Merge branch 'main' of github.com:rcore-os/rCore-Tutorial-Book-v3 into main
Showing
docs/.buildinfo
已删除
100644 → 0
docs/.nojekyll
已删除
100644 → 0
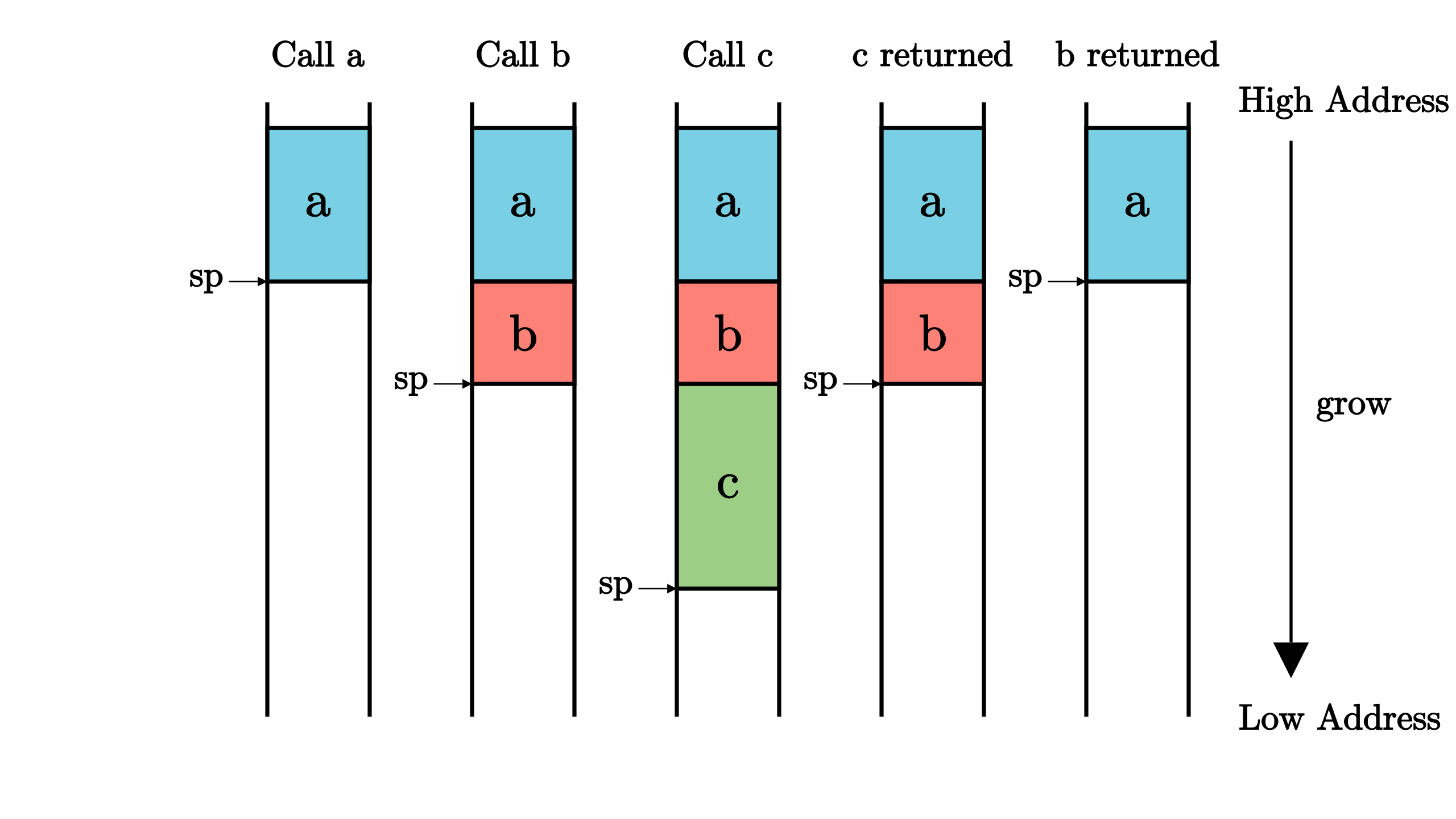
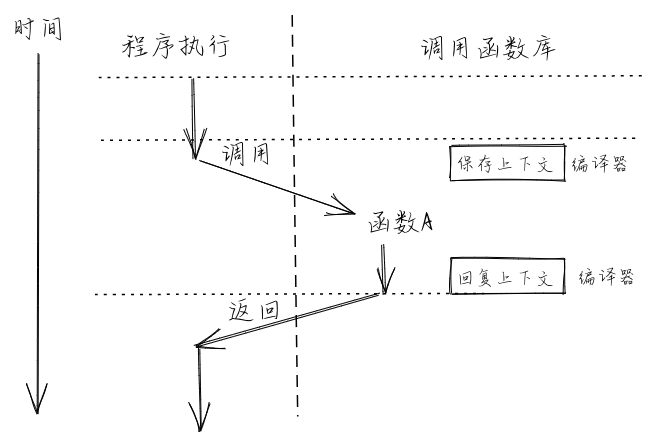
docs/_images/CallStack.png
已删除
100644 → 0
{kind=link}
88.7 KB
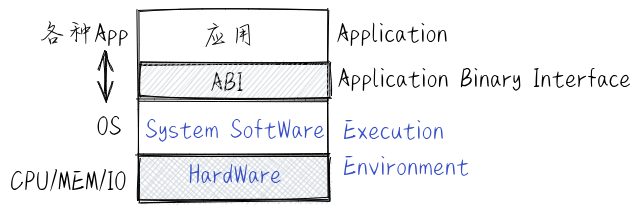
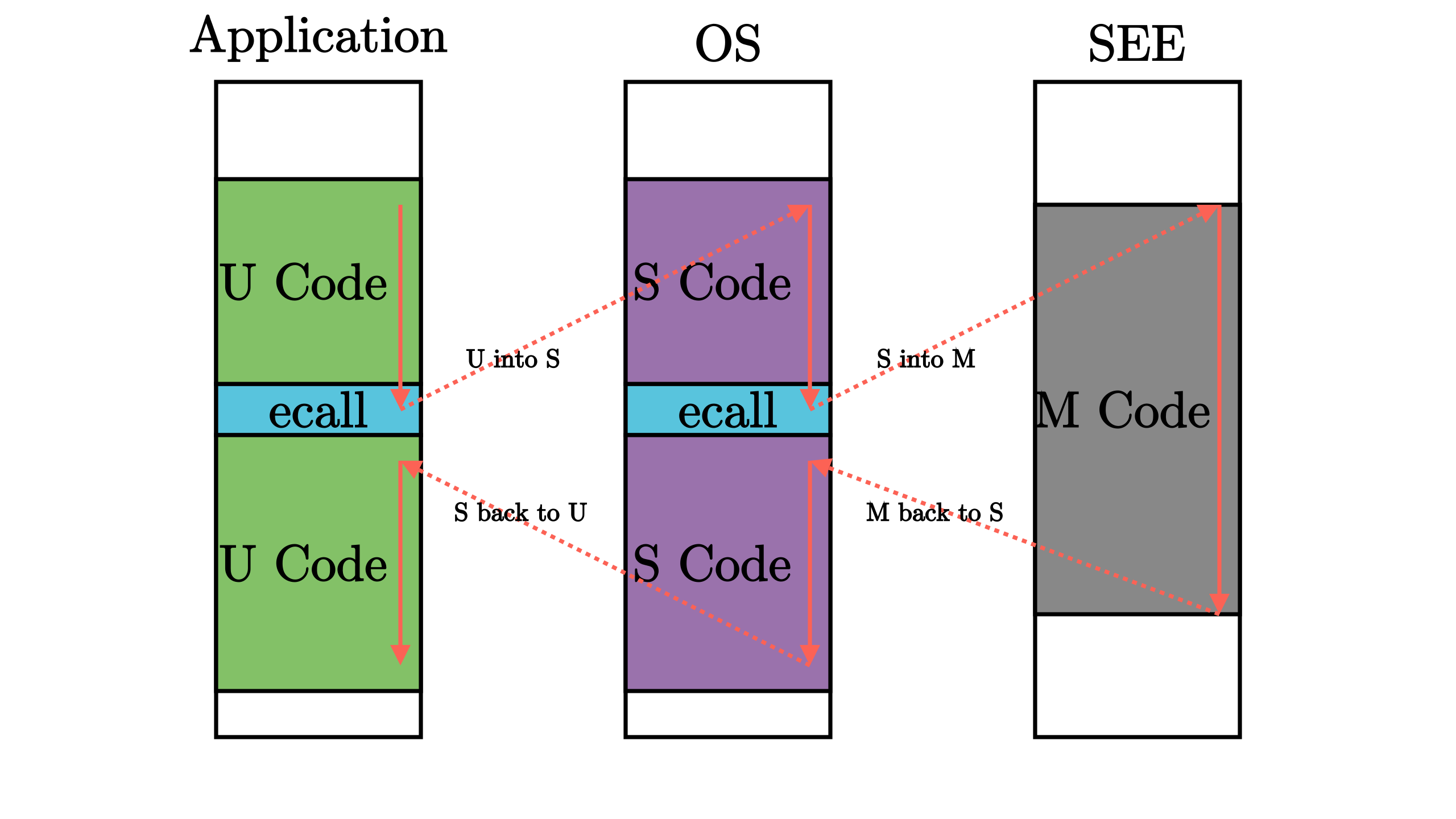
docs/_images/EE.png
已删除
100644 → 0
{kind=link}
66.8 KB
{kind=link}
154.8 KB
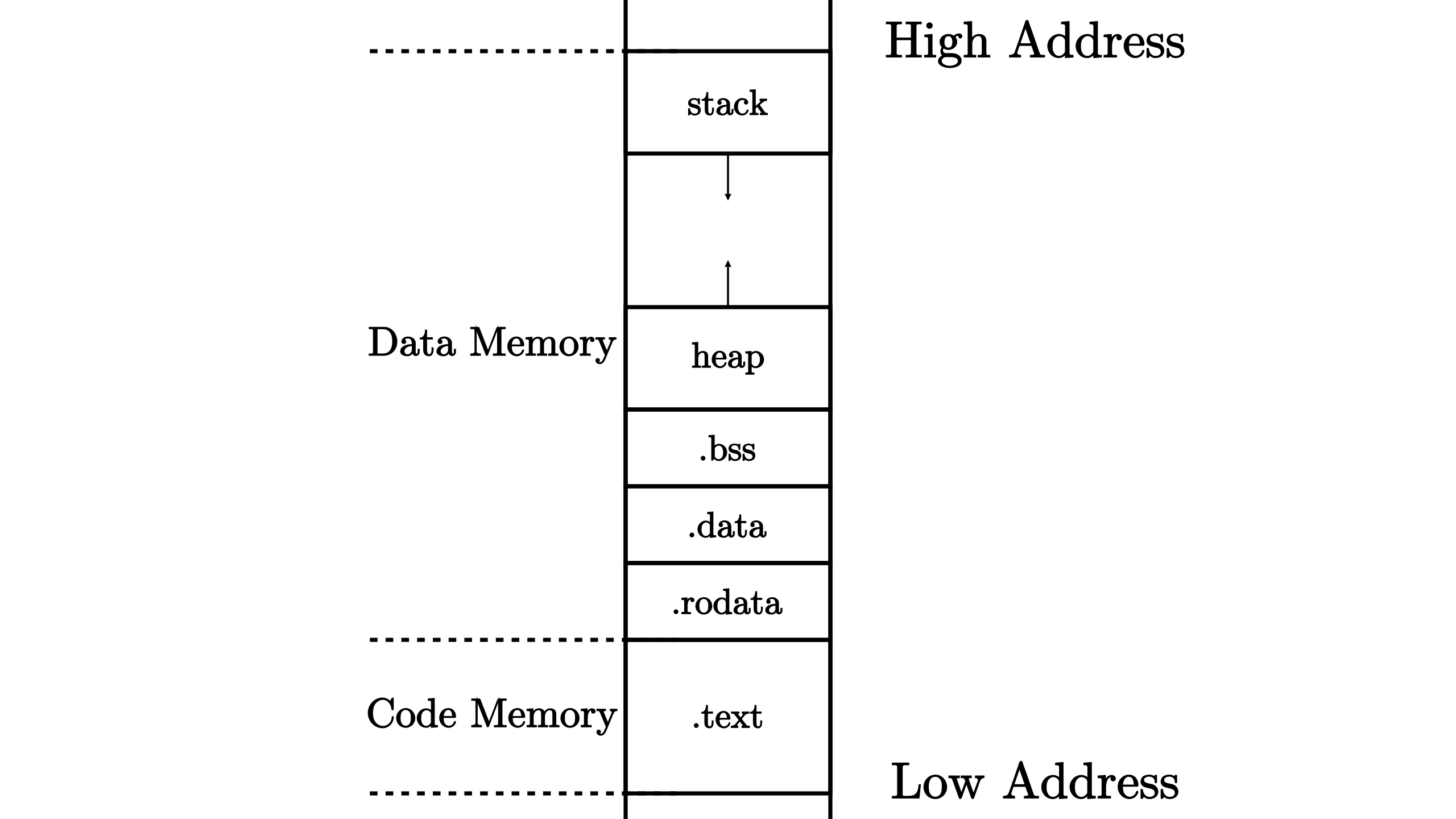
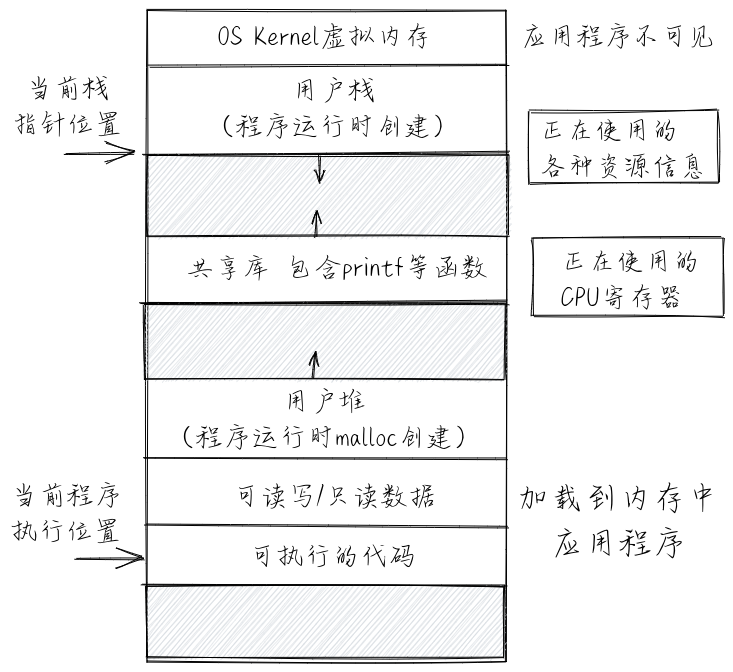
docs/_images/MemoryLayout.png
已删除
100644 → 0
{kind=link}
110.6 KB
{kind=link}
79.5 KB
docs/_images/StackFrame.png
已删除
100644 → 0
{kind=link}
74.9 KB
{kind=link}
140.5 KB
{kind=link}
43.2 KB
