If more than one ABIs will be used, seperate them by comas.
If more than one ABIs will be used, seperate them by comas.
* - target_socs
* - target_socs
- [optional] Build for specific SoCs.
- [optional] Build for specific SoCs.
* - embed_model_data
* - model_graph_format
- Whether embedding model weights into the code, default is 0.
- model graph format, could be 'file' or 'code'. 'file' for converting model graph to ProtoBuf file(.pb) and 'code' for converting model graph to c++ code.
* - build_type
* - model_data_format
- model build type, can be 'proto' or 'code'. 'proto' for converting model to ProtoBuf file and 'code' for converting model to c++ code.
- model data format, could be 'file' or 'code'. 'file' for converting model weight to data file(.data) and 'code' for converting model weight to c++ code.
* - linkshared
- [optional] 1 for building shared library, and 0 for static library, default to 0.
* - model_name
* - model_name
- model name, should be unique if there are more than one models.
- model name, should be unique if there are more than one models.
**LIMIT: if build_type is code, model_name will be used in c++ code so that model_name must comply with c++ name specification.**
**LIMIT: if build_type is code, model_name will be used in c++ code so that model_name must comply with c++ name specification.**
...
@@ -164,8 +162,7 @@ There are two common advanced use cases: 1. convert model to CPP code. 2. tuning
...
@@ -164,8 +162,7 @@ There are two common advanced use cases: 1. convert model to CPP code. 2. tuning
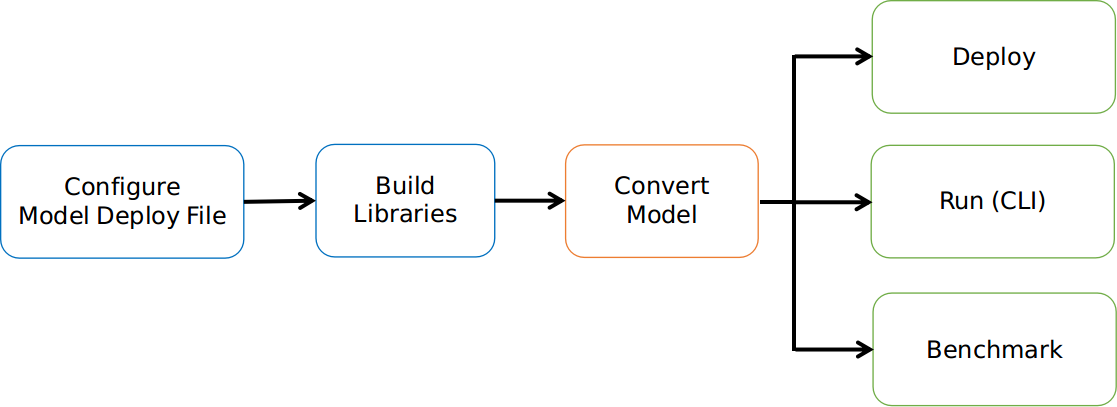
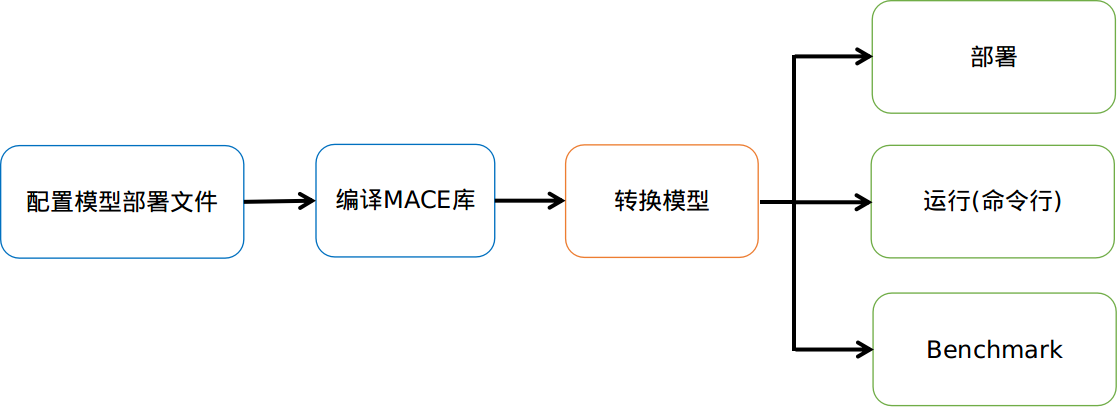
* **3. Deployment**
* **3. Deployment**
* Link `libmace.a` and `${library_name}.a` to your target.
* Link `libmace.a` and `${library_name}.a` to your target.
* Refer to \ ``mace/examples/example.cc``\ for full usage. The following list the key steps.
Please refer to \ ``mace/examples/example.cc``\ for full usage. The following list the key steps.
{kind=link}
{kind=link}