Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
Coudy Hou
JavaGuide
提交
fbf3ce21
J
JavaGuide
项目概览
Coudy Hou
/
JavaGuide
与 Fork 源项目一致
从无法访问的项目Fork
通知
5
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
J
JavaGuide
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
fbf3ce21
编写于
1月 20, 2021
作者:
G
guide
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
Update zookeeper-plus.md
上级
348270b5
变更
1
隐藏空白更改
内联
并排
Showing
1 changed file
with
26 addition
and
26 deletion
+26
-26
docs/system-design/distributed-system/zookeeper/zookeeper-plus.md
...tem-design/distributed-system/zookeeper/zookeeper-plus.md
+26
-26
未找到文件。
docs/system-design/distributed-system/zookeeper/zookeeper-plus.md
浏览文件 @
fbf3ce21
...
...
@@ -47,7 +47,7 @@
`ZooKeeper`
由
`Yahoo`
开发,后来捐赠给了
`Apache`
,现已成为
`Apache`
顶级项目。
`ZooKeeper`
是一个开源的分布式应用程序协调服务器,其为分布式系统提供一致性服务。其一致性是通过基于
`Paxos`
算法的
`ZAB`
协议完成的。其主要功能包括:配置维护、分布式同步、集群管理、分布式事务等。


简单来说,
`ZooKeeper`
是一个
**分布式协调服务框架**
。分布式?协调服务?这啥玩意?🤔🤔
...
...
@@ -55,15 +55,15 @@
比如,我现在有一个秒杀服务,并发量太大单机系统承受不住,那我加几台服务器也
**一样**
提供秒杀服务,这个时候就是
**`Cluster` 集群**
。

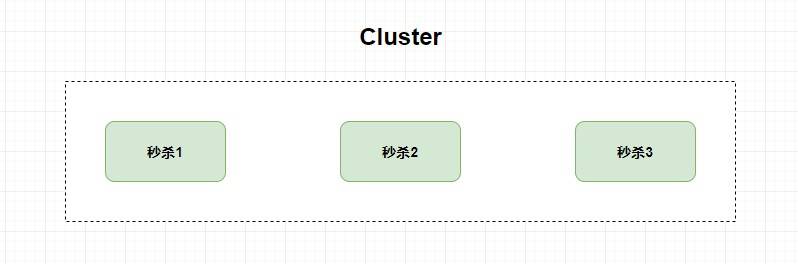
但是,我现在换一种方式,我将一个秒杀服务
**拆分成多个子服务**
,比如创建订单服务,增加积分服务,扣优惠券服务等等,
**然后我将这些子服务都部署在不同的服务器上**
,这个时候就是
**`Distributed` 分布式**
。


而我为什么反驳同学所说的分布式就是加机器呢?因为我认为加机器更加适用于构建集群,因为它真是只有加机器。而对于分布式来说,你首先需要将业务进行拆分,然后再加机器(不仅仅是加机器那么简单),同时你还要去解决分布式带来的一系列问题。


比如各个分布式组件如何协调起来,如何减少各个系统之间的耦合度,分布式事务的处理,如何去配置整个分布式系统等等。
`ZooKeeper`
主要就是解决这些问题的。
...
...
@@ -73,7 +73,7 @@
理解起来其实很简单,比如说把一个班级作为整个系统,而学生是系统中的一个个独立的子系统。这个时候班里的小红小明偷偷谈恋爱被班里的大嘴巴小花发现了,小花欣喜若狂告诉了周围的人,然后小红小明谈恋爱的消息在班级里传播起来了。当在消息的传播(散布)过程中,你抓到一个同学问他们的情况,如果回答你不知道,那么说明整个班级系统出现了数据不一致的问题(因为小花已经知道这个消息了)。而如果他直接不回答你,因为整个班级有消息在进行传播(为了保证一致性,需要所有人都知道才可提供服务),这个时候就出现了系统的可用性问题。


而上述前者就是
`Eureka`
的处理方式,它保证了AP(可用性),后者就是我们今天所要讲的
`ZooKeeper`
的处理方式,它保证了CP(数据一致性)。
...
...
@@ -83,7 +83,7 @@
这时候请你思考一个问题,同学之间如果采用传纸条的方式去传播消息,那么就会出现一个问题——我咋知道我的小纸条有没有传到我想要传递的那个人手中呢?万一被哪个小家伙给劫持篡改了呢,对吧?


