docs: update doc description, fix #4
Update doc description Update images Fix #4
Showing
{kind=link}
26.3 KB
{kind=link}
64.4 KB
{kind=link}
98.3 KB
{kind=link}
17.9 KB
{kind=link}
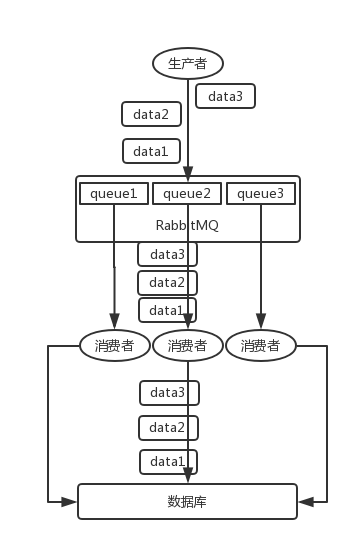
20.7 KB
{kind=link}
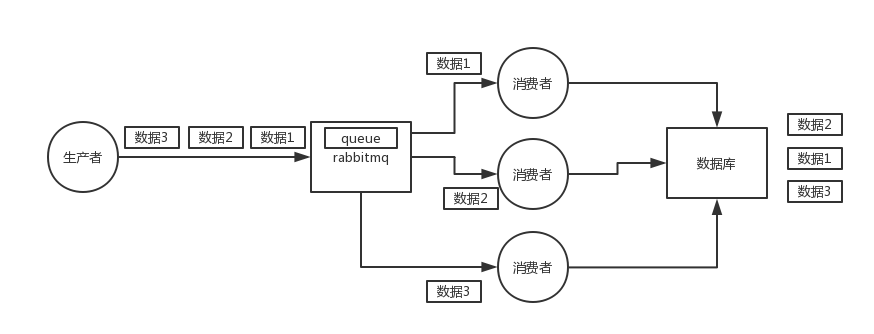
28.9 KB
{kind=link}
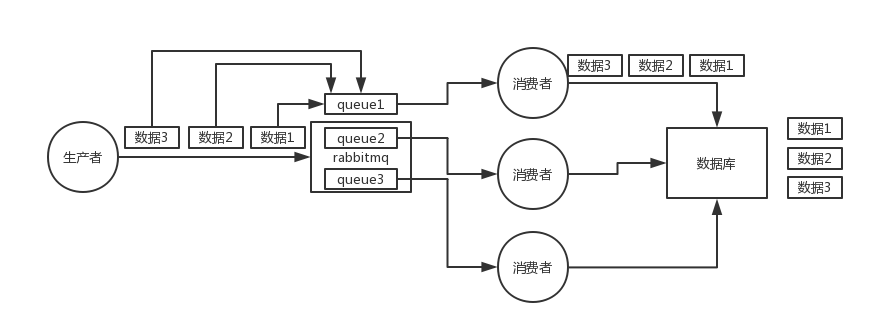
29.0 KB
{kind=link}
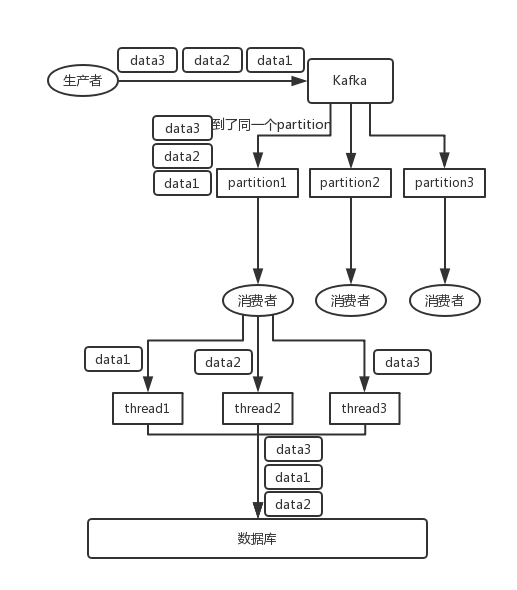
