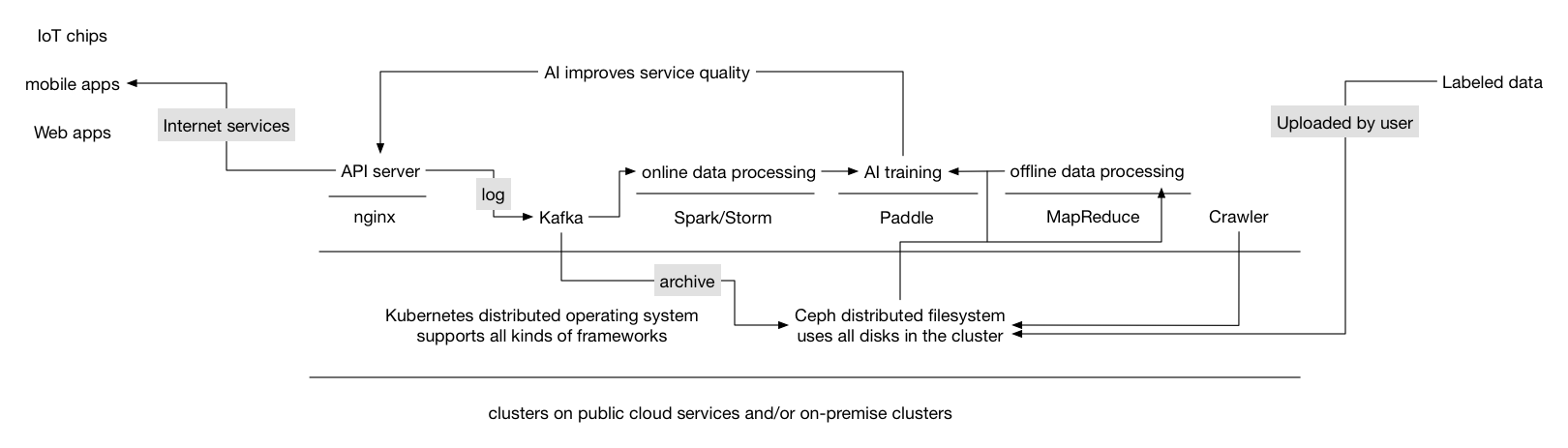
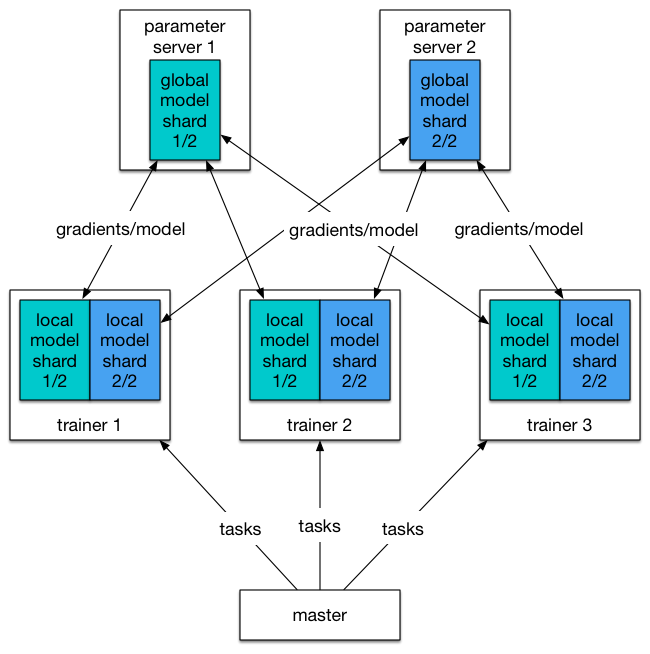
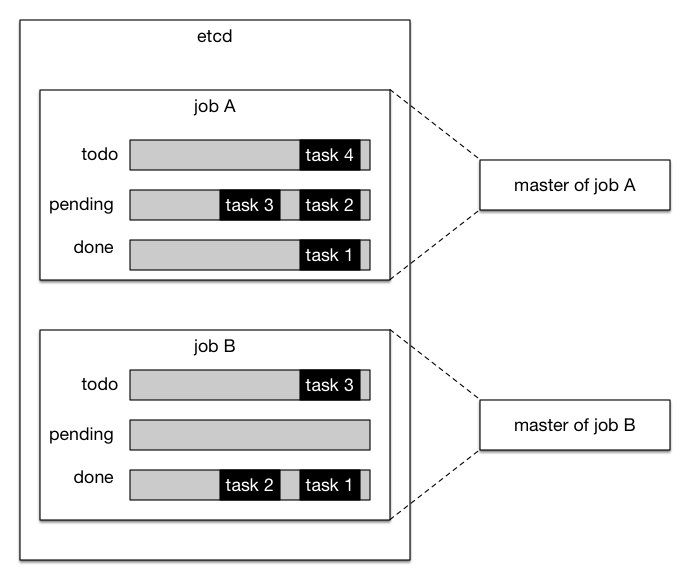
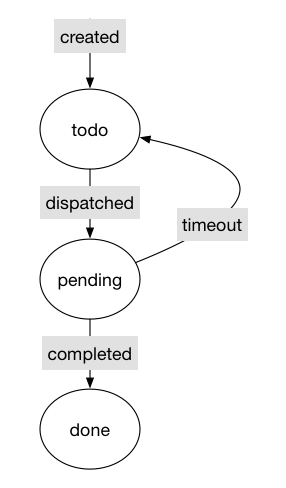
paddle dist architecture (draft)
Showing
doc/design/dist/README.md
0 → 100644
doc/design/dist/src/arch.graffle
0 → 100644
文件已添加
doc/design/dist/src/arch.png
0 → 100644
{kind=link}
57.0 KB
文件已添加
{kind=link}
52.5 KB
文件已添加
{kind=link}
32.7 KB
文件已添加
{kind=link}
20.0 KB