段 |
| orderType | string | 是 | 排序的顺序,升序(asc) 或 降序(desc) |
| orderType | string | 是 | 排序的顺序,升序(asc) 或 降序(desc) |
如果需要对嵌套字段排序,需要用 "点表示法" 连接嵌套字段,比如 style.color 表示字段 style 里的嵌套字段 color。
如果需要对嵌套字段排序,需要用 "点表示法" 连接嵌套字段,比如 style.color 表示字段 style 里的嵌套字段 color。
同时也支持按多个字段排序,多次调用 orderBy 即可,多字段排序时的顺序会按照 orderBy 调用顺序先后对多个字段排序
同时也支持按多个字段排序,多次调用 orderBy 即可,多字段排序时的顺序会按照 orderBy 调用顺序先后对多个字段排序
使用示例
使用示例
...
@@ -758,13 +756,13 @@ let res = await collection.where({
...
@@ -758,13 +756,13 @@ let res = await collection.where({
_id
:
dbCmd
.
exists
(
true
)
_id
:
dbCmd
.
exists
(
true
)
}).
remove
()
}).
remove
()
```
```
响应参数
响应参数
| 字段 | 类型 | 必填 | 说明 |
| 字段 | 类型 | 必填 | 说明 |
| --------- | ------- | ---- | ------------------------ |
| --------- | ------- | ---- | ------------------------ |
| deleted | Integer | 否 | 删除的记录数量 |
| deleted | Integer | 否 | 删除的记录数量 |
## 更新文档
## 更新文档
...
@@ -2530,7 +2528,7 @@ WHERE <output array field> IN (SELECT *
...
@@ -2530,7 +2528,7 @@ WHERE <output array field> IN (SELECT *
-
组合 mergeObjects 应用相等匹配
-
组合 mergeObjects 应用相等匹配
#### 自定义连接条件、拼接子查询
#### 自定义连接条件、拼接子查询
阿里云升级mongoDB版本为4.0后已支持此写法
阿里云升级mongoDB版本为4.0后已支持此写法
如果需要指定除相等匹配之外的连接条件,或指定多个相等匹配条件,或需要拼接被连接集合的子查询结果,那可以使用如下定义:
如果需要指定除相等匹配之外的连接条件,或指定多个相等匹配条件,或需要拼接被连接集合的子查询结果,那可以使用如下定义:
...
@@ -2842,7 +2840,7 @@ let res = await db.collection('orders').aggregate()
...
@@ -2842,7 +2840,7 @@ let res = await db.collection('orders').aggregate()
-
orders 的 book 字段与 books 的 title 字段相等
-
orders 的 book 字段与 books 的 title 字段相等
-
books 的 stock 字段 大于或等于 orders 的 quantityorders 字段
-
books 的 stock 字段 大于或等于 orders 的 quantityorders 字段
```
js
```
js
const
db
=
cloud
.
database
()
const
db
=
cloud
.
database
()
const
dbCmd
=
db
.
command
const
dbCmd
=
db
.
command
const
$
=
dbCmd
.
aggregate
const
$
=
dbCmd
.
aggregate
let
res
=
await
db
.
collection
(
'
orders
'
).
aggregate
()
let
res
=
await
db
.
collection
(
'
orders
'
).
aggregate
()
...
@@ -4537,7 +4535,7 @@ let res = await db.collection('todos').doc('doc-id').update({
...
@@ -4537,7 +4535,7 @@ let res = await db.collection('todos').doc('doc-id').update({
someField
:
dbCmd
.
rename
(
'
someObject.renamedField
'
)
someField
:
dbCmd
.
rename
(
'
someObject.renamedField
'
)
}
}
})
})
```
```
或:
或:
...
@@ -4606,7 +4604,7 @@ let res = await db.collection('todos').doc('doc-id').update({
...
@@ -4606,7 +4604,7 @@ let res = await db.collection('todos').doc('doc-id').update({
})
})
```
```
##### 示例 3:排序
##### 示例 3:排序
插入后对整个数组做排序
插入后对整个数组做排序
...
@@ -4619,7 +4617,7 @@ let res = await db.collection('todos').doc('doc-id').update({
...
@@ -4619,7 +4617,7 @@ let res = await db.collection('todos').doc('doc-id').update({
sort
:
1
,
sort
:
1
,
})
})
})
})
```
```
不插入,只对数组做排序
不插入,只对数组做排序
...
@@ -4832,7 +4830,7 @@ let res = await db.collection('todos').doc('doc-id').update({
...
@@ -4832,7 +4830,7 @@ let res = await db.collection('todos').doc('doc-id').update({
})
})
```
```
##### 示例代码 2:添加多个元素
##### 示例代码 2:添加多个元素
需传入一个对象,其中有一个字段
`each`
,其值为数组,每个元素就是要添加的元素
需传入一个对象,其中有一个字段
`each`
,其值为数组,每个元素就是要添加的元素
...
@@ -4855,7 +4853,7 @@ let res = await db.collection('todos').doc('doc-id').update({
...
@@ -4855,7 +4853,7 @@ let res = await db.collection('todos').doc('doc-id').update({
聚合操作符。返回一个数字的绝对值。
聚合操作符。返回一个数字的绝对值。
##### API 说明
##### API 说明
语法如下:
语法如下:
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录