SPEAKER VGG CCT: Cross-corpus Speech Emotion Recognition with Speaker Embedding and Vision Transformers
PAPER
This is an official pytorch implementation of SPEAKER VGG CCT: Cross-corpus Speech Emotion Recognition with Speaker
Embedding and Vision Transformers (ACM Multimedia Asia 2022).
In this paper, we start from the general idea that Speech Emotion Recognition can be solved transforming the speech
signal into spectrograms that are then classified using Convolutional Neural Networks pretrained on generic images
and fine-tuned with spectrograms.
We develop a new learning solution for SER, which is based on Compact Convolutional Transformers (CCTs) combined with a speaker embedding. With CCTs, the learning power of Vision Transformers (ViT) is combined with a diminished need for large volume of data as made possible by the convolution. This is important in SER, where large corpora of data are usually not available. The speaker embedding allows the network to extract an identity representation of the speaker, which is then integrated by means of a self-attention mechanism with the features that the CCT extracts from the spectrogram.
Overall, the solution is capable of operating in real-time showing promising results in a cross-corpus scenario, where training and test datasets are kept separate. Experiments have been performed on several benchmarks in a cross-corpus setting as rarely used in the literature, with results that are comparable or superior to those obtained with state-of-the-art network architectures.
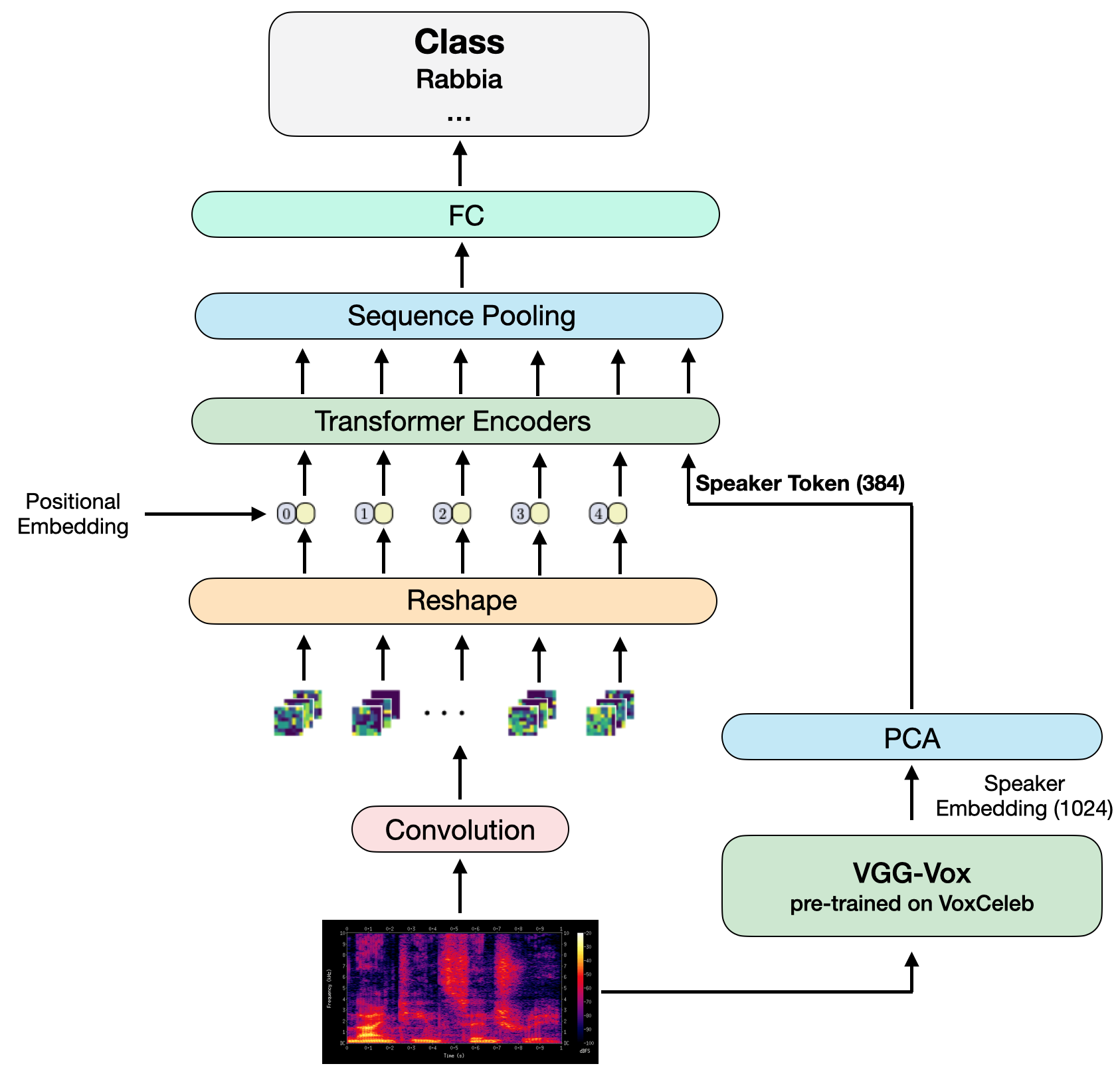
Environment
This repository is developed and tested on Ubuntu 20.04, Anaconda3, Python 3.7+, PyTorch 1.11+ and CUDA (cudatoolkit=11.3.1).
