Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
wushizhenking
CS-Notes
提交
61e1a609
C
CS-Notes
项目概览
wushizhenking
/
CS-Notes
与 Fork 源项目一致
从无法访问的项目Fork
通知
2
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
C
CS-Notes
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
体验新版 GitCode,发现更多精彩内容 >>
提交
61e1a609
编写于
6月 15, 2018
作者:
C
CyC2018
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
auto commit
上级
e1a9c7b8
变更
2
隐藏空白更改
内联
并排
Showing
2 changed file
with
24 addition
and
53 deletion
+24
-53
notes/Java 容器.md
notes/Java 容器.md
+24
-53
pics/5158bc2f-83a6-4351-817e-c9b07f955d76.png
pics/5158bc2f-83a6-4351-817e-c9b07f955d76.png
+0
-0
未找到文件。
notes/Java 容器.md
浏览文件 @
61e1a609
...
@@ -11,8 +11,6 @@
...
@@ -11,8 +11,6 @@
*
[
LinkedList
](
#linkedlist
)
*
[
LinkedList
](
#linkedlist
)
*
[
HashMap
](
#hashmap
)
*
[
HashMap
](
#hashmap
)
*
[
ConcurrentHashMap
](
#concurrenthashmap
)
*
[
ConcurrentHashMap
](
#concurrenthashmap
)
*
[
LinkedHashMap
](
#linkedhashmap
)
*
[
TreeMap
](
#treemap
)
*
[
参考资料
](
#参考资料
)
*
[
参考资料
](
#参考资料
)
<!-- GFM-TOC -->
<!-- GFM-TOC -->
...
@@ -102,16 +100,12 @@ List list = Arrays.asList(1,2,3);
...
@@ -102,16 +100,12 @@ List list = Arrays.asList(1,2,3);
# 三、源码分析
# 三、源码分析
建议先阅读
[
算法-查找
](
https://github.com/CyC2018/Interview-Notebook/blob/master/notes/%E7%AE%97%E6%B3%95.md#%E6%9F%A5%E6%89%BE
)
部分,对容器类源码的理解有很大帮助
。
如果没有特别说明,以下源码分析基于 JDK 1.8
。
至于 ConcurrentHashMap 的理解,需要有并发方面的知识,建议先阅读:
[
Java 并发
](
https://github.com/CyC2018/Interview-Notebook/blob/master/notes/Java%20%E5%B9%B6%E5%8F%91.md
)
在 IDEA 中 double shift 调出 Search EveryWhere,查找源码文件,找到之后就可以阅读源码。
以下源码从 JDK 1.8 提取而来,下载地址:
[
JDK-Source-Code
](
https://github.com/CyC2018/JDK-Source-Code
)
。
## ArrayList
## ArrayList
[
ArrayList.java
](
https://github.com/CyC2018/JDK-Source-Code/tree/master/src/ArrayList.java
)
### 1. 概览
### 1. 概览
实现了 RandomAccess 接口,因此支持随机访问,这是理所当然的,因为 ArrayList 是基于数组实现的。
实现了 RandomAccess 接口,因此支持随机访问,这是理所当然的,因为 ArrayList 是基于数组实现的。
...
@@ -139,7 +133,7 @@ transient Object[] elementData; // non-private to simplify nested class access
...
@@ -139,7 +133,7 @@ transient Object[] elementData; // non-private to simplify nested class access
添加元素时使用 ensureCapacityInternal() 方法来保证容量足够,如果不够时,需要使用 grow() 方法进行扩容,新容量的大小为
`oldCapacity + (oldCapacity >> 1)`
,也就是旧容量的 1.5 倍。
添加元素时使用 ensureCapacityInternal() 方法来保证容量足够,如果不够时,需要使用 grow() 方法进行扩容,新容量的大小为
`oldCapacity + (oldCapacity >> 1)`
,也就是旧容量的 1.5 倍。
扩容操作需要调用
`Arrays.copyOf()`
把原数组整个复制到新数组中,因此最好在创建 ArrayList 对象时就指定大概的容量大小,减少扩容操作的次数。
扩容操作需要调用
`Arrays.copyOf()`
把原数组整个复制到新数组中,
这个操作代价很高,
因此最好在创建 ArrayList 对象时就指定大概的容量大小,减少扩容操作的次数。
```
java
```
java
public
boolean
add
(
E
e
)
{
public
boolean
add
(
E
e
)
{
...
@@ -152,13 +146,11 @@ private void ensureCapacityInternal(int minCapacity) {
...