这个时候就引申出一个概念——
**拜占庭将军问题**
。它意指
**在不可靠信道上试图通过消息传递的方式达到一致性是不可能的**
, 所以所有的一致性算法的
**必要前提**
就是安全可靠的消息通道。
...
...
@@ -109,11 +109,11 @@
而如果在第一阶段并不是所有参与者都返回了准备好了的消息,那么此时协调者将会给所有参与者发送
**回滚事务的 `rollback` 请求**
,参与者收到之后将会
**回滚它在第一阶段所做的事务处理**
,然后再将处理情况返回给协调者,最终协调者收到响应后便给事务发起者返回处理失败的结果。

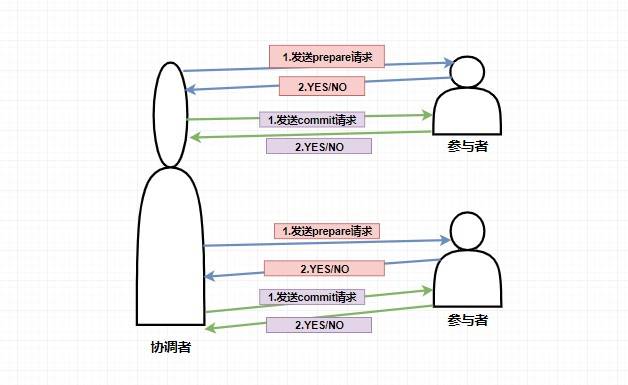
个人觉得 2PC 实现得还是比较鸡肋的,因为事实上它只解决了各个事务的原子性问题,随之也带来了很多的问题。


*
**单点故障问题**
,如果协调者挂了那么整个系统都处于不可用的状态了。
*
**阻塞问题**
,即当协调者发送
`prepare`
请求,参与者收到之后如果能处理那么它将会进行事务的处理但并不提交,这个时候会一直占用着资源不释放,如果此时协调者挂了,那么这些资源都不会再释放了,这会极大影响性能。
...
...
@@ -129,7 +129,7 @@
2.
**PreCommit阶段**
:协调者根据参与者返回的响应来决定是否可以进行下面的
`PreCommit`
操作。如果上面参与者返回的都是 YES,那么协调者将向所有参与者发送
`PreCommit`
预提交请求,
**参与者收到预提交请求后,会进行事务的执行操作,并将 `Undo` 和 `Redo` 信息写入事务日志中**
,最后如果参与者顺利执行了事务则给协调者返回成功的响应。如果在第一阶段协调者收到了
**任何一个 NO**
的信息,或者
**在一定时间内**
并没有收到全部的参与者的响应,那么就会中断事务,它会向所有参与者发送中断请求(abort),参与者收到中断请求之后会立即中断事务,或者在一定时间内没有收到协调者的请求,它也会中断事务。
3.
**DoCommit阶段**
:这个阶段其实和
`2PC`
的第二阶段差不多,如果协调者收到了所有参与者在
`PreCommit`
阶段的 YES 响应,那么协调者将会给所有参与者发送
`DoCommit`
请求,
**参与者收到 `DoCommit` 请求后则会进行事务的提交工作**
,完成后则会给协调者返回响应,协调者收到所有参与者返回的事务提交成功的响应之后则完成事务。若协调者在
`PreCommit`
阶段
**收到了任何一个 NO 或者在一定时间内没有收到所有参与者的响应**
,那么就会进行中断请求的发送,参与者收到中断请求后则会
**通过上面记录的回滚日志**
来进行事务的回滚操作,并向协调者反馈回滚状况,协调者收到参与者返回的消息后,中断事务。

