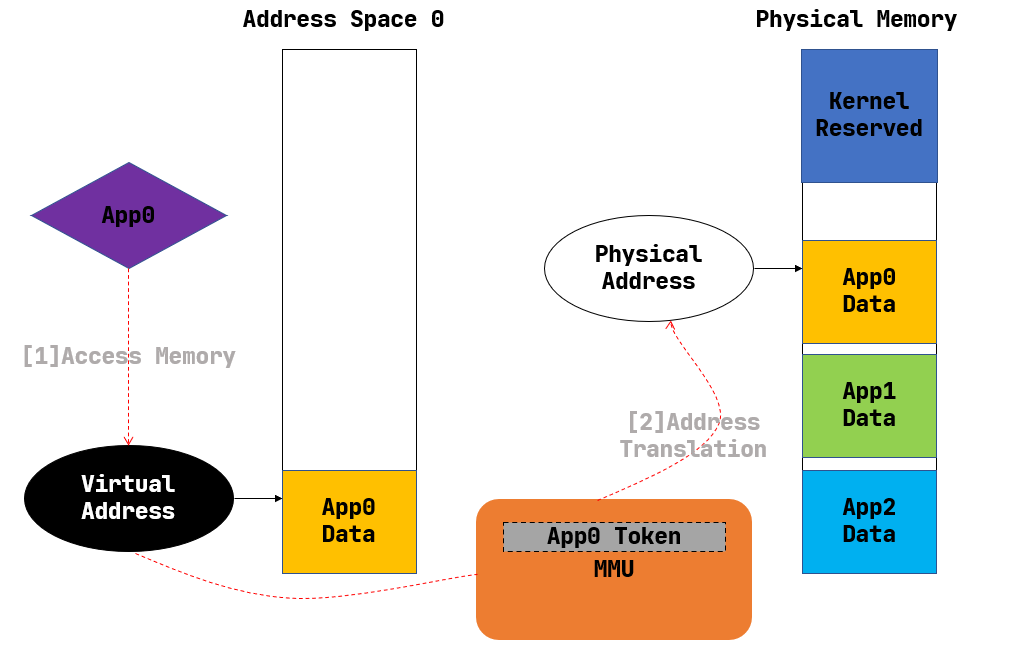
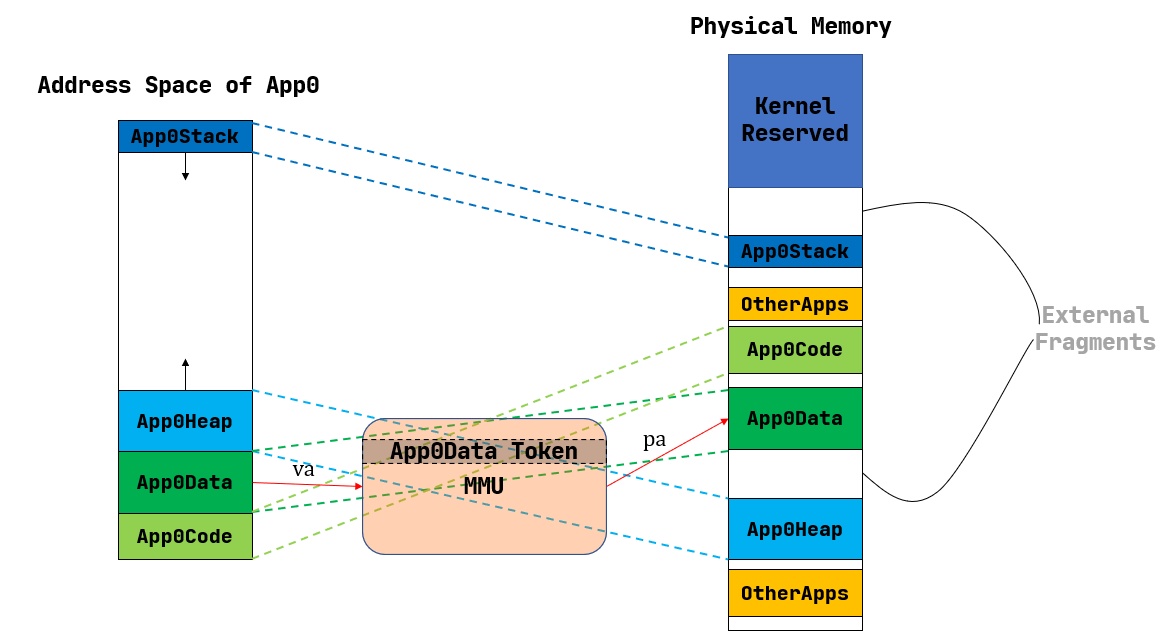
