Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
Xiaomi
Mace
提交
1c874957
Mace
项目概览
Xiaomi
/
Mace
通知
107
Star
40
Fork
27
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
DevOps
流水线
流水线任务
计划
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
Mace
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
DevOps
DevOps
流水线
流水线任务
计划
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
流水线任务
提交
Issue看板
提交
1c874957
编写于
5月 17, 2018
作者:
刘
刘琦
浏览文件
操作
浏览文件
下载
差异文件
Merge branch 'docs' into 'master'
Add introduction into docs See merge request !476
上级
eb9bd231
5776efdb
变更
9
隐藏空白更改
内联
并排
Showing
9 changed file
with
89 addition
and
37 deletion
+89
-37
.gitlab-ci.yml
.gitlab-ci.yml
+2
-1
docs/faq.md
docs/faq.md
+11
-0
docs/getting_started/docker.md
docs/getting_started/docker.md
+0
-27
docs/getting_started/how_to_build.rst
docs/getting_started/how_to_build.rst
+30
-0
docs/getting_started/introduction.md
docs/getting_started/introduction.md
+0
-8
docs/getting_started/introduction.rst
docs/getting_started/introduction.rst
+46
-0
docs/getting_started/mace-arch.png
docs/getting_started/mace-arch.png
+0
-0
docs/getting_started/workflow.jpg
docs/getting_started/workflow.jpg
+0
-0
docs/index.rst
docs/index.rst
+0
-1
未找到文件。
.gitlab-ci.yml
浏览文件 @
1c874957
...
@@ -25,7 +25,8 @@ docs:
...
@@ -25,7 +25,8 @@ docs:
-
cd docs
-
cd docs
-
make html
-
make html
-
CI_LATEST_OUTPUT_PATH=/mace-build-output/$CI_PROJECT_NAME/latest
-
CI_LATEST_OUTPUT_PATH=/mace-build-output/$CI_PROJECT_NAME/latest
-
CI_JOB_OUTPUT_PATH=/mace-build-output/$CI_PROJECT_NAME/$CI_BUILD_ID
-
CI_JOB_OUTPUT_PATH=/mace-build-output/$CI_PROJECT_NAME/$CI_PIPELINE_ID
-
rm -rf $CI_JOB_OUTPUT_PATH
-
mkdir -p $CI_JOB_OUTPUT_PATH
-
mkdir -p $CI_JOB_OUTPUT_PATH
-
cp -r _build/html $CI_JOB_OUTPUT_PATH/docs
-
cp -r _build/html $CI_JOB_OUTPUT_PATH/docs
-
rm -rf $CI_LATEST_OUTPUT_PATH
-
rm -rf $CI_LATEST_OUTPUT_PATH
...
...
docs/faq.md
浏览文件 @
1c874957
Frequently asked questions
Frequently asked questions
==========================
==========================
Does the tensor data consume extra memory when compiled into C++ code?
----------------------------------------------------------------------
When compiled into C++ code, the data will be mmaped by the system loader.
For CPU runtime, the tensor data are used without memory copy.
For GPU and DSP runtime, the tensor data is used once during model
initialization. The operating system is free to swap the pages out, however,
it still consumes virtual memory space. So generally speaking, it takes
no extra physical memory. If you are short of virtual memory space (this
should be very rare), you can choose load the tensor data from a file, which
can be unmapped after initialization.
Why is the generated static library file size so huge?
Why is the generated static library file size so huge?
-------------------------------------------------------
-------------------------------------------------------
The static library is simply an archive of a set of object files which are
The static library is simply an archive of a set of object files which are
...
...
docs/getting_started/docker.md
已删除
100644 → 0
浏览文件 @
eb9bd231
Docker Images
=============
*
Login in
[
Xiaomi Docker Registry
](
http://docs.api.xiaomi.net/docker-registry/
)
```
docker login cr.d.xiaomi.net
```
*
Build with
`Dockerfile`
```
docker build -t cr.d.xiaomi.net/mace/mace-dev
```
*
Pull image from docker registry
```
docker pull cr.d.xiaomi.net/mace/mace-dev
```
*
Create container
```
# Set 'host' network to use ADB
docker run -it --rm -v /local/path:/container/path --net=host cr.d.xiaomi.net/mace/mace-dev /bin/bash
```
docs/getting_started/how_to_build.rst
浏览文件 @
1c874957
...
@@ -48,6 +48,36 @@ How to build
...