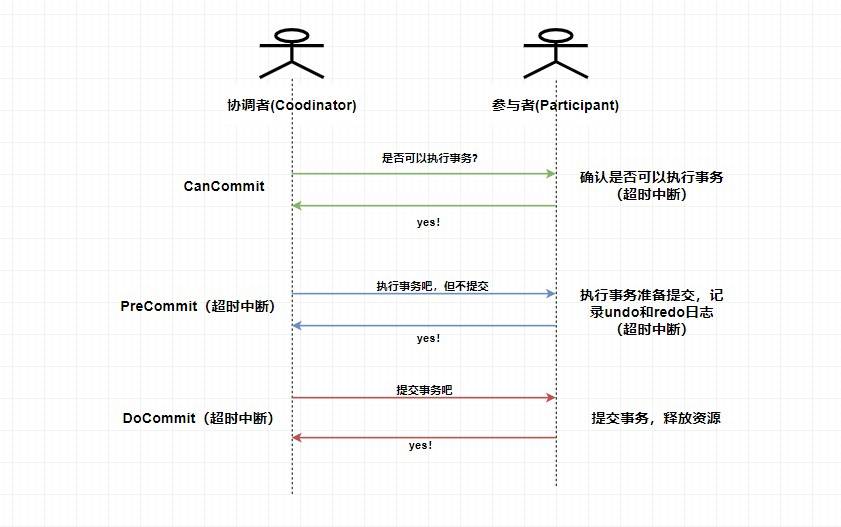
> 这里是 `3PC` 在成功的环境下的流程图,你可以看到 `3PC` 在很多地方进行了超时中断的处理,比如协调者在指定时间内为收到全部的确认消息则进行事务中断的处理,这样能 **减少同步阻塞的时间** 。还有需要注意的是,**`3PC` 在 `DoCommit` 阶段参与者如未收到协调者发送的提交事务的请求,它会在一定时间内进行事务的提交**。为什么这么做呢?是因为这个时候我们肯定**保证了在第一阶段所有的协调者全部返回了可以执行事务的响应**,这个时候我们有理由**相信其他系统都能进行事务的执行和提交**,所以**不管**协调者有没有发消息给参与者,进入第三阶段参与者都会进行事务的提交操作。
...
...
@@ -150,7 +150,7 @@
> 下面是 `prepare` 阶段的流程图,你可以对照着参考一下。

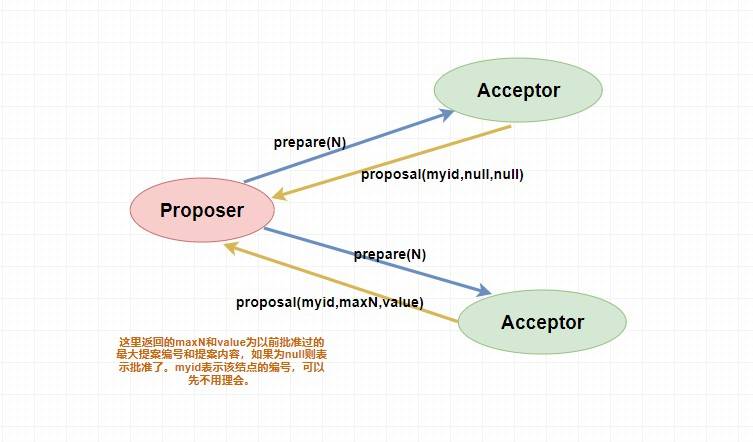
#### 4.3.2. accept 阶段
...
...
@@ -158,11 +158,11 @@
表决者收到提案请求后会再次比较本身已经批准过的最大提案编号和该提案编号,如果该提案编号
**大于等于**
已经批准过的最大提案编号,那么就
`accept`
该提案(此时执行提案内容但不提交),随后将情况返回给
`Proposer`
。如果不满足则不回应或者返回 NO 。


