Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
Coudy Hou
JavaGuide
提交
d54ddaee
J
JavaGuide
项目概览
Coudy Hou
/
JavaGuide
与 Fork 源项目一致
从无法访问的项目Fork
通知
5
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
J
JavaGuide
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
体验新版 GitCode,发现更多精彩内容 >>
提交
d54ddaee
编写于
3月 13, 2020
作者:
S
shuang.kou
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
[update]索引部分内容更改
上级
dc0d7553
变更
2
隐藏空白更改
内联
并排
Showing
2 changed file
with
72 addition
and
12 deletion
+72
-12
README.md
README.md
+1
-1
docs/database/MySQL Index.md
docs/database/MySQL Index.md
+71
-11
未找到文件。
README.md
浏览文件 @
d54ddaee
...
...
@@ -188,7 +188,7 @@ Github用户如果访问速度缓慢的话,可以转移到[码云](https://git
2.
**[阿里巴巴开发手册数据库部分的一些最佳实践](docs/database/阿里巴巴开发手册数据库部分的一些最佳实践.md)**
3.
**[一千行MySQL学习笔记](docs/database/一千行MySQL命令.md)**
4.
[
MySQL高性能优化规范建议
](
docs/database/MySQL高性能优化规范建议.md
)
5.
[
数据库索引总结
](
docs/database/MySQL%20Index
.md
)
5.
[
数据库索引总结
1
](
docs/database/MySQL%20Index.md
)
、
[
数据库索引总结2
](
docs/database/数据库索引
.md
)
6.
[
事务隔离级别(图文详解)
](
docs/database/事务隔离级别(图文详解
)
.md)
7.
[
一条SQL语句在MySQL中如何执行的
](
docs/database/一条sql语句在mysql中如何执行的.md