26.4 KB
{kind=link}
38.6 KB
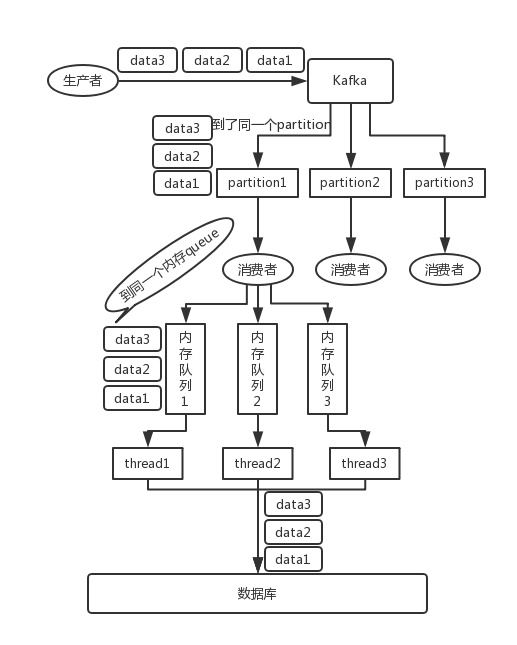
img/kafka-order-01.png
0 → 100644
{kind=link}
26.4 KB
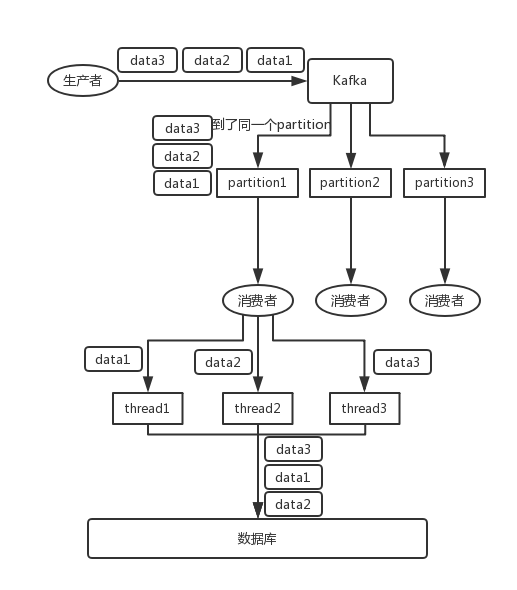
img/kafka-order-02.png
0 → 100644
{kind=link}
38.6 KB
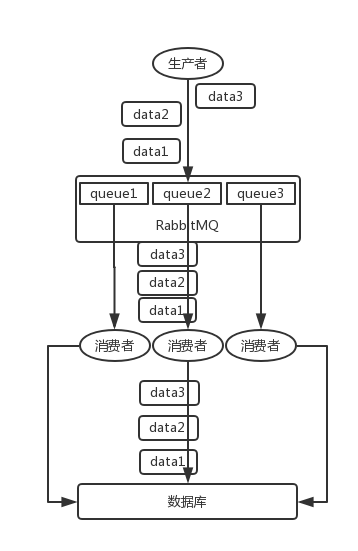
img/rabbitmq-order-01.png
0 → 100644
{kind=link}
17.9 KB
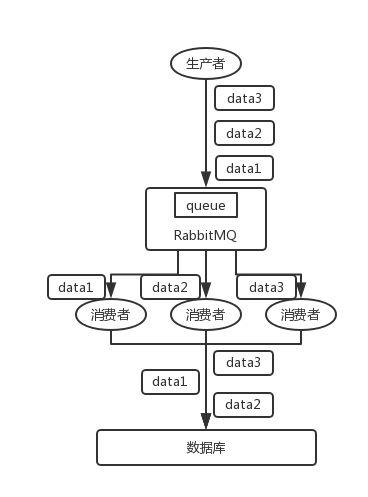
img/rabbitmq-order-02.png
0 → 100644
{kind=link}
20.7 KB