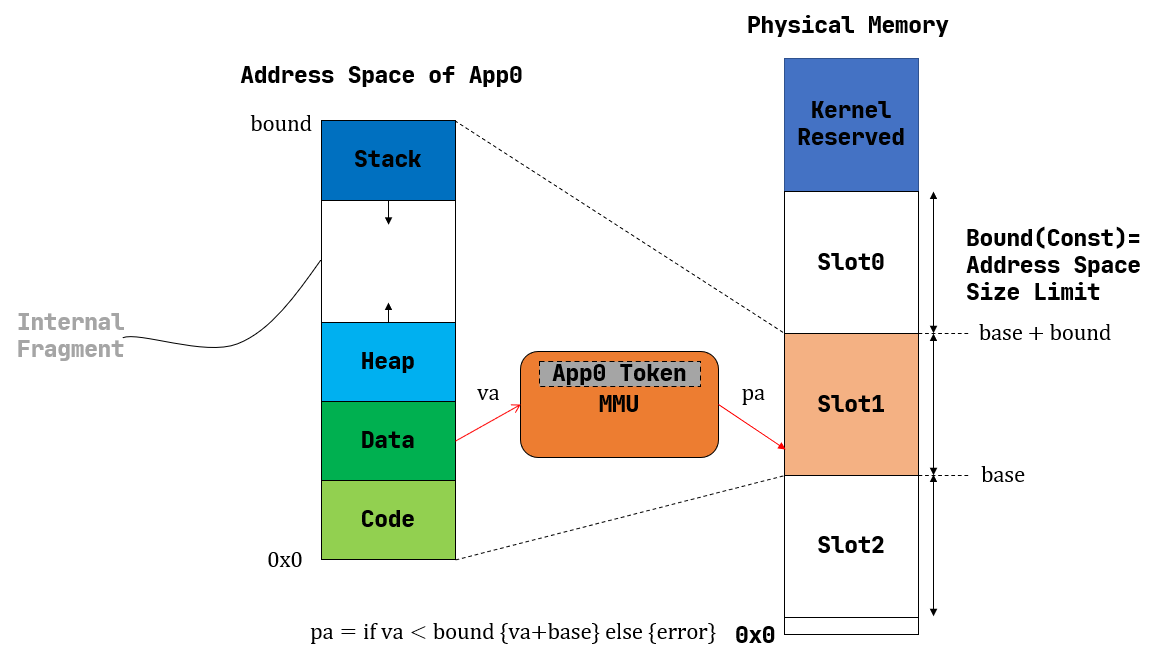
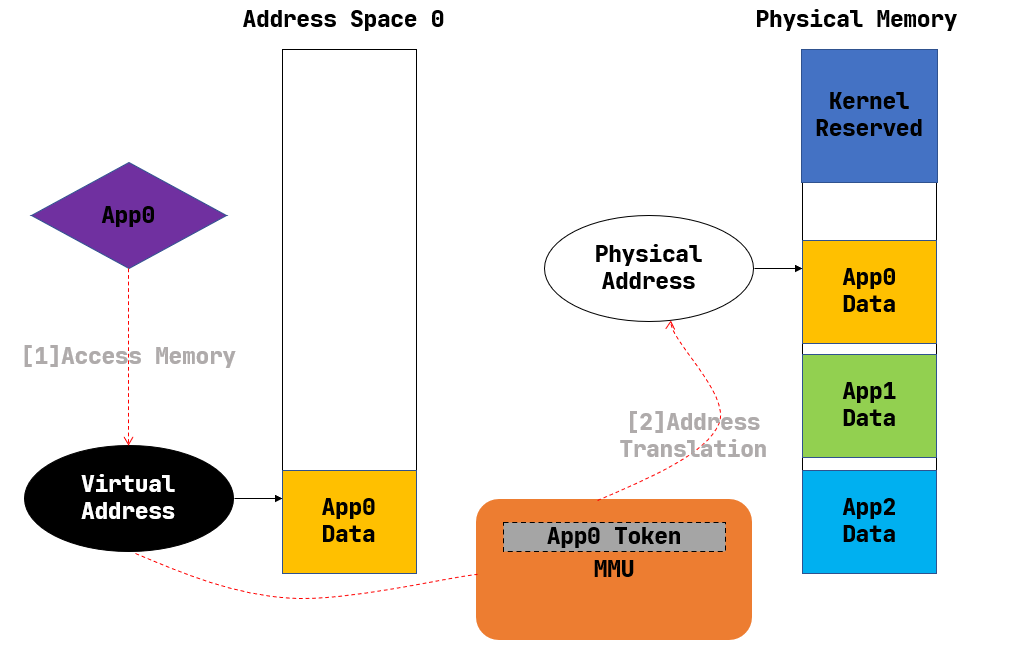
Segmentation completed.