)
...
...
docs/database/MySQL Index.md
浏览文件 @
d54ddaee
## 为什么要使用索引?
# 思维导图-索引篇
1.
通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
2.
可以大大加快 数据的检索速度(大大减少的检索的数据量), 这也是创建索引的最主要的原因。
3.
帮助服务器避免排序和临时表。
4.
将随机IO变为顺序IO
5.
可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
> 系列思维导图源文件(数据库+架构)以及思维导图制作软件—XMind8 破解安装,公众号后台回复:**“思维导图”** 免费领取!(下面的图片不是很清楚,原图非常清晰,另外提供给大家源文件也是为了大家根据自己需要进行修改)
## 索引这么多优点,为什么不对表中的每一个列创建一个索引呢?
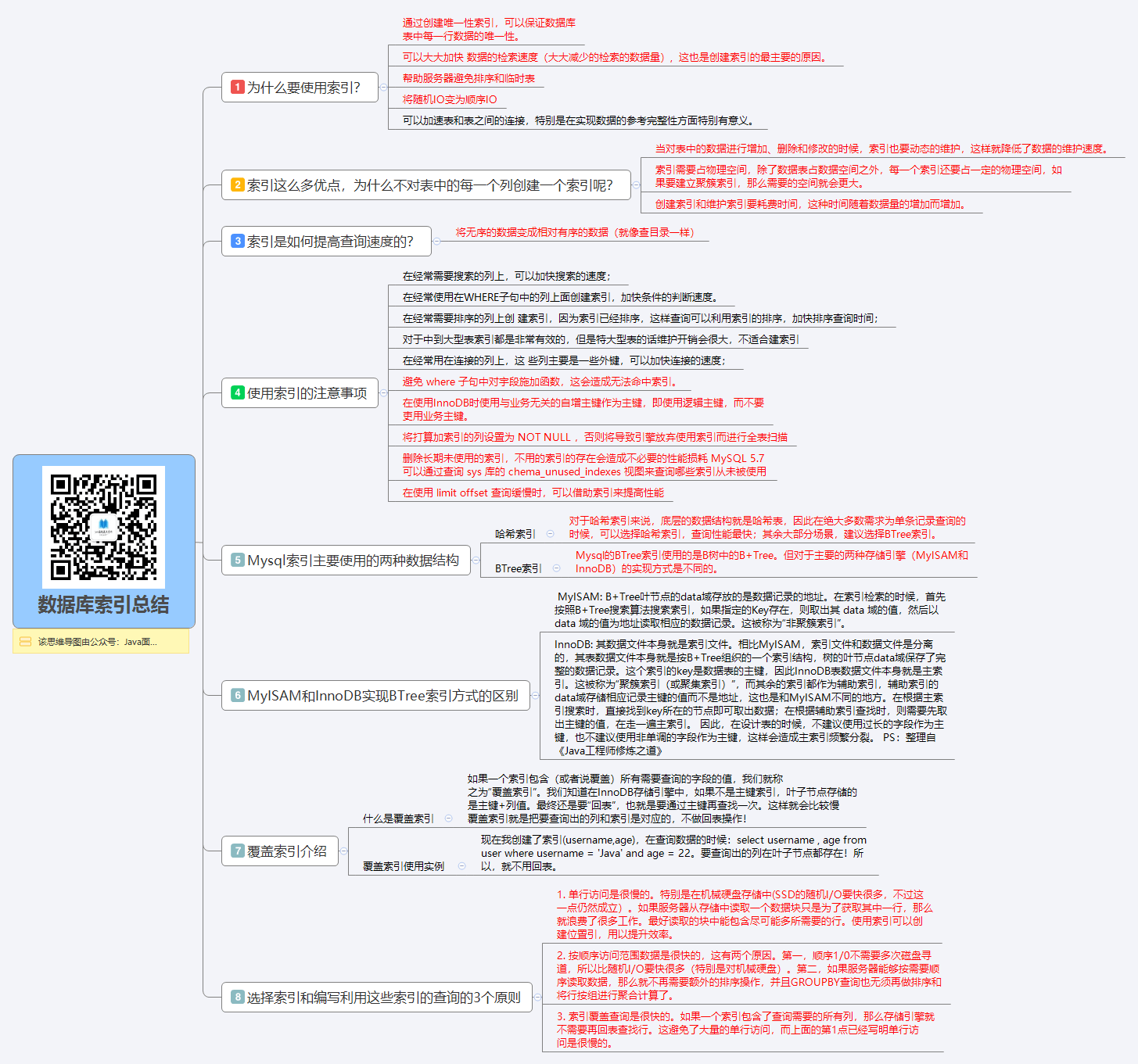
1.
当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
2.
索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
3.
创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
> **下面是我补充的一些内容**
## 使用索引的注意事项?
# 为什么索引能提高查询速度
1.
在经常需要搜索的列上,可以加快搜索的速度;
2.
在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
3.
在经常需要排序的列上创 建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;
4.
对于中到大型表索引都是非常有效的,但是特大型表的话维护开销会很大,不适合建索引
5.
在经常用在连接的列上,这 些列主要是一些外键,可以加快连接的速度;
6.
避免 where 子句中对宇段施加函数,这会造成无法命中索引。
7.
在使用InnoDB时使用与业务无关的自增主键作为主键,即使用逻辑主键,而不要使用业务主键。
8.
将打算加索引的列设置为 NOT NULL ,否则将导致引擎放弃使用索引而进行全表扫描
9.
删除长期未使用的索引,不用的索引的存在会造成不必要的性能损耗 MySQL 5.7 可以通过查询 sys 库的 chema_unused_indexes 视图来查询哪些索引从未被使用
10.