@@ -48,6 +48,36 @@ How to build
| docker(for caffe) | >= 17.09.0-ce | `install doc <https://docs.docker.com/install/linux/docker-ce/ubuntu/#set-up-the-repository>`__ |
| docker(for caffe) | >= 17.09.0-ce | `install doc <https://docs.docker.com/install/linux/docker-ce/ubuntu/#set-up-the-repository>`__ |
+---------------------+-----------------+---------------------------------------------------------------------------------------------------+
+---------------------+-----------------+---------------------------------------------------------------------------------------------------+
Docker Images
----------------
* Login in `Xiaomi Docker Registry <http://docs.api.xiaomi.net/docker-registry/>`__
.. code:: sh
docker login cr.d.xiaomi.net
* Build with Dockerfile
.. code:: sh
docker build -t cr.d.xiaomi.net/mace/mace-dev
* Pull image from docker registry
.. code:: sh
docker pull cr.d.xiaomi.net/mace/mace-dev
* Create container
.. code:: sh
# Set 'host' network to use ADB
docker run -it --rm -v /local/path:/container/path --net=host cr.d.xiaomi.net/mace/mace-dev /bin/bash
使用简介
使用简介
--------
--------
...
...
docs/getting_started/introduction.md
已删除
100644 → 0
浏览文件 @
eb9bd231
Introduction
============
TODO: describe the conceptions and workflow with diagram.

TODO: describe the runtime.
docs/getting_started/introduction.rst
0 → 100644
浏览文件 @
1c874957
Introduction
============
MiAI
Compute
Engine
is
a
deep
learning
inference
framework
optimized
for
mobile
heterogeneous
computing
platforms
.
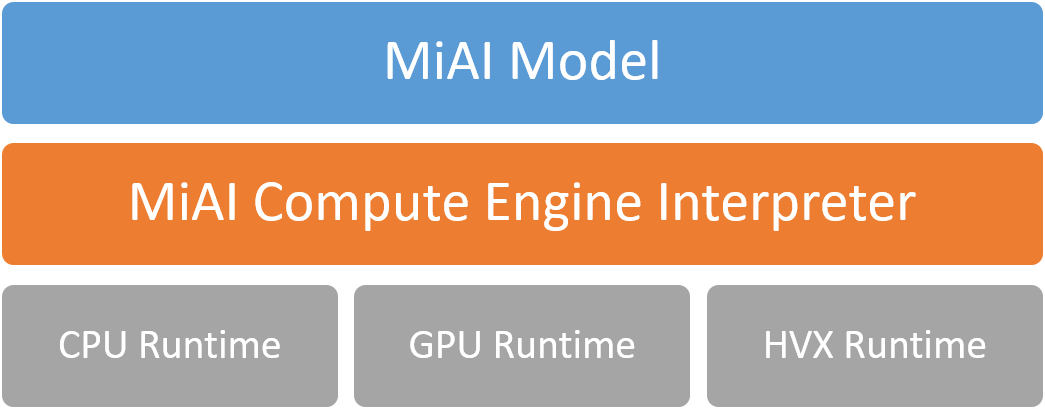
The
following
figure
shows
the
overall
architecture
.
..
image
::
mace
-
arch
.
png
:
scale
:
40
%
:
align
:
center
Model
format
------------
MiAI
Compute
Engine
defines
a
customized
model
format
which
is
similar
to
Caffe2
.
The
MiAI
model
can
be
converted
from
exported
models
by
TensorFlow
and
Caffe
.
We
define
a
YAML
schema
to
describe
the
model
deployment
.
In
the
next
chapter
,
there
is
a
detailed
guide
showing
how
to
create
this
YAML
file
.
Model
conversion
----------------
Currently
,
we
provide
model
converters
for
TensorFlow
and
Caffe
.
And
more
frameworks
will
be
supported
in
the
future
.
Model
loading
-------------
The
MiAI
model
format
contains
two
parts
:
the
model
graph
definition
and
the
model
parameter
tensors
.
The
graph
part
utilizes
Protocol
Buffers
for
serialization
.
All
the
model
parameter
tensors
are
concatenated
together
into
a
continuous
array
,
and
we
call
this
array
tensor
data
in
the
following
paragraphs
.
In
the
model
graph
,
the
tensor
data
offsets
and
lengths
are
recorded
.