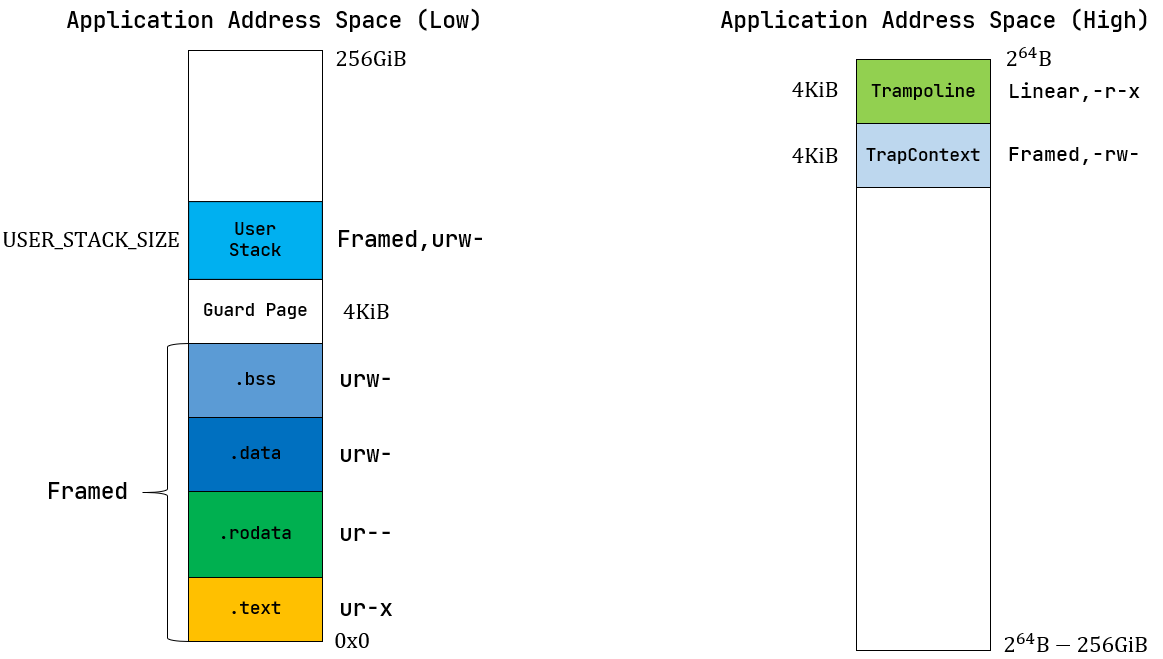
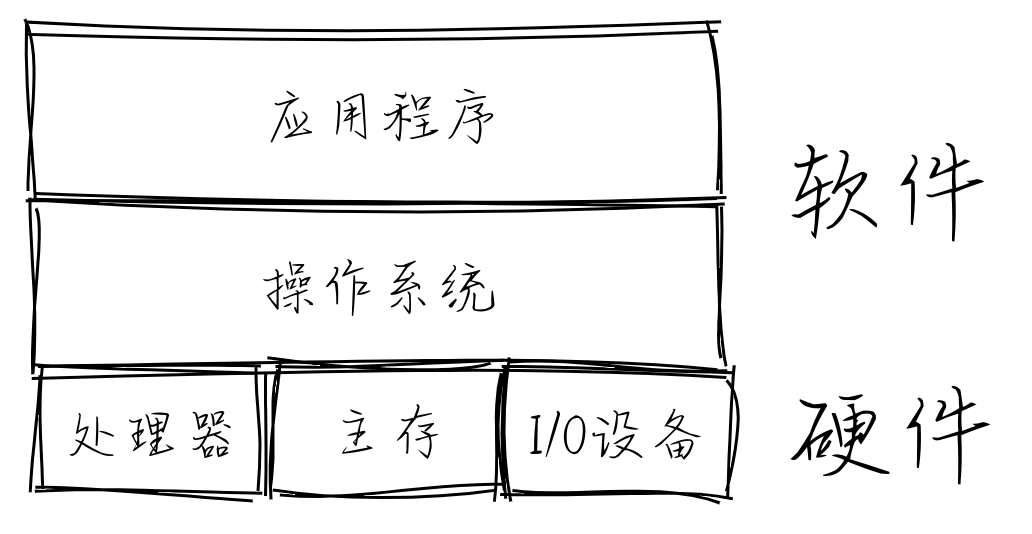
docs/_images/app-as-full.png
已删除
100644 → 0
{kind=link}
33.4 KB
{kind=link}
10.8 KB
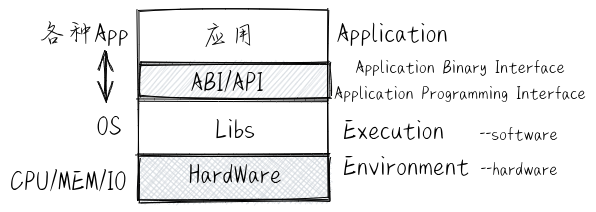
docs/_images/basic-EE.png
已删除
100644 → 0
{kind=link}
65.0 KB
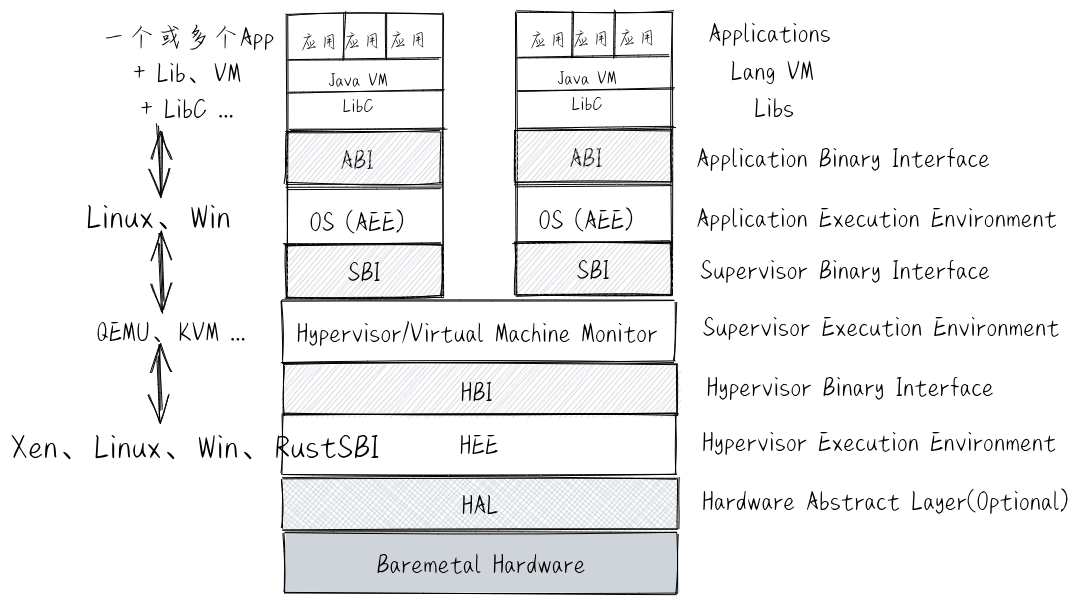
docs/_images/complex-EE.png
已删除
100644 → 0
{kind=link}
263.5 KB
{kind=link}
87.9 KB
{kind=link}
234.3 KB
{kind=link}
68.5 KB
docs/_images/deng-fish.png
已删除
100644 → 0
{kind=link}
19.4 KB
docs/_images/exception.png
已删除
100644 → 0
{kind=link}
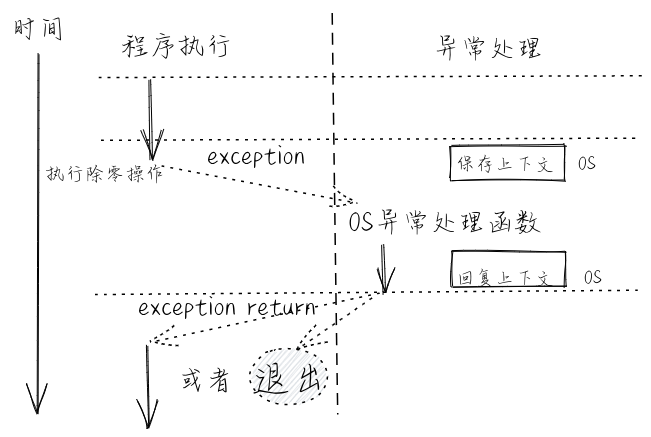
56.6 KB
docs/_images/file-disk.png
已删除
100644 → 0
{kind=link}
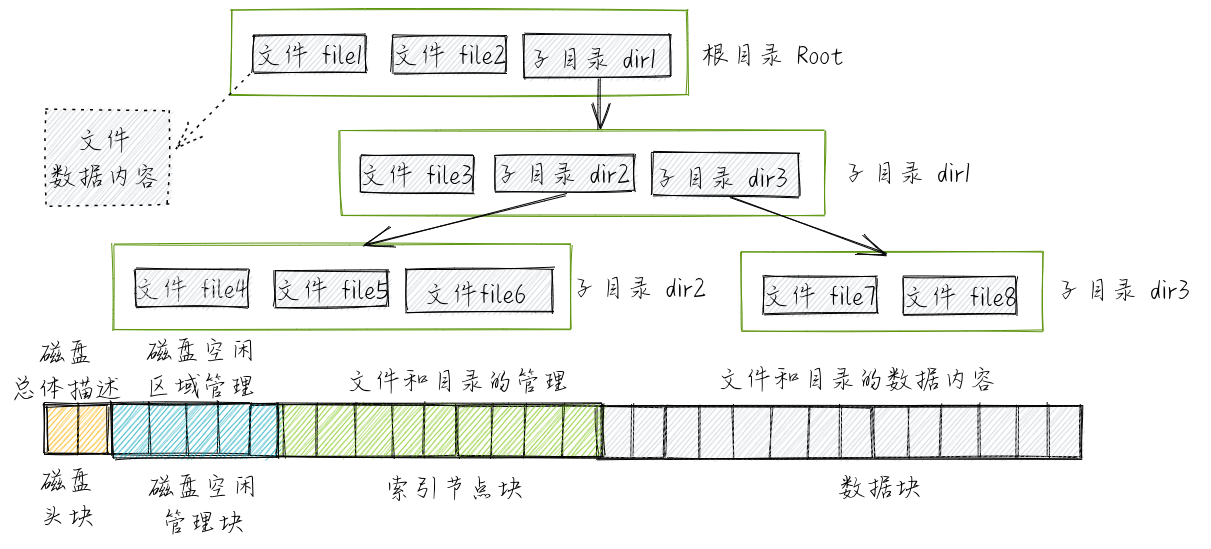
352.8 KB
docs/_images/fsm-coop.png
已删除
100644 → 0
