docs: update kafka desc
Update kafka description Add new imgs
Showing
{kind=link}
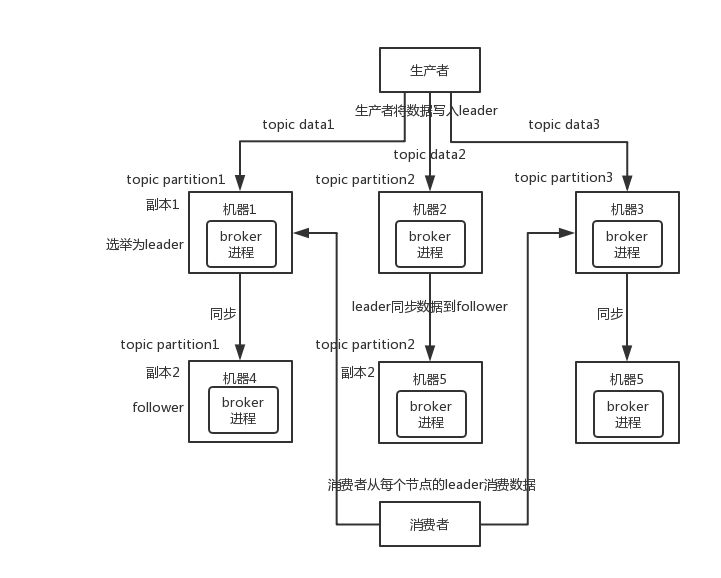
36.0 KB
{kind=link}
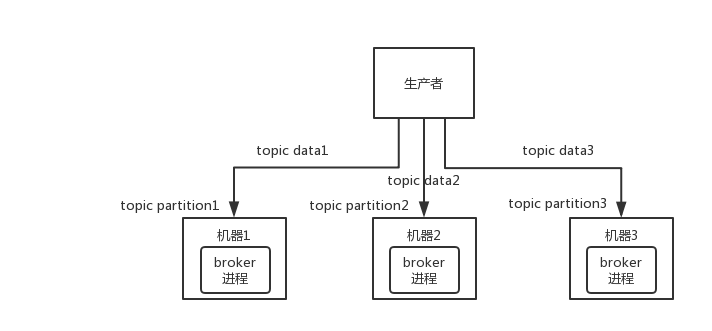
11.8 KB
{kind=link}
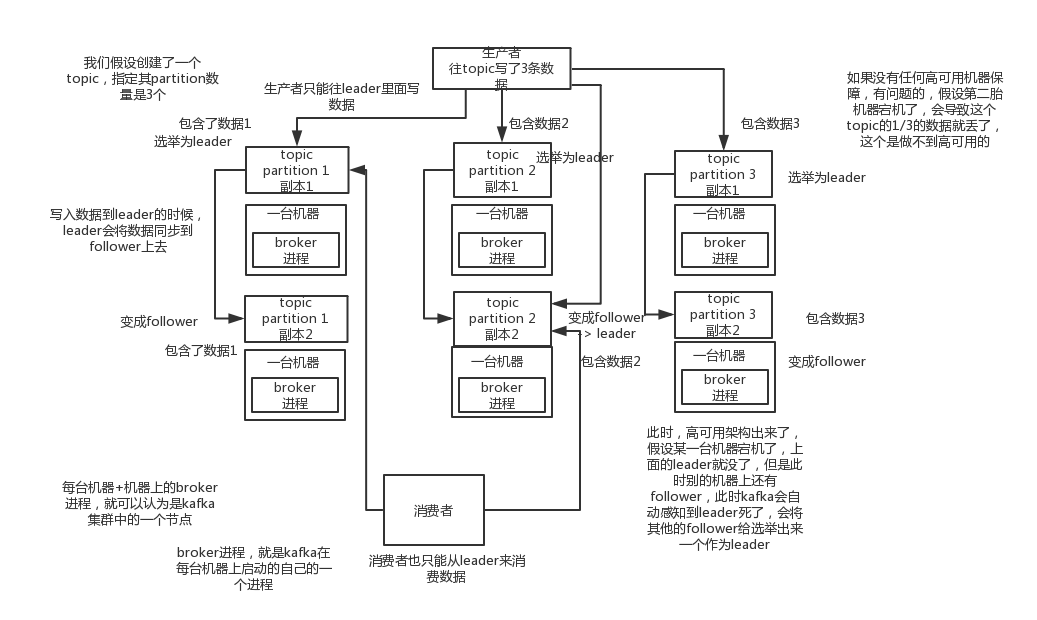
113.8 KB