当
`Proposer`
收到超过半数的
`accept`
,那么它这个时候会向所有的
`acceptor`
发送提案的提交请求。需要注意的是,因为上述仅仅是超过半数的
`acceptor`
批准执行了该提案内容,其他没有批准的并没有执行该提案内容,所以这个时候需要
**向未批准的 `acceptor` 发送提案内容和提案编号并让它无条件执行和提交**
,而对于前面已经批准过该提案的
`acceptor`
来说
**仅仅需要发送该提案的编号**
,让
`acceptor`
执行提交就行了。

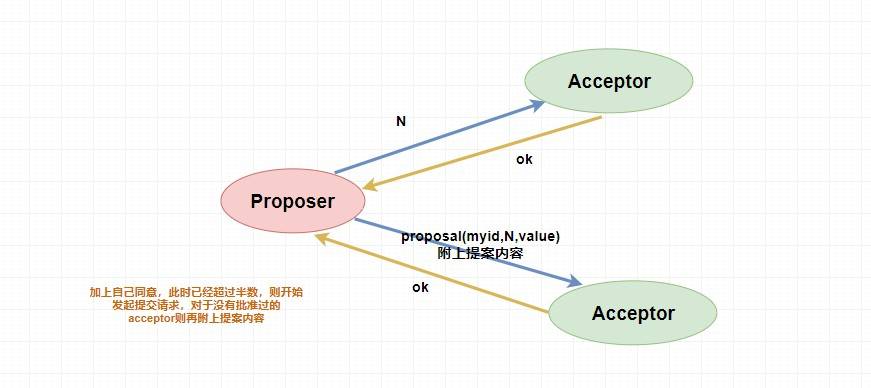
而如果
`Proposer`
如果没有收到超过半数的
`accept`
那么它将会将
**递增**
该
`Proposal`
的编号,然后
**重新进入 `Prepare` 阶段**
。
...
...
@@ -176,7 +176,7 @@
就这样无休无止的永远提案下去,这就是
`paxos`
算法的死循环问题。


那么如何解决呢?很简单,人多了容易吵架,我现在
**就允许一个能提案**
就行了。
...
...
@@ -186,7 +186,7 @@
作为一个优秀高效且可靠的分布式协调框架,
`ZooKeeper`
在解决分布式数据一致性问题时并没有直接使用
`Paxos`
,而是专门定制了一致性协议叫做
`ZAB(ZooKeeper Automic Broadcast)`
原子广播协议,该协议能够很好地支持
**崩溃恢复**
。

### 5.2. `ZAB` 中的三个角色
...
...
@@ -204,11 +204,11 @@
不就是
**在整个集群中保持数据的一致性**
嘛?如果是你,你会怎么做呢?


废话,第一步肯定需要
`Leader`
将写请求
**广播**
出去呀,让
`Leader`
问问
`Followers`
是否同意更新,如果超过半数以上的同意那么就进行
`Follower`
和
`Observer`
的更新(和
`Paxos`
一样)。当然这么说有点虚,画张图理解一下。