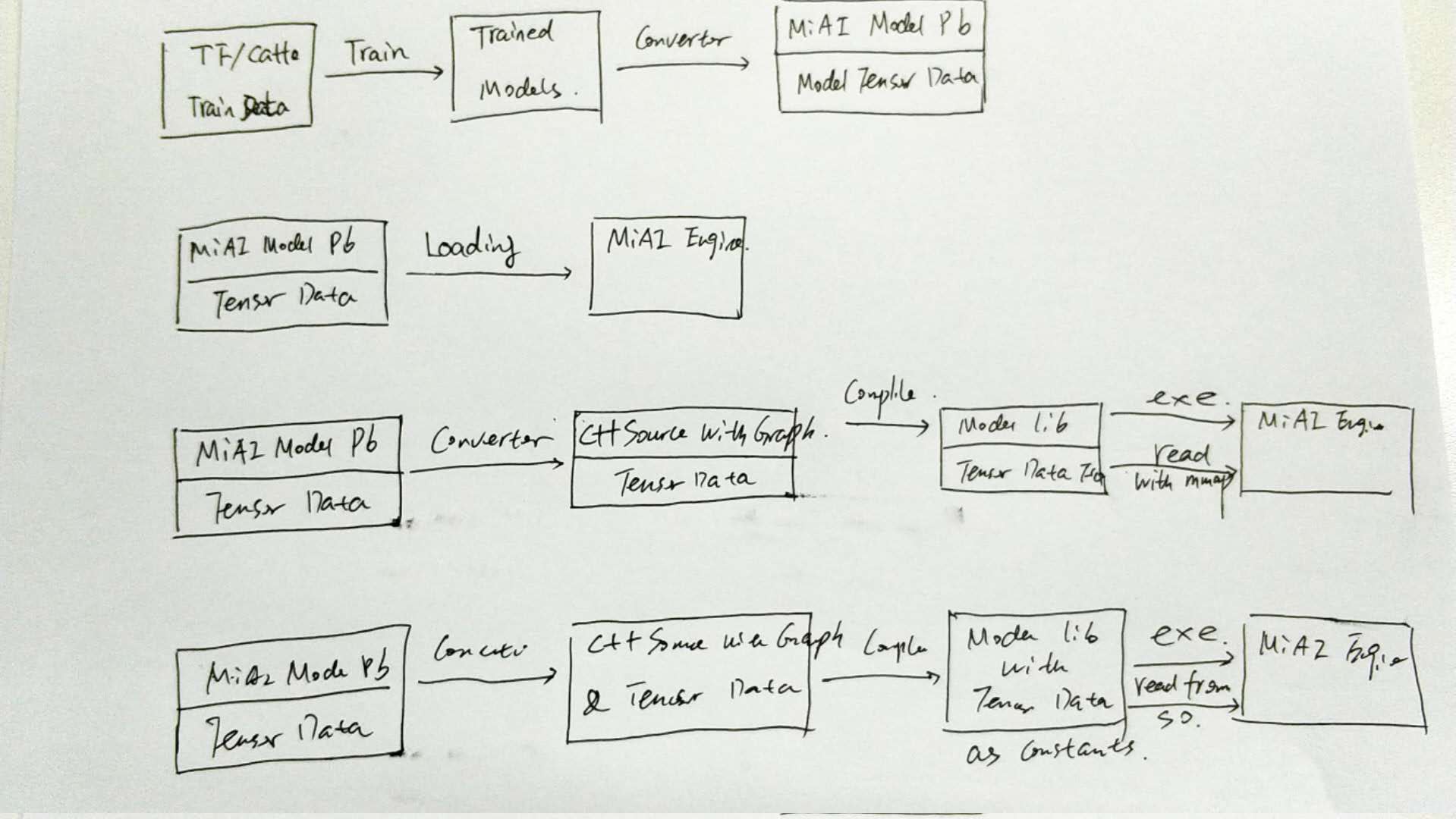
The
models
can
be
loaded
in
3
ways
:
1.
Both
model
graph
and
tensor
data
are
dynamically
loaded
externally
(
by
default
,
from
file
system
,
but
the
users
are
free
to
choose
their
own
implementations
,
for
example
,
with
compression
or
encryption
).
This
approach
provides
the
most
flexibility
but
the
weakest
model
protection
.
2.
Both
model
graph
and
tensor
data
are
converted
into
C
++
code
and
loaded
by
executing
the
compiled
code
.
This
approach
provides
the
strongest
model
protection
and
simplest
deployment
.
3.
The
model
graph
is
converted
into
C
++
code
and
constructed
as
the
second
approach
,
and
the
tensor
data
is
loaded
externally
as
the
first
approach
.
docs/getting_started/mace-arch.png
0 → 100644
浏览文件 @
1c874957
18.2 KB
docs/getting_started/workflow.jpg
已删除
100644 → 0
浏览文件 @
eb9bd231
116.3 KB
docs/index.rst
浏览文件 @
1c874957
...
@@ -11,7 +11,6 @@ The main documentation is organized into the following sections:
...
@@ -11,7 +11,6 @@ The main documentation is organized into the following sections:
getting_started/introduction
getting_started/introduction
getting_started/create_a_model_deployment
getting_started/create_a_model_deployment
getting_started/docker
getting_started/how_to_build
getting_started/how_to_build
getting_started/op_lists
getting_started/op_lists
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}
{kind=link}