在使用 limit offset 查询缓慢时,可以借助索引来提高性能
## Mysql索引主要使用的两种数据结构
### 哈希索引
对于哈希索引来说,底层的数据结构就是哈希表,因此在绝大多数需求为单条记录查询的时候,可以选择哈希索引,查询性能最快;其余大部分场景,建议选择BTree索引。
### BTree索引
## MyISAM和InnoDB实现BTree索引方式的区别
### MyISAM
B+Tree叶节点的data域存放的是数据记录的地址。在索引检索的时候,首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其 data 域的值,然后以 data 域的值为地址读取相应的数据记录。这被称为“非聚簇索引”。
### InnoDB
其数据文件本身就是索引文件。相比MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按B+Tree组织的一个索引结构,树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。这被称为“聚簇索引(或聚集索引)”,而其余的索引都作为辅助索引,辅助索引的data域存储相应记录主键的值而不是地址,这也是和MyISAM不同的地方。在根据主索引搜索时,直接找到key所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,在走一遍主索引。 因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。 PS:整理自《Java工程师修炼之道》
## 覆盖索引介绍
### 什么是覆盖索引
如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为“覆盖索引”。我们知道InnoDB存储引擎中,如果不是主键索引,叶子节点存储的是主键+列值。最终还是要“回表”,也就是要通过主键再查找一次。这样就会比较慢覆盖索引就是把要查询出的列和索引是对应的,不做回表操作!
### 覆盖索引使用实例
现在我创建了索引(username,age),我们执行下面的 sql 语句
```
sql
select
username
,
age
from
user
where
username
=
'Java'
and
age
=
22
```
在查询数据的时候:要查询出的列在叶子节点都存在!所以,就不用回表。
## 选择索引和编写利用这些索引的查询的3个原则
1.
单行访问是很慢的。特别是在机械硬盘存储中(SSD的随机I/O要快很多,不过这一点仍然成立)。如果服务器从存储中读取一个数据块只是为了获取其中一行,那么就浪费了很多工作。最好读取的块中能包含尽可能多所需要的行。使用索引可以创建位置引,用以提升效率。
2.
按顺序访问范围数据是很快的,这有两个原因。第一,顺序1/0不需要多次磁盘寻道,所以比随机I/O要快很多(特别是对机械硬盘)。第二,如果服务器能够按需要顺序读取数据,那么就不再需要额外的排序操作,并且GROUPBY查询也无须再做排序和将行按组进行聚合计算了。
3.
索引覆盖查询是很快的。如果一个索引包含了查询需要的所有列,那么存储引擎就
不需要再回表查找行。这避免了大量的单行访问,而上面的第1点已经写明单行访
问是很慢的。
## 为什么索引能提高查询速度
> 以下内容整理自:
> 地址: https://juejin.im/post/5b55b842f265da0f9e589e79
...
...
@@ -48,7 +108,7 @@ MySQL的基本存储结构是页(记录都存在页里边):
其实底层结构就是B+树,B+树作为树的一种实现,能够让我们很快地查找出对应的记录。
# 关于索引其他重要的内容补充
#
#
关于索引其他重要的内容补充
> 以下内容整理自:《Java工程师修炼之道》
...
...
@@ -61,7 +121,7 @@ MySQL中的索引可以以一定顺序引用多列,这种索引叫作联合索
select * from user where name=xx and city=xx ; //可以命中索引
select * from user where name=xx ; // 可以命中索引
select * from user where city=xx ; // 无法命中索引
```
```
这里需要注意的是,查询的时候如果两个条件都用上了,但是顺序不同,如
`city= xx and name =xx`
,那么现在的查询引擎会自动优化为匹配联合索引的顺序,这样是能够命中索引的。
由于最左前缀原则,在创建联合索引时,索引字段的顺序需要考虑字段值去重之后的个数,较多的放前面。ORDER BY子句也遵循此规则。
...
...
@@ -84,19 +144,19 @@ ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` )
```
ALTER TABLE `table_name` ADD UNIQUE ( `column` )
```
3.
添加INDEX(普通索引)
```
ALTER TABLE `table_name` ADD INDEX index_name ( `column` )
```
4.
添加FULLTEXT(全文索引)
```
ALTER TABLE `table_name` ADD FULLTEXT ( `column`)
```
5.
添加多列索引
```
...
...
@@ -104,7 +164,7 @@ ALTER TABLE `table_name` ADD INDEX index_name ( `column1`, `column2`, `column3`
```
# 参考
#
#
参考
-
《Java工程师修炼之道》
-
《MySQL高性能书籍_第3版》
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录