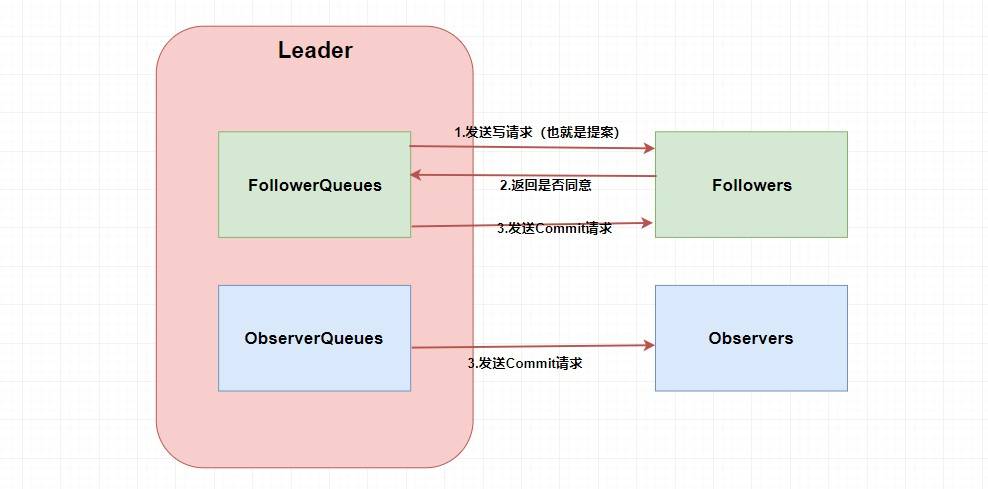
嗯。。。看起来很简单,貌似懂了🤥🤥🤥。这两个
`Queue`
哪冒出来的?答案是
**`ZAB` 需要让 `Follower` 和 `Observer` 保证顺序性**
。何为顺序性,比如我现在有一个写请求A,此时
`Leader`
将请求A广播出去,因为只需要半数同意就行,所以可能这个时候有一个
`Follower`
F1因为网络原因没有收到,而
`Leader`
又广播了一个请求B,因为网络原因,F1竟然先收到了请求B然后才收到了请求A,这个时候请求处理的顺序不同就会导致数据的不同,从而
**产生数据不一致问题**
。
...
...
@@ -250,7 +250,7 @@
假设
`Leader (server2)`
发送
`commit`
请求(忘了请看上面的消息广播模式),他发送给了
`server3`
,然后要发给
`server1`
的时候突然挂了。这个时候重新选举的时候我们如果把
`server1`
作为
`Leader`
的话,那么肯定会产生数据不一致性,因为
`server3`
肯定会提交刚刚
`server2`
发送的
`commit`
请求的提案,而
`server1`
根本没收到所以会丢弃。

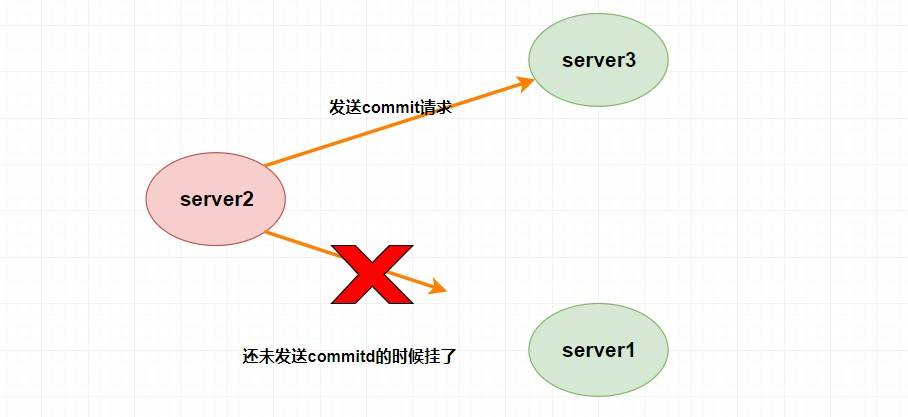
那怎么解决呢?
...
...
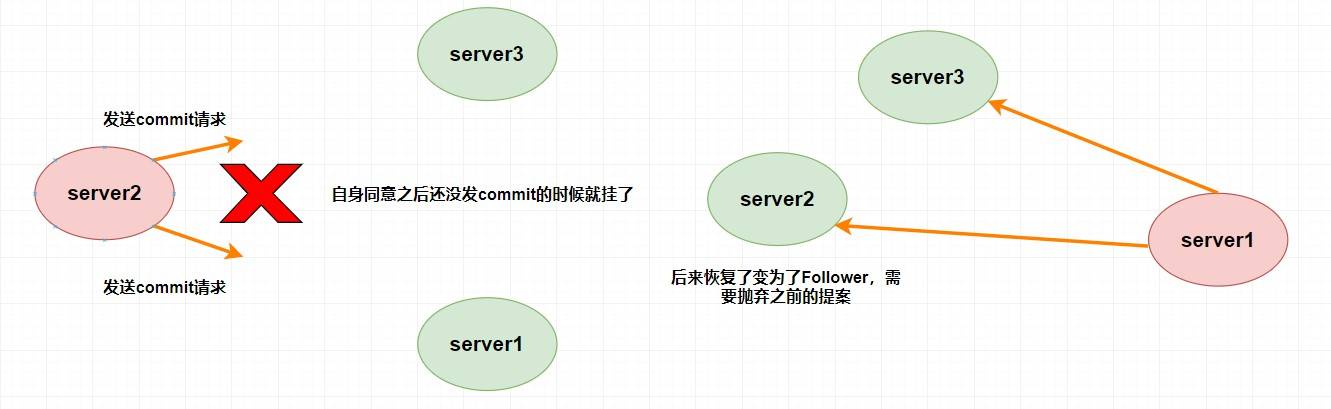
@@ -260,7 +260,7 @@
假设
`Leader (server2)`
此时同意了提案N1,自身提交了这个事务并且要发送给所有
`Follower`
要
`commit`
的请求,却在这个时候挂了,此时肯定要重新进行
`Leader`
的选举,比如说此时选
`server1`
为
`Leader`
(这无所谓)。但是过了一会,这个
**挂掉的 `Leader` 又重新恢复了**
,此时它肯定会作为
`Follower`
的身份进入集群中,需要注意的是刚刚
`server2`
已经同意提交了提案N1,但其他
`server`
并没有收到它的
`commit`
信息,所以其他
`server`
不可能再提交这个提案N1了,这样就会出现数据不一致性问题了,所以
**该提案N1最终需要被抛弃掉**
。