{kind=link}
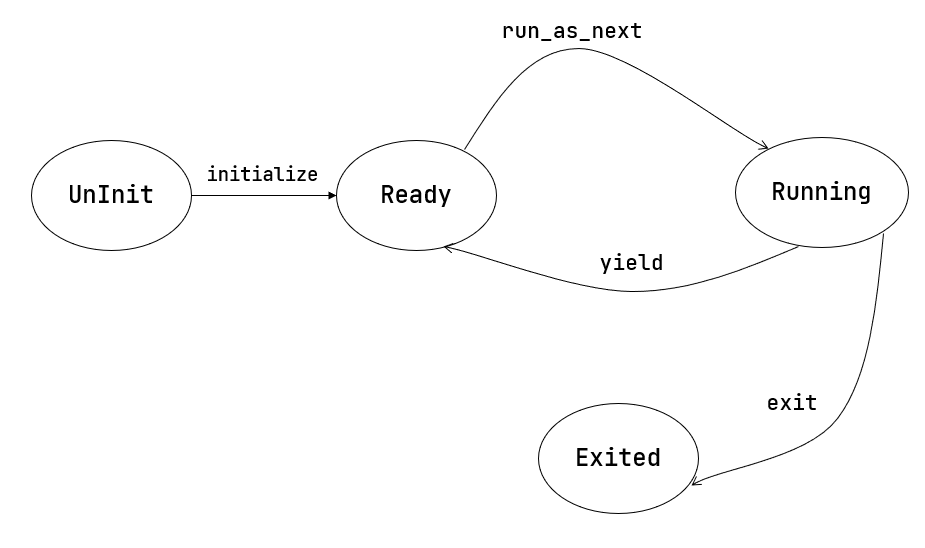
23.6 KB
{kind=link}
44.1 KB
docs/_images/interrupt.png
已删除
100644 → 0
{kind=link}
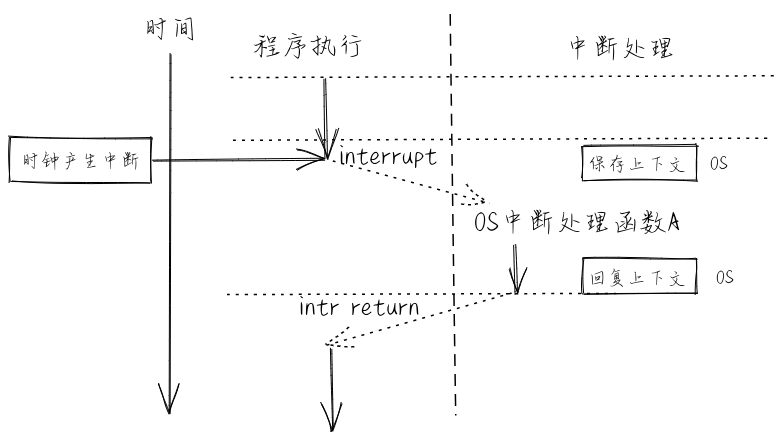
51.0 KB
docs/_images/k210-final.gif
已删除
100644 → 0
{kind=link}
4.5 MB
{kind=link}
33.9 KB
{kind=link}
19.9 KB
docs/_images/linear-table.png
已删除
100644 → 0
{kind=link}
19.9 KB
{kind=link}
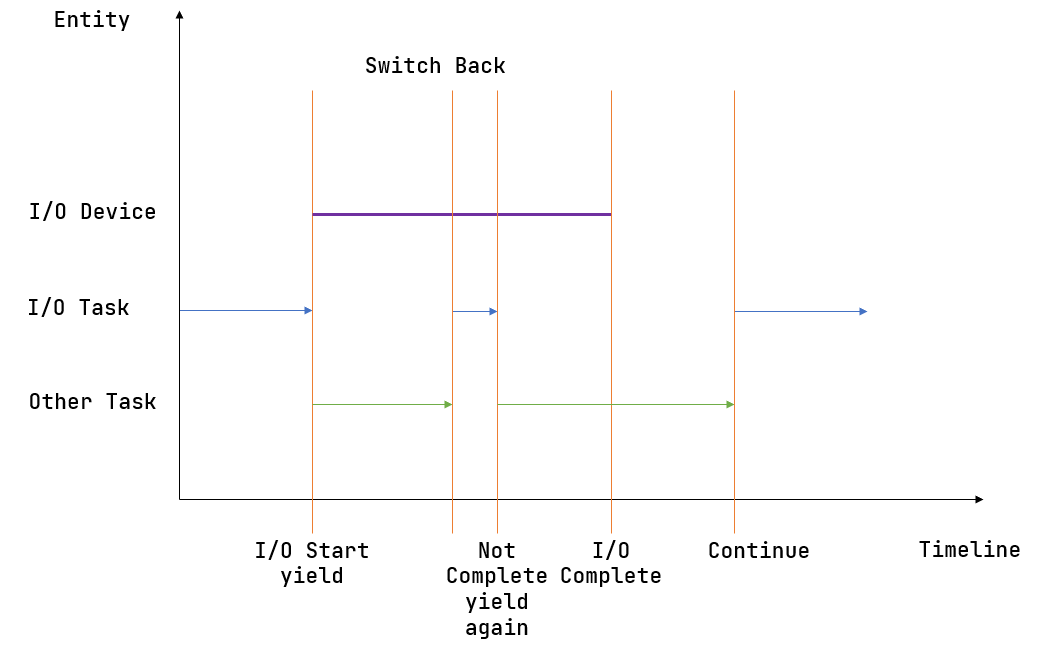
20.4 KB
docs/_images/page-table.png
已删除
100644 → 0
{kind=link}
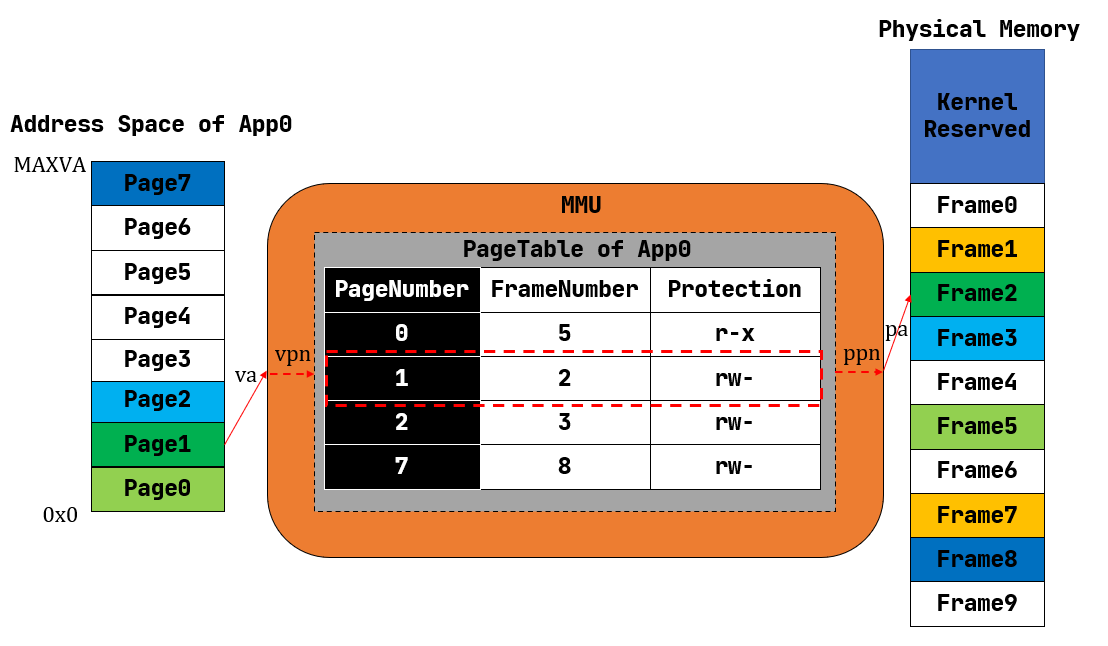
51.8 KB
docs/_images/prepare-sd.gif
已删除
100644 → 0
{kind=link}
95.3 KB
{kind=link}
62.5 KB
docs/_images/pte-rwx.png
已删除
100644 → 0
{kind=link}
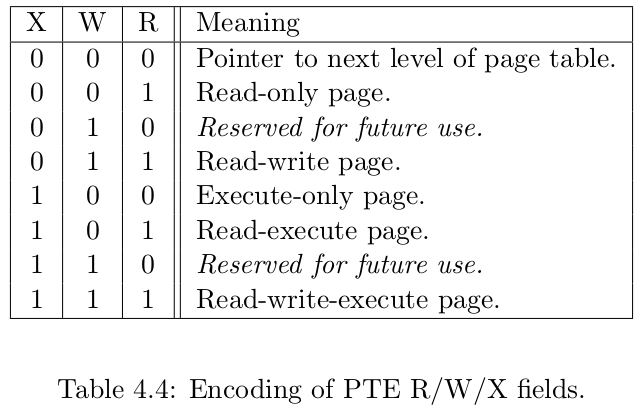
43.0 KB
docs/_images/qemu-final.gif
