docs(es): add es-write-query-search.md
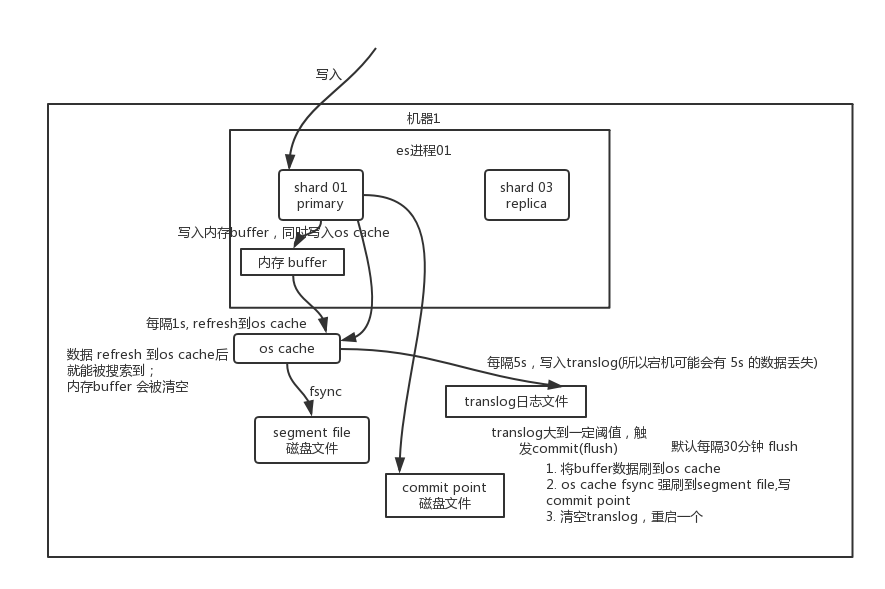
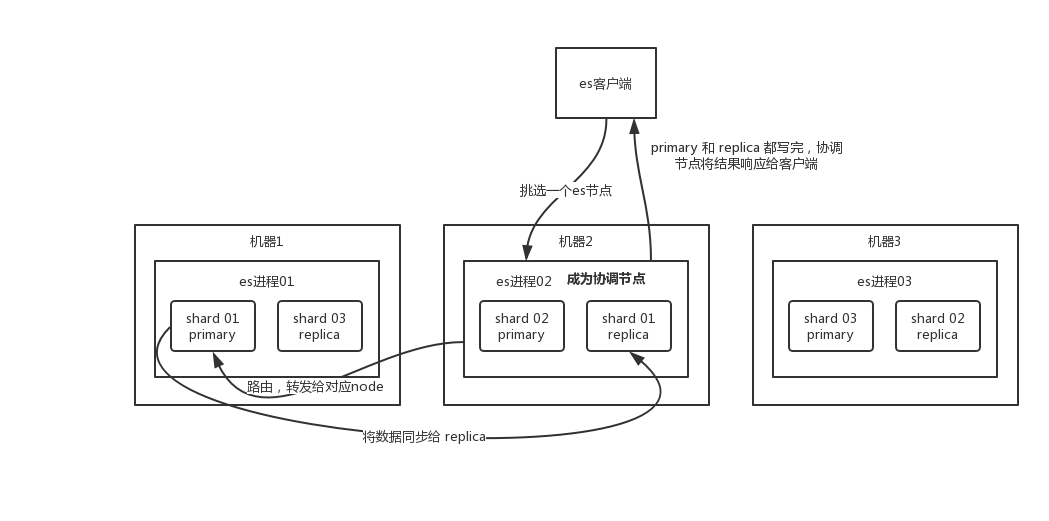
ElasticSearch写入/查询数据的工作原理
Showing
img/es-write-detail.png
0 → 100644
{kind=link}
64.6 KB
img/es-write.png
0 → 100644
{kind=link}
41.0 KB
从无法访问的项目Fork
ElasticSearch写入/查询数据的工作原理
64.6 KB
41.0 KB