## 6. Zookeeper的几个理论知识
...
...
@@ -272,7 +272,7 @@
`zookeeper`
数据存储结构与标准的
`Unix`
文件系统非常相似,都是在根节点下挂很多子节点(树型)。但是
`zookeeper`
中没有文件系统中目录与文件的概念,而是
**使用了 `znode` 作为数据节点**
。
`znode`
是
`zookeeper`
中的最小数据单元,每个
`znode`
上都可以保存数据,同时还可以挂载子节点,形成一个树形化命名空间。

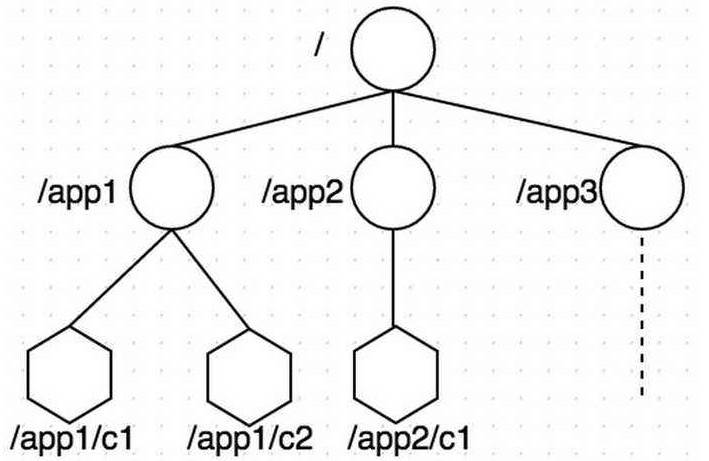
每个
`znode`
都有自己所属的
**节点类型**
和
**节点状态**
。
...
...
@@ -317,13 +317,13 @@
`Watcher`
为事件监听器,是
`zk`
非常重要的一个特性,很多功能都依赖于它,它有点类似于订阅的方式,即客户端向服务端
**注册**
指定的
`watcher`
,当服务端符合了
`watcher`
的某些事件或要求则会
**向客户端发送事件通知**
,客户端收到通知后找到自己定义的
`Watcher`
然后
**执行相应的回调方法**
。