已删除
100644 → 0
{kind=link}
3.0 MB
docs/_images/run-app.png
已删除
100644 → 0
{kind=link}
49.3 KB
{kind=link}
85.3 KB
docs/_images/satp.png
已删除
100644 → 0
{kind=link}

23.1 KB
docs/_images/segmentation.png
已删除
100644 → 0
{kind=link}
53.5 KB
{kind=link}
43.0 KB
docs/_images/sv39-full.png
已删除
100644 → 0
{kind=link}
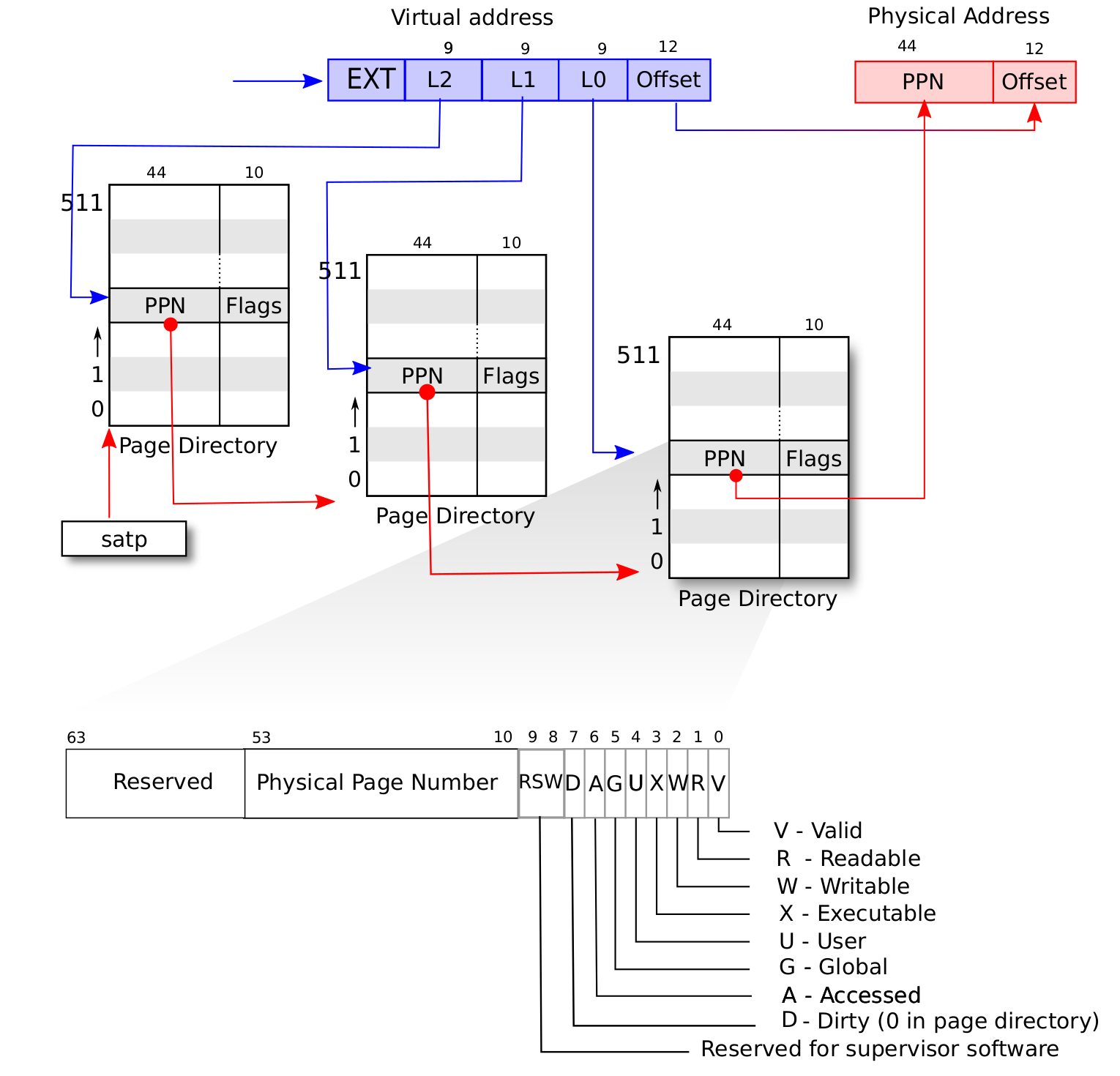
138.5 KB
docs/_images/sv39-pte.png
已删除
100644 → 0
{kind=link}

12.5 KB
docs/_images/sv39-va-pa.png
已删除
100644 → 0
{kind=link}

15.7 KB
docs/_images/switch-1.png
已删除
100644 → 0
{kind=link}
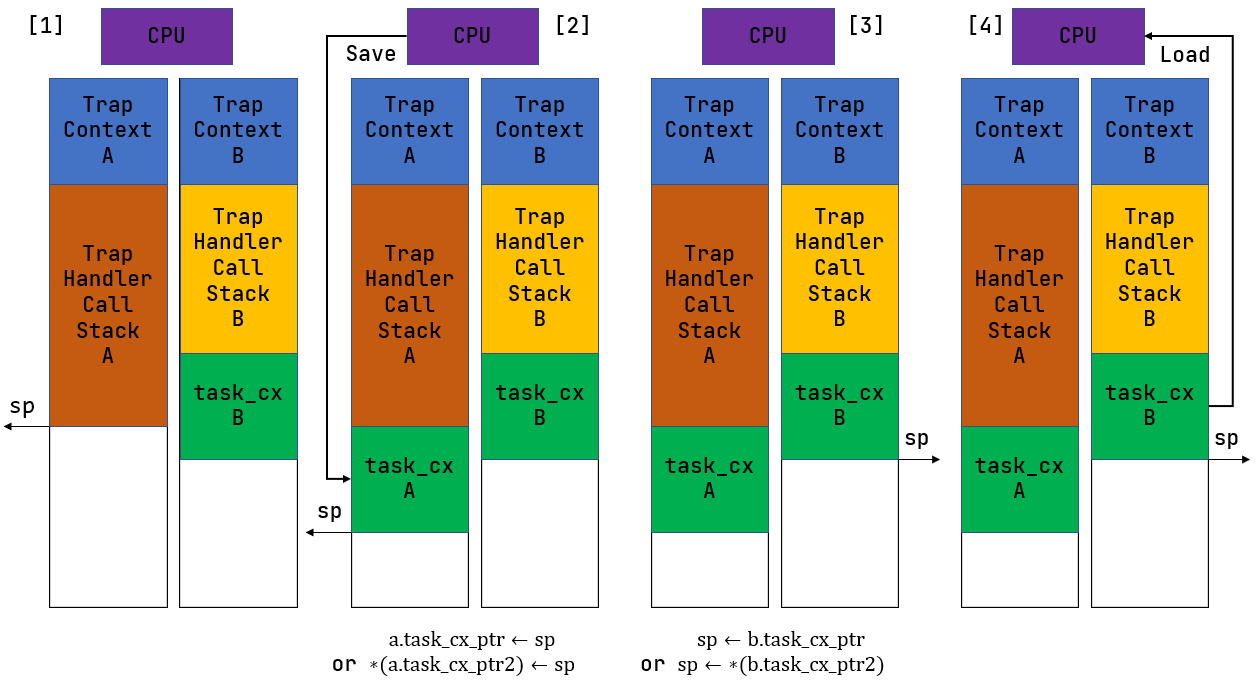
59.1 KB
docs/_images/switch-2.png
已删除
100644 → 0
{kind=link}
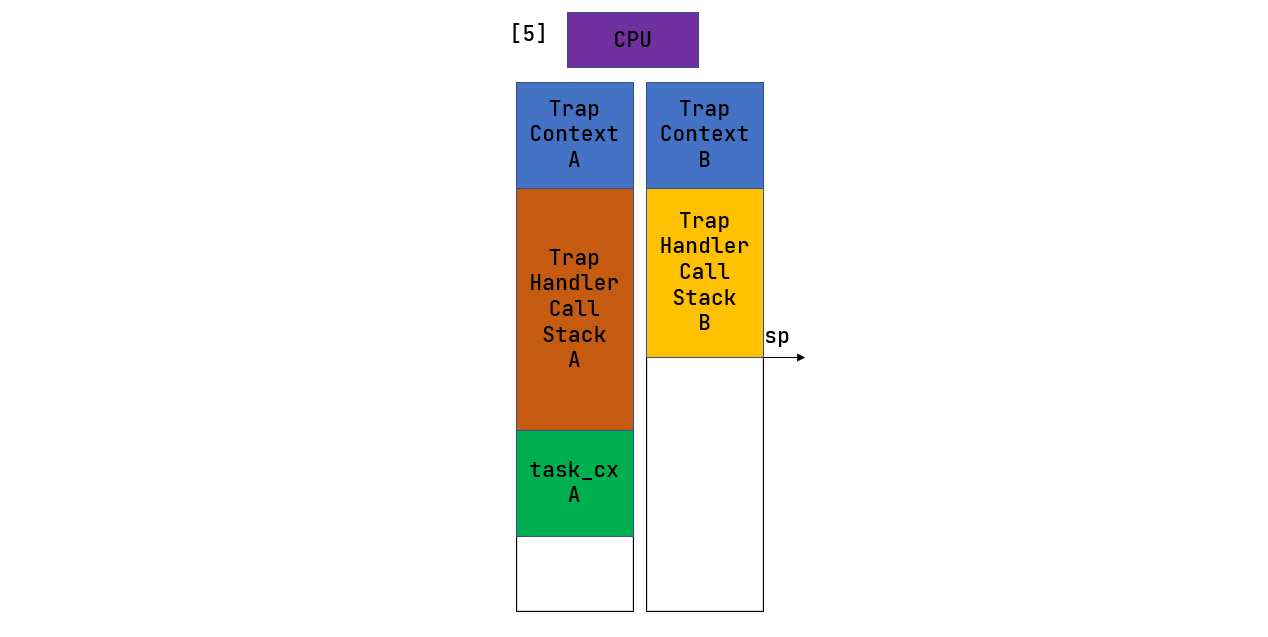
17.9 KB
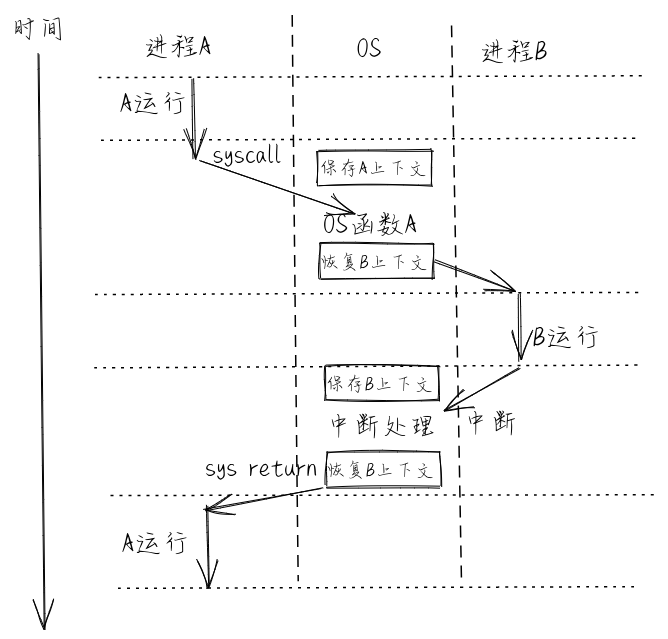