Showing
{kind=link}
43.2 KB
docs/_images/segmentation.png
0 → 100644
{kind=link}
52.1 KB
{kind=link}
43.5 KB
无法预览此类型文件
此差异已折叠。
{kind=link}
43.2 KB
source/chapter4/segmentation.png
0 → 100644
{kind=link}
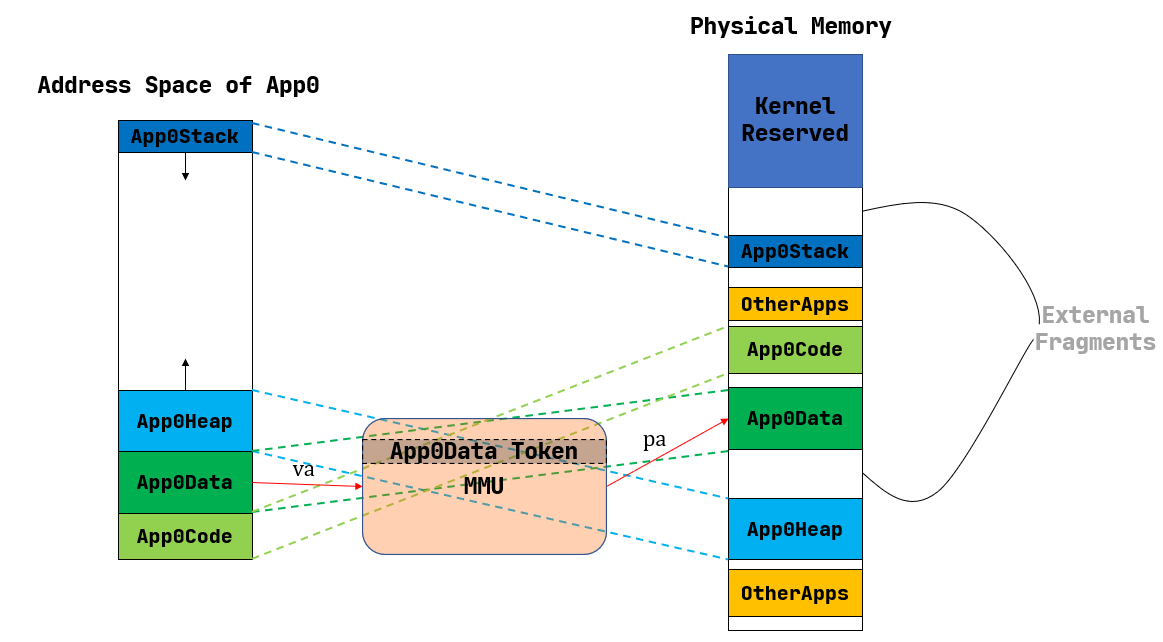
52.1 KB
{kind=link}
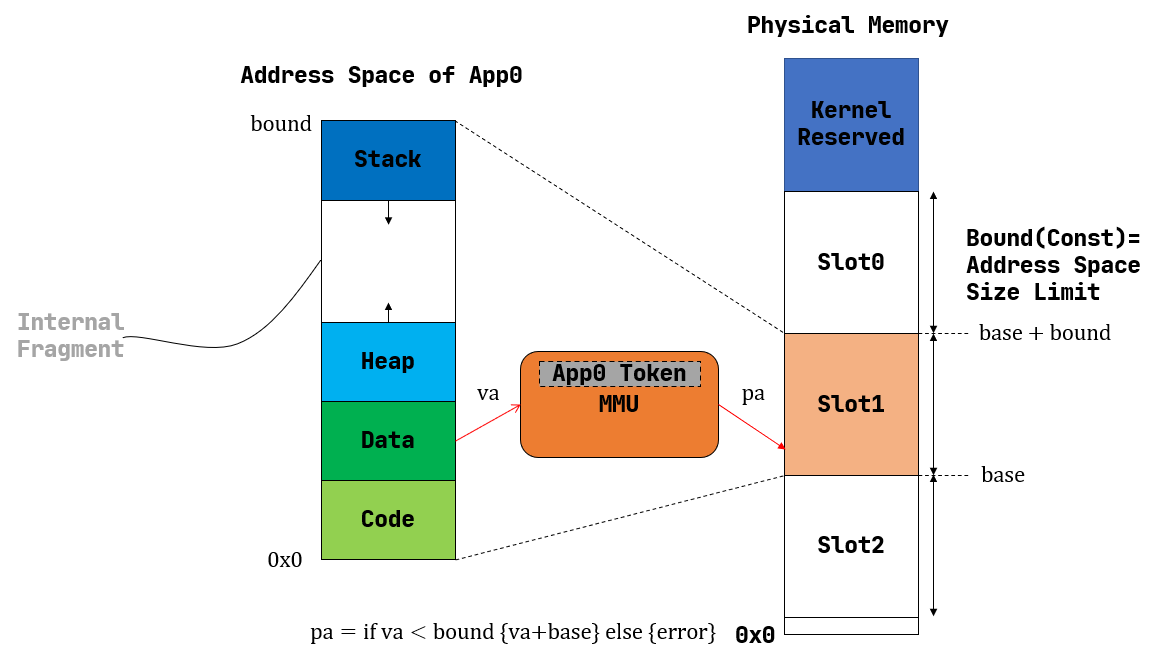
43.5 KB
43.2 KB
52.1 KB
43.5 KB
43.2 KB
52.1 KB
43.5 KB