img/kakfa-after.png
0 → 100644
{kind=link}
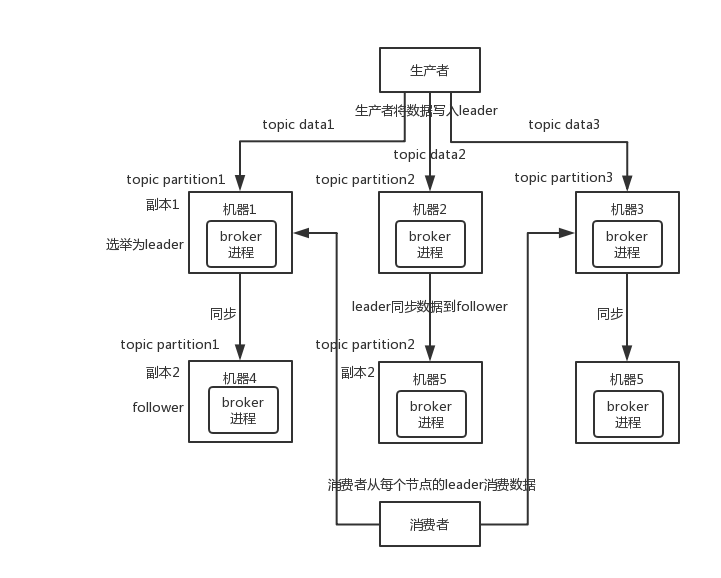
36.0 KB
img/kakfa-before.png
0 → 100644
{kind=link}
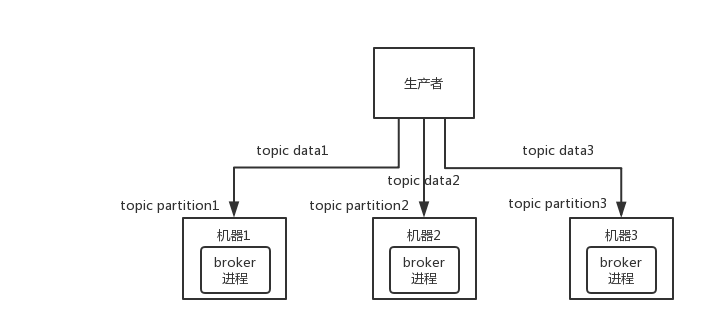
11.8 KB
img/mq-9.png
已删除
100644 → 0
{kind=link}
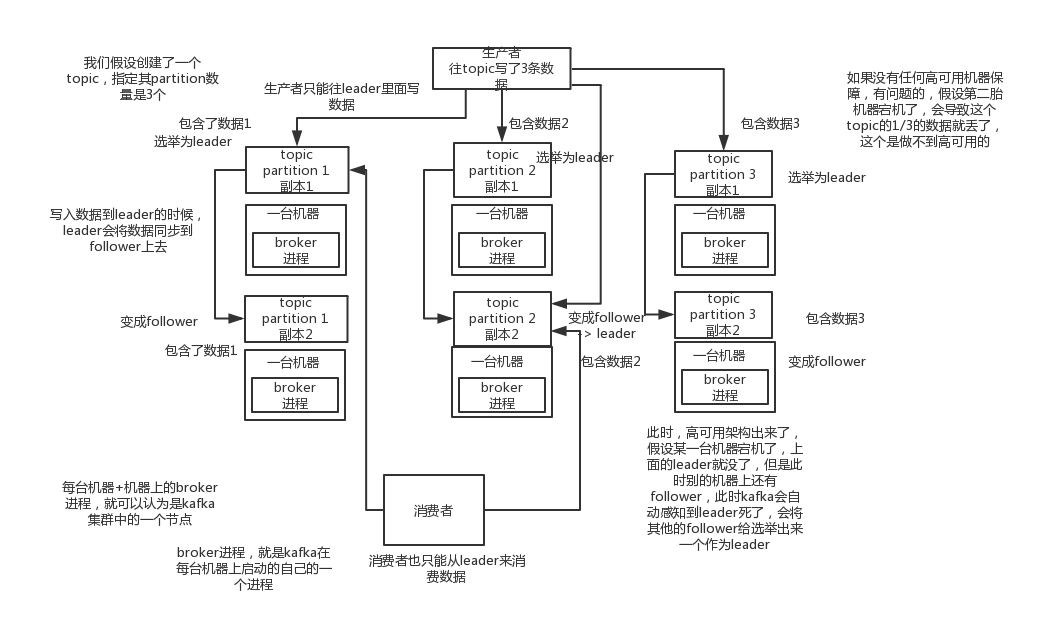
113.8 KB