docs/_images/syscall.png
已删除
100644 → 0
{kind=link}
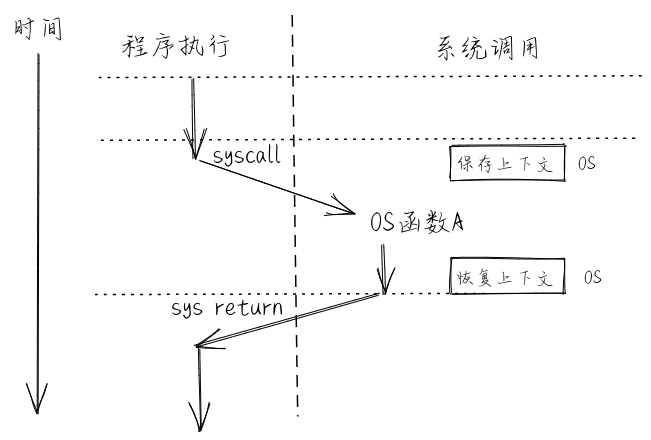
43.4 KB
docs/_images/task_context.png
已删除
100644 → 0
{kind=link}
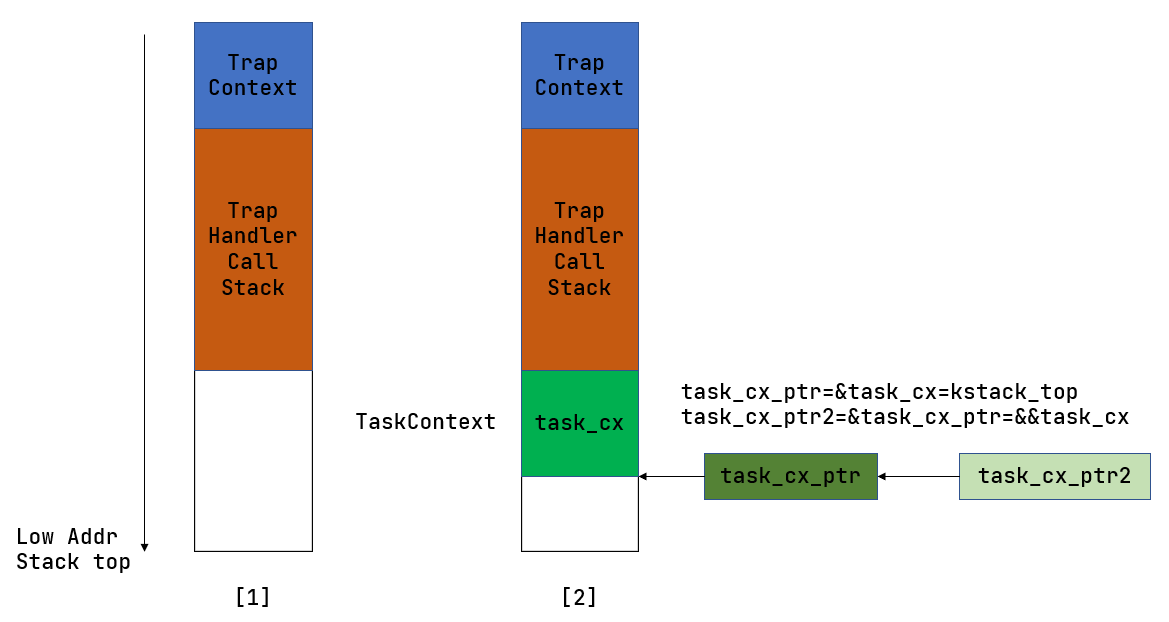
29.6 KB
docs/_images/test.gif
已删除
100644 → 0
{kind=link}
60.4 KB
docs/_images/trie-1.png
已删除
100644 → 0
{kind=link}
22.5 KB
docs/_images/trie.png
已删除
100644 → 0
{kind=link}
39.1 KB
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs/_sources/index.rst.txt
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs/_static/basic.css
已删除
100644 → 0
此差异已折叠。
文件已删除
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs/_static/css/theme.css
已删除
100644 → 0
此差异已折叠。
docs/_static/doctools.js
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