Quick Start
Installation
-
Clone this repository:
git clone https://github.com/JabuMlDev/Speaker-VGG-CCT -
Create conda environment and install required python packages :
conda env create -f environment.yml -
Activate the environment
source activate vit-for-ser
Preparation
- Download datasets and put it into ./datasets directory.
For each dataset, the data must be processed and organized in a specific dataset folder. Each file must be saved with .wav extension and labeled in the format emotion_dataset_subjectId_filename .
Speaker-VGG-CCT
│
└─── datasets
│
└─── EMOVO
│
└─── anger_emovo_01_filename.wav
└─── anger_emovo_02_filename.wav
└─── ...
└─── sad_emovo_04_filename.wav
|
└─── IEMOCAP
│
└─── anger_iemocap_01_filename.wav
└─── anger_iemocap_02_filename.wav
└─── ...
└─── sad_iemocap_10_filename.wav- Create the spectrograms from each audio file of the datasets and perform data augmentation
python preprocess_spectrograms.py By default, all datasets in the datasets folder are considered and all data augmentation included in the project are performed.
For change this, see the script parameters.
Spectrograms are saved in each dataset directory, in a folder named as dataset_img.
- Create the speaker embeddings from each audio file
python preprocess_embedding.pyAfter compute speaker embeddings, by default the script applies PCA to all data for extracting the most discriminative
384 features from them. Then PCA model is saved into ./encoder/model/pca.pkl and the reduced speaker embedding are
saved into ./datasets folder (in each dataset directory).
For more details see the article and for changes to this behavior see the parameters of the script.
- Split datasets into train, test and validation
python preprocess_split_dataset.py --eval_dataset <dataset_to_test> --num_classes 4 --augmentation time_freq_aug --balanced undersamplingThis script creates three .csv files that containing the positions of the files of train, test and validation set, and
it organizes them into ./data folder following a structure based on the parameters passed to the script.
The project is based on cross-corpus training. Therefore, the script requires the dataset to be used as a test set
among those present in the ./datasets folder. For training, all the other data are then used with a
Leave-One-Group-Out technique on the speakers for the split of the validation (speaker of the validation
chosen randomly from all).
Also you can choose number of classes between 'all' (supporting for happy, sad, neutral, anger, disgust,
fearful, surprised), '4' (anger, happy, neutral, sad) or '3' (mapping into positive, neutral
and negative labels), and you can set the type of augmentations to consider (in frequency or temporal domain)
and the balanced type (undersampling, with augmentation,...). See the script parameters for more details.
Training
Select one of the proposed model and train it
python train.py <position_train_data_folder> --model <model_name> -c ./configs/pretrained/cct_14-7x2_imagenet.yml --pretrained --num-classes 4 --input-size 3 224 224 --batch-size 32 --dataset '' --workers 8 --checkpoint-hist 1 --save_graphs --epochs 50 --no-aug --mixup 0 --cutmix 0 --lr 0.00005The script requires the position of the train data folder generated in the previous step as the first parameter
(e.g. ./data/EMOVO/4_classes/no_aug/undersampling/train_data) and the model to use as the second parameter
(e.g. speaker_vgg_cct_end_to_end_14_7x2_224). Check out the model names in the section below.
By default the script saves the best model and others training information into ./output/train/ folder. The structure of the models saved follows the
parameters passed to the previous script that generates the data.
To change the following train parameters you can refer to the script.
Evaluation
After you have trained a model in the previous step, you can test it
python eval.py <position_model_best_pth_tar> --data_test_path <position_train_data_folder> The script requires the position of the model_best.pth.tar to evaluate
as the first parameter (e.g. ./output/train/speaker_vgg_cct_end_to_end_14_7x2_224-pretrained/EMOVO/4_classes/no_aug/undersampling)
and the position of the eval data folder generated in the split dataset step as the second parameter
(e.g. ./data/EMOVO/4_classes/no_aug/undersampling/eval_data).
The results of the experiments including the confusion matrix and the main evaluation metrics are saved in the
./test/ folder
Models
This project extends the implementation of the Compact Transformers repo distributed in
https://github.com/SHI-Labs/Compact-Transformers.
For this reason, all the baseline models defined in Variants.md are also available in this project.
In addition to these the following models presented in the referenced paper have been implemented:
| Model | Resolution | PE | Name | Pretrained Weights | Config |
| SPEAKER VGG CCT | 224x224 | Learnable | speaker_vgg_cct_14_7x2_224 |
ImageNet-1k/300 Epochs | pretrained/cct_14-7x2_imagenet.yml |
| SPEAKER VGG CCT END TO END | 224x224 | Learnable | speaker_vgg_cct_end_to_end_14_7x2_224 |
ImageNet-1k/300 Epochs | pretrained/cct_14-7x2_imagenet.yml |
| SPEAKER VGG CCT END TO END SPEAKER TOKEN | 224x224 | Learnable | speaker_vgg_cct_end_to_end_speaker_token_14_7x2_224 |
ImageNet-1k/300 Epochs | pretrained/cct_14-7x2_imagenet.yml |
You can see the article for more information on the models and their nomenclature.
Citation
@article{speaker_vgg_cct,
title={SPEAKER VGG CCT: Cross-corpus Speech Emotion Recognition with Speaker Embedding and Vision Transformers},
author={Alessandro Arezzo, Stefano Berretti},
year={2022},
arXiv={https://arxiv.org/abs/2211.02366}
}