Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
Coudy Hou
JavaGuide
提交
8442291f
J
JavaGuide
项目概览
Coudy Hou
/
JavaGuide
与 Fork 源项目一致
从无法访问的项目Fork
通知
5
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
J
JavaGuide
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
体验新版 GitCode,发现更多精彩内容 >>
提交
8442291f
编写于
9月 10, 2018
作者:
S
Snailclimb
浏览文件
操作
浏览文件
下载
差异文件
Merge branch 'master' of
https://github.com/Snailclimb/Java_Guide
上级
79d7c747
2b130321
变更
3
隐藏空白更改
内联
并排
Showing
3 changed file
with
8 addition
and
6 deletion
+8
-6
Java相关/HashMap.md
Java相关/HashMap.md
+4
-2
Java相关/这几道Java集合框架面试题几乎必问.md
Java相关/这几道Java集合框架面试题几乎必问.md
+2
-2
数据存储/MySQL.md
数据存储/MySQL.md
+2
-2
未找到文件。
Java相关/HashMap.md
浏览文件 @
8442291f
...
...
@@ -22,7 +22,7 @@ JDK1.8 之前 HashMap 由 数组+链表 组成的,数组是 HashMap 的主体
## 底层数据结构分析
### JDK1.8之前
JDK1.8 之前 HashMap 底层是
**数组和链表**
结合在一起使用也就是
**链表散列**
。
**HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash 值,
当 hash 值相同时,
通过拉链法解决冲突。**
JDK1.8 之前 HashMap 底层是
**数组和链表**
结合在一起使用也就是
**链表散列**
。
**HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash 值,
然后通过 `(n - 1) & hash` 判断当前元素存放的位置(这里的 n 指的时数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就
通过拉链法解决冲突。**
**所谓扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。**
...
...
@@ -60,7 +60,9 @@ static int hash(int h) {
### JDK1.8之后
相比于之前的版本,jdk1.8在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。

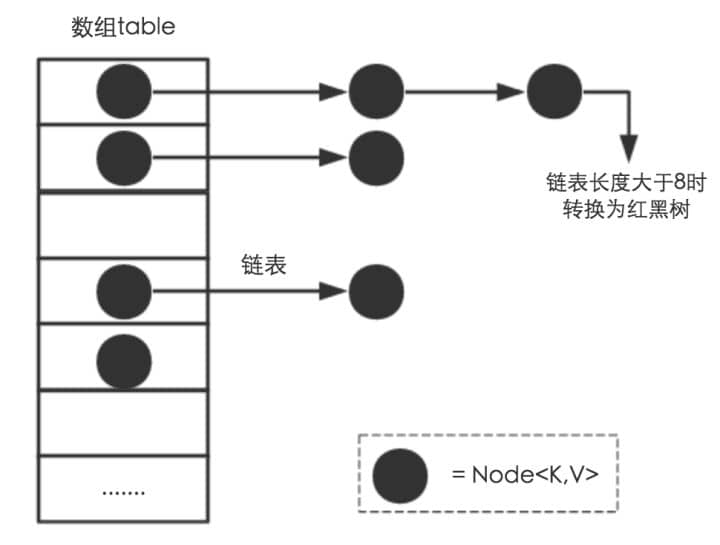
**类的属性:**
```
java
public
class
HashMap
<
K
,
V
>
extends
AbstractMap
<
K
,
V
>
implements
Map
<
K
,
V
>,
Cloneable
,
Serializable
{
...
...
Java相关/这几道Java集合框架面试题几乎必问.md
浏览文件 @
8442291f
...
...
@@ -39,7 +39,7 @@ Arraylist不是同步的,所以在不需要保证线程安全时时建议使
### JDK1.8之前
JDK1.8 之前 HashMap 底层是
**数组和链表**
结合在一起使用也就是
**链表散列**
。
**HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash 值,
当 hash 值相同时,
通过拉链法解决冲突。**
JDK1.8 之前 HashMap 底层是
**数组和链表**
结合在一起使用也就是
**链表散列**
。
**HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash 值,
然后通过 `(n - 1) & hash` 判断当前元素存放的位置(这里的 n 指的时数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就
通过拉链法解决冲突。**
**所谓扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。**
...
...
@@ -99,7 +99,7 @@ static int hash(int h) {
## HashMap 的长度为什么是2的幂次方
为了能让 HashMap 存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀
,每个链表/红黑树长度大致相同。这个实现就是把数据存到哪个链表/红黑树中的算法
。
为了能让 HashMap 存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀
。我们上面也讲到了过了,Hash 值的范围值-2147483648到2147483648,前后加起来大概40亿的映射空间,只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。但问题是一个40亿长度的数组,内存是放不下的。所以这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来要存放的位置也就是对应的数组下标。这个数组下标的计算方法是“
`(n - 1) & hash`
”。(n代表数组长度)。这也就解释了 HashMap 的长度为什么是2的幂次方
。
**这个算法应该如何设计呢?**
...
...
数据存储/MySQL.md
浏览文件 @
8442291f
...
...
@@ -45,9 +45,9 @@ Java面试通关手册(Java学习指南,欢迎Star,会一直完善下去
Mysql的BTree索引使用的是B数中的B+Tree,但对于主要的两种存储引擎的实现方式是不同的。
**MyISAM:**
B+Tree叶节点的data域存放的是数据记录的地址。在索引检索的时候,首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其
data域的值,然后以data
域的值为地址读取相应的数据记录。这被称为“非聚簇索引”。
**MyISAM:**
B+Tree叶节点的data域存放的是数据记录的地址。在索引检索的时候,首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其
data 域的值,然后以 data
域的值为地址读取相应的数据记录。这被称为“非聚簇索引”。
**InnoDB:**
其数据文件本身就是索引文件。相比MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按B+Tree组织的一个索引结构,树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。这被称为“聚簇索引(或聚集索引)”。而其余的索引都作为辅助索引,辅助索引的data域存储相应记录主键的值而不是地址,这也是和MyISAM不同的地方。
**在根据主索引搜索时,直接找到key所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,在走一遍主索引。**
**因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。**
PS:整理自《Java工程师修炼之道》
**InnoDB:**
其数据文件本身就是索引文件。相比MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按B+Tree组织的一个索引结构,树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。这被称为“聚簇索引(或聚集索引)”。而其余的索引都作为辅助索引
(非聚集索引)
,辅助索引的data域存储相应记录主键的值而不是地址,这也是和MyISAM不同的地方。
**在根据主索引搜索时,直接找到key所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,在走一遍主索引。**
**因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。**
PS:整理自《Java工程师修炼之道》
详细内容可以参考:
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录