Merge branch 'develop' into normalize-layer
Showing
.gitmodules
已删除
100644 → 0
doc/api/v2/config/activation.rst
0 → 100644
doc/api/v2/config/attr.rst
0 → 100644
doc/api/v2/config/layer.rst
0 → 100644
doc/api/v2/config/networks.rst
0 → 100644
doc/api/v2/config/optimizer.rst
0 → 100644
doc/api/v2/config/pooling.rst
0 → 100644
paddle/scripts/deb/postinst
已删除
100644 → 0
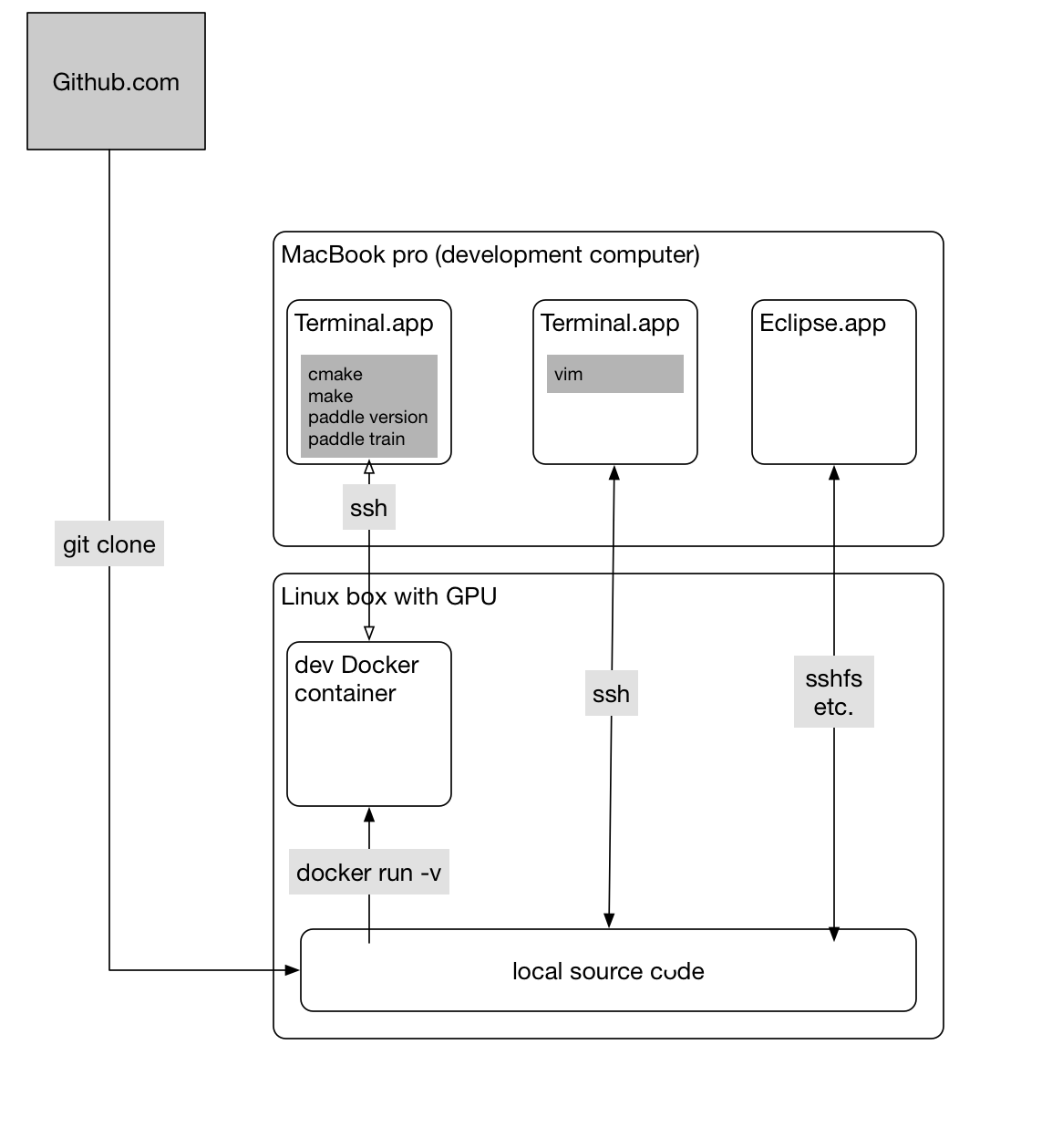
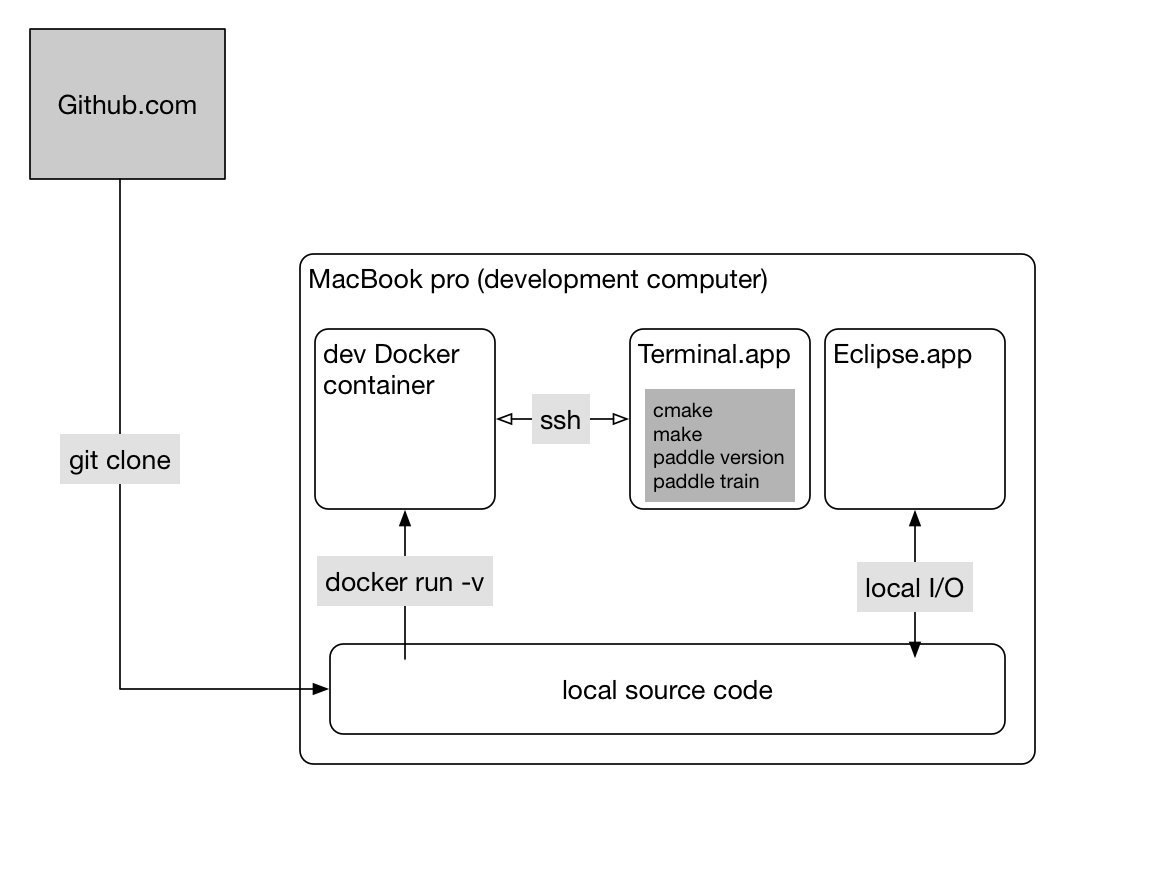
paddle/scripts/docker/README.md
0 → 100644
文件已添加
{kind=link}
89.7 KB
{kind=link}
65.7 KB