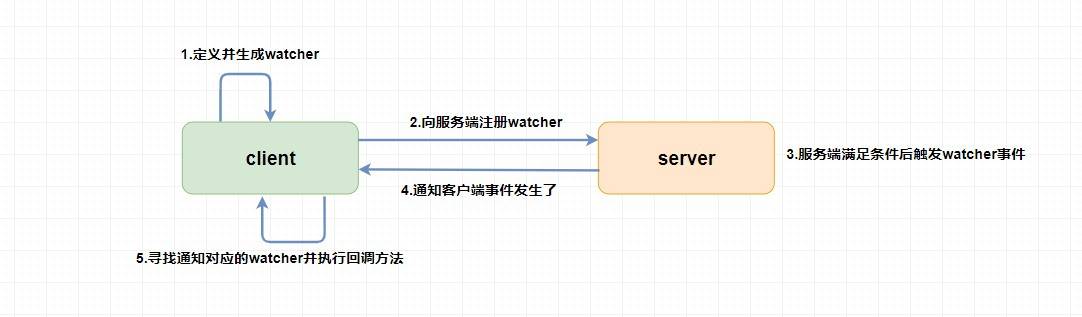
## 7. Zookeeper的几个典型应用场景
前面说了这么多的理论知识,你可能听得一头雾水,这些玩意有啥用?能干啥事?别急,听我慢慢道来。


### 7.1. 选主
...
...
@@ -335,7 +335,7 @@
你想想为什么我们要创建临时节点?还记得临时节点的生命周期吗?
`master`
挂了是不是代表会话断了?会话断了是不是意味着这个节点没了?还记得
`watcher`
吗?我们是不是可以
**让其他不是 `master` 的节点监听节点的状态**
,比如说我们监听这个临时节点的父节点,如果子节点个数变了就代表
`master`
挂了,这个时候我们
**触发回调函数进行重新选举**
,或者我们直接监听节点的状态,我们可以通过节点是否已经失去连接来判断
`master`
是否挂了等等。

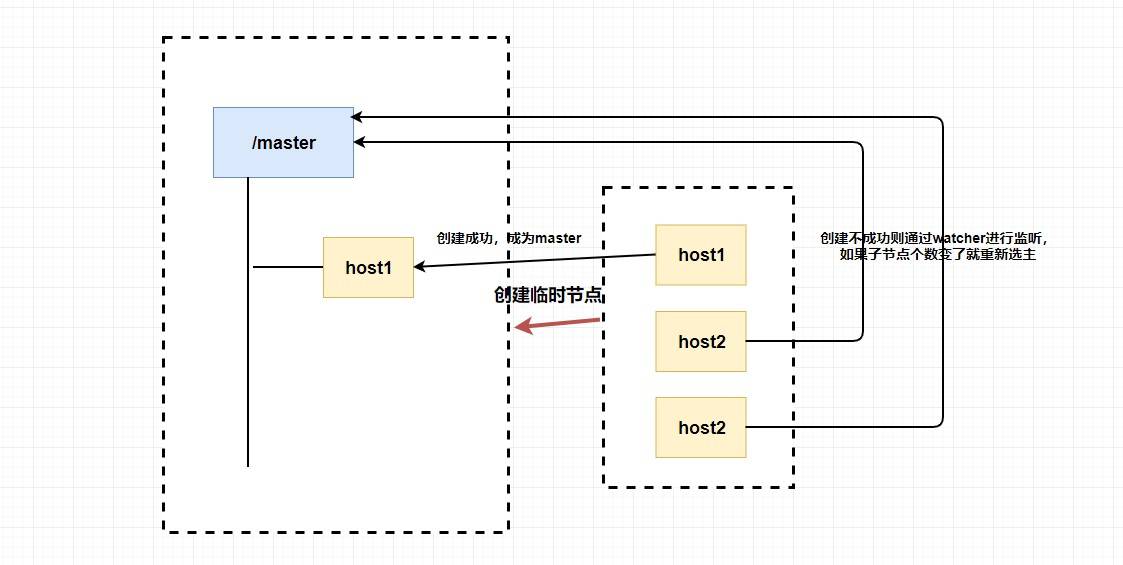
总的来说,我们可以完全
**利用 临时节点、节点状态 和 `watcher` 来实现选主的功能**
,临时节点主要用来选举,节点状态和
`watcher`
可以用来判断
`master`
的活性和进行重新选举。
...
...
@@ -377,13 +377,13 @@
而
`zookeeper`
天然支持的
`watcher`
和 临时节点能很好的实现这些需求。我们可以为每条机器创建临时节点,并监控其父节点,如果子节点列表有变动(我们可能创建删除了临时节点),那么我们可以使用在其父节点绑定的
`watcher`
进行状态监控和回调。


