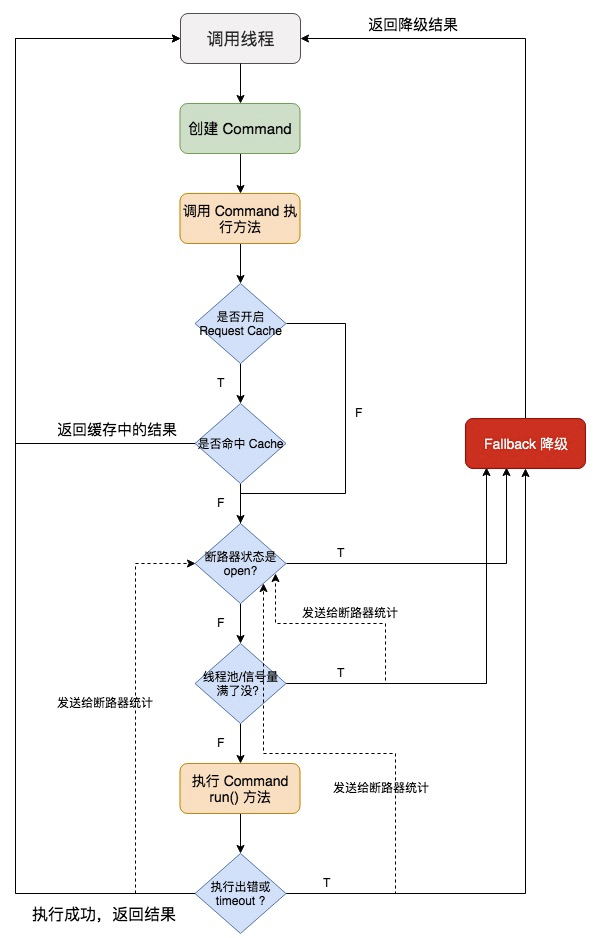
比如说有一个服务 A,你估算出来服务 A 每秒所有接口加起来的整体 `QPS` 在 100 左右,你有一个服务 B 去调用服务 A。你的服务 B 部署了 10 个实例,每个实例上,用 command group 去对应下游服务 A。给一个线程池,量大概是 10 就可以了,这样服务 B 对服务 A 整体的访问 QPS 就大概是每秒 100 了。
但是,如果说 command group 对应了一个服务,而这个服务暴露出来的几个接口,访问量很不一样,差异非常之大。你可能就希望在这个服务 command group 内部,包含的对应多个接口的 command key,做一些细粒度的资源隔离。就是说,对同一个服务的不同接口,使用不同的线程池。
但是,如果说 command group 对应了一个服务,而这个服务暴露出来的几个接口,访问量很不一样,差异非常之大。你可能就希望在这个服务对应 command group 的内部,包含对应多个接口的 command key,做一些细粒度的资源隔离。**就是说,希望对同一个服务的不同接口,使用不同的线程池。**
有这样一个分布式系统,服务 A 依赖于服务 B,服务 B 依赖于服务 C/D/E。在这样一个成熟的系统内,比如说最多可能只有 100 个线程资源。正常情况下,40 个线程并发调用服务 C,各 30 个线程并发调用 D/E。
调用服务 C,只需要 20ms,现在因为服务 C 故障了,比如延迟,或者挂了,此时线程会 hang 住 2s 左右。40 个线程全部被卡住,由于请求不断涌入,其它的线程也用来调用服务 C,同样也会被卡住。这样导致服务 B 的线程资源被耗尽,无法接收新的请求,甚至可能因为大量线程不断的运转,导致自己宕机。服务 A 也挂。
调用服务 C,只需要 20ms,现在因为服务 C 故障了,比如延迟,或者挂了,此时线程会 hang 住 2s 左右。40 个线程全部被卡住,由于请求不断涌入,其它的线程也用来调用服务 C,同样也会被卡住。这样导致服务 B 的线程资源被耗尽,无法接收新的请求,甚至可能因为大量线程不断的运转,导致自己宕机。这种影响势必会蔓延至服务 A,导致服务 A 也跟着挂掉。
{kind=link}
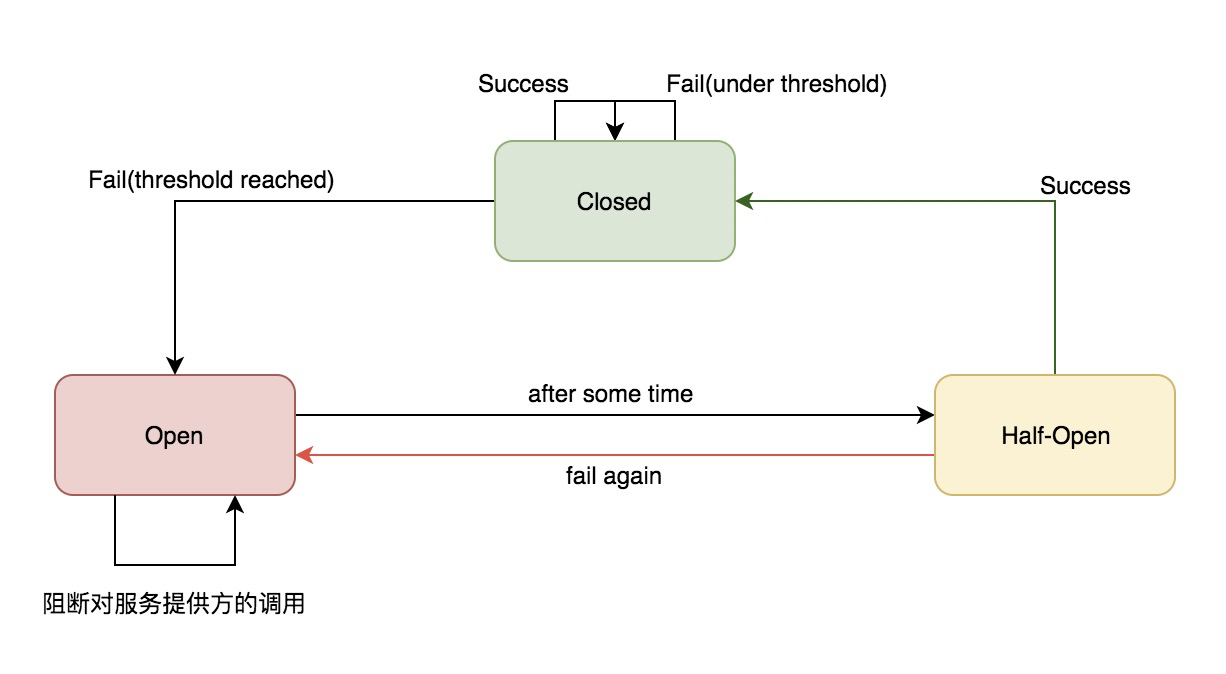
{kind=link}