其实这是分库分表之后你必然要面对的一个问题,就是 id 咋生成?因为要是分成多个表之后,每个表都是从 1 开始累加,那肯定不对啊,需要一个**全局唯一**的 id 来支持。所以这都是你实际生产环境中必须考虑的问题。
## 面试题剖析
### 数据库自增 id
### 基于数据库的实现方案
#### 数据库自增 id
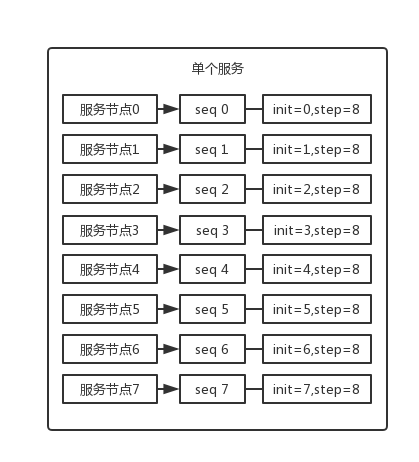
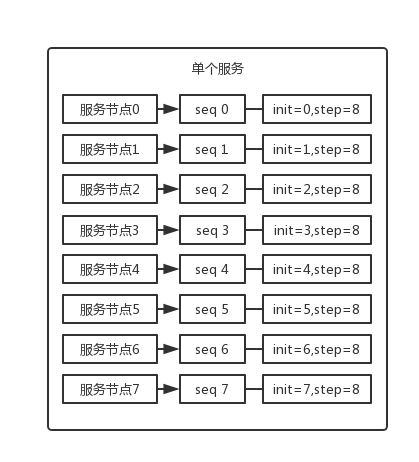
这个就是说你的系统里每次得到一个 id,都是往一个库的一个表里插入一条没什么业务含义的数据,然后获取一个数据库自增的一个 id。拿到这个 id 之后再往对应的分库分表里去写入。
这个方案的好处就是方便简单,谁都会用;**缺点就是单库生成**自增 id,要是高并发的话,就会有瓶颈的;如果你硬是要改进一下,那么就专门开一个服务出来,这个服务每次就拿到当前 id 最大值,然后自己递增几个 id,一次性返回一批 id,然后再把当前最大 id 值修改成递增几个 id 之后的一个值;但是**无论如何都是基于单个数据库**。
{kind=link}
{kind=link}