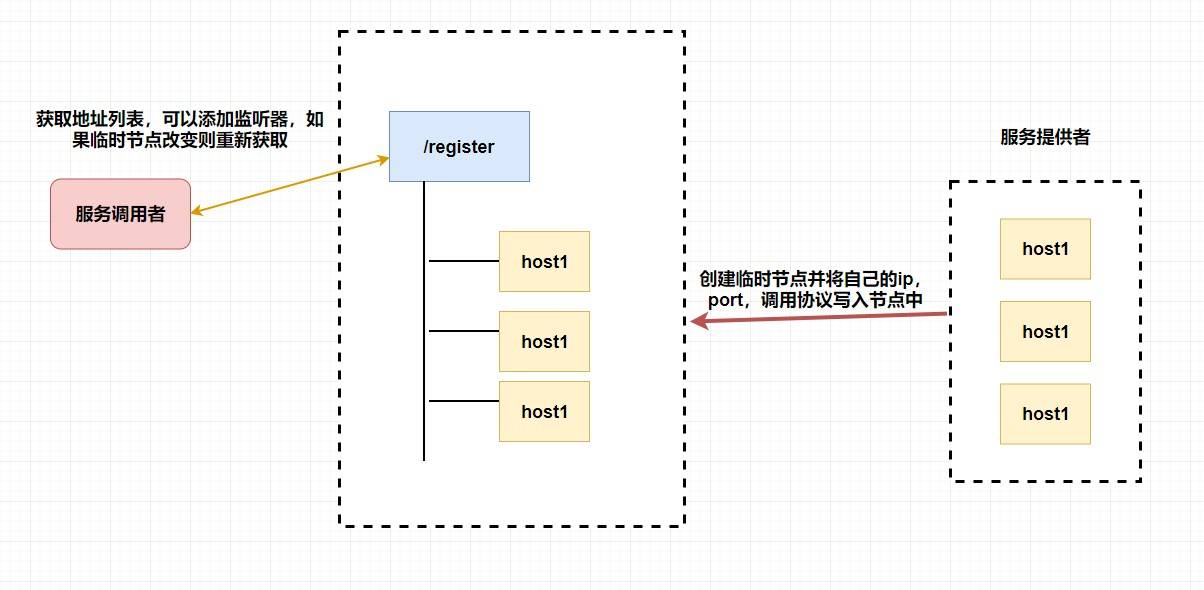
至于注册中心也很简单,我们同样也是让
**服务提供者**
在
`zookeeper`
中创建一个临时节点并且将自己的
`ip、port、调用方式`
写入节点,当
**服务消费者**
需要进行调用的时候会
**通过注册中心找到相应的服务的地址列表(IP端口什么的)**
,并缓存到本地(方便以后调用),当消费者调用服务时,不会再去请求注册中心,而是直接通过负载均衡算法从地址列表中取一个服务提供者的服务器调用服务。
当服务提供者的某台服务器宕机或下线时,相应的地址会从服务提供者地址列表中移除。同时,注册中心会将新的服务地址列表发送给服务消费者的机器并缓存在消费者本机(当然你可以让消费者进行节点监听,我记得
`Eureka`
会先试错,然后再更新)。

## 8. 总结
...
...
@@ -391,7 +391,7 @@
不知道大家是否还记得我讲了什么😒。


这篇文章中我带大家入门了
`zookeeper`
这个强大的分布式协调框架。现在我们来简单梳理一下整篇文章的内容。
...
...
@@ -405,4 +405,4 @@
*
`zookeeper`
的典型应用场景,比如选主,注册中心等等。
如果忘了可以回去看看再次理解一下,如果有疑问和建议欢迎提出🤝🤝🤝。
如果忘了可以回去看看再次理解一下,如果有疑问和建议欢迎提出🤝🤝🤝。
\ No newline at end of file
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录