docs/_static/file.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
docs/_static/jquery-3.5.1.js
已删除
100644 → 0
此差异已折叠。
docs/_static/jquery.js
已删除
100644 → 0
此差异已折叠。
docs/_static/js/badge_only.js
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs/_static/js/theme.js
已删除
100644 → 0
此差异已折叠。
docs/_static/language_data.js
已删除
100644 → 0
此差异已折叠。
docs/_static/minus.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
docs/_static/plus.png
已删除
100644 → 0
{kind=link}
此差异已折叠。
docs/_static/pygments.css
已删除
100644 → 0
此差异已折叠。
docs/_static/searchtools.js
已删除
100644 → 0
此差异已折叠。
docs/_static/translations.js
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
docs/_static/underscore.js
已删除
100644 → 0
此差异已折叠。
docs/appendix-a/index.html
已删除
100644 → 0
此差异已折叠。
docs/appendix-b/index.html
已删除
100644 → 0
此差异已折叠。
docs/appendix-c/index.html
已删除
100644 → 0
此差异已折叠。
docs/appendix-d/1asm.html
已删除
100644 → 0
此差异已折叠。
docs/appendix-d/index.html
已删除
100644 → 0
此差异已折叠。
docs/chapter0/0intro.html
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs/chapter0/6hardware.html
已删除
100644 → 0
此差异已折叠。
docs/chapter0/index.html
已删除
100644 → 0
此差异已折叠。
docs/chapter1/0intro.html
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs/chapter1/index.html
已删除
100644 → 0
此差异已折叠。
docs/chapter2/0intro.html
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs/chapter2/index.html
已删除
100644 → 0
此差异已折叠。
docs/chapter3/0intro.html
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs/chapter3/index.html
已删除
100644 → 0
此差异已折叠。
docs/chapter4/0intro.html
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
docs/chapter4/index.html
已删除
100644 → 0
此差异已折叠。
docs/chapter5/index.html
已删除
100644 → 0
此差异已折叠。
docs/chapter6/index.html
已删除
100644 → 0
此差异已折叠。
docs/chapter7/index.html
已删除
100644 → 0
此差异已折叠。
docs/chapter8/index.html
已删除
100644 → 0
此差异已折叠。
docs/genindex.html
已删除
100644 → 0
此差异已折叠。
docs/index.html
已删除
100644 → 0
此差异已折叠。
docs/objects.inv
已删除
100644 → 0
此差异已折叠。
docs/rest-example.html
已删除
100644 → 0
此差异已折叠。
docs/search.html
已删除
100644 → 0
此差异已折叠。
docs/searchindex.js
已删除
100644 → 0
此差异已折叠。
docs/setup-sphinx.html
已删除
100644 → 0
此差异已折叠。
docs/terminology.html
已删除
100644 → 0
此差异已折叠。