@@ -152,13 +146,11 @@ private void ensureCapacityInternal(int minCapacity) {
if
(
elementData
==
DEFAULTCAPACITY_EMPTY_ELEMENTDATA
)
{
if
(
elementData
==
DEFAULTCAPACITY_EMPTY_ELEMENTDATA
)
{
minCapacity
=
Math
.
max
(
DEFAULT_CAPACITY
,
minCapacity
);
minCapacity
=
Math
.
max
(
DEFAULT_CAPACITY
,
minCapacity
);
}
}
ensureExplicitCapacity
(
minCapacity
);
ensureExplicitCapacity
(
minCapacity
);
}
}
private
void
ensureExplicitCapacity
(
int
minCapacity
)
{
private
void
ensureExplicitCapacity
(
int
minCapacity
)
{
modCount
++;
modCount
++;
// overflow-conscious code
// overflow-conscious code
if
(
minCapacity
-
elementData
.
length
>
0
)
if
(
minCapacity
-
elementData
.
length
>
0
)
grow
(
minCapacity
);
grow
(
minCapacity
);
...
@@ -179,20 +171,17 @@ private void grow(int minCapacity) {
...
@@ -179,20 +171,17 @@ private void grow(int minCapacity) {
### 4. 删除元素
### 4. 删除元素
需要调用 System.arraycopy() 将 index+1 后面的元素都复制到 index 位置上
,复制的代价很高
。
需要调用 System.arraycopy() 将 index+1 后面的元素都复制到 index 位置上。
```
java
```
java
public
E
remove
(
int
index
)
{
public
E
remove
(
int
index
)
{
rangeCheck
(
index
);
rangeCheck
(
index
);
modCount
++;
modCount
++;
E
oldValue
=
elementData
(
index
);
E
oldValue
=
elementData
(
index
);
int
numMoved
=
size
-
index
-
1
;
int
numMoved
=
size
-
index
-
1
;
if
(
numMoved
>
0
)
if
(
numMoved
>
0
)
System
.
arraycopy
(
elementData
,
index
+
1
,
elementData
,
index
,
numMoved
);
System
.
arraycopy
(
elementData
,
index
+
1
,
elementData
,
index
,
numMoved
);
elementData
[--
size
]
=
null
;
// clear to let GC do its work
elementData
[--
size
]
=
null
;
// clear to let GC do its work
return
oldValue
;
return
oldValue
;
}
}
```
```
...
@@ -226,8 +215,6 @@ private void writeObject(java.io.ObjectOutputStream s)
...
@@ -226,8 +215,6 @@ private void writeObject(java.io.ObjectOutputStream s)
## Vector
## Vector
[
Vector.java
](
https://github.com/CyC2018/JDK-Source-Code/tree/master/src/Vector.java
)
### 1. 同步
### 1. 同步
它的实现与 ArrayList 类似,但是使用了 synchronized 进行同步。
它的实现与 ArrayList 类似,但是使用了 synchronized 进行同步。
...
@@ -250,26 +237,26 @@ public synchronized E get(int index) {
...
@@ -250,26 +237,26 @@ public synchronized E get(int index) {
### 2. ArrayList 与 Vector
### 2. ArrayList 与 Vector
-
Vector
和 ArrayList 几乎是完全相同的,唯一的区别在于 Vector
是同步的,因此开销就比 ArrayList 要大,访问速度更慢。最好使用 ArrayList 而不是 Vector,因为同步操作完全可以由程序员自己来控制;
-
Vector 是同步的,因此开销就比 ArrayList 要大,访问速度更慢。最好使用 ArrayList 而不是 Vector,因为同步操作完全可以由程序员自己来控制;
-
Vector 每次扩容请求其大小的 2 倍空间,而 ArrayList 是 1.5 倍。
-
Vector 每次扩容请求其大小的 2 倍空间,而 ArrayList 是 1.5 倍。
### 3. Vector 替代方案
### 3. Vector 替代方案
为了获得线程安全的 ArrayList,可以使用
Collections.synchronizedList(); 得到一个线程安全的 ArrayList,也可以使用 concurrent 并发包下的 CopyOnWriteArrayList 类;
为了获得线程安全的 ArrayList,可以使用
`Collections.synchronizedList();`
得到一个线程安全的 ArrayList。
```
java
```
java
List
<
String
>
list
=
new
ArrayList
<>();
List
<
String
>
list
=
new
ArrayList
<>();
List
<
String
>
synList
=
Collections
.
synchronizedList
(
list
);
List
<
String
>
synList
=
Collections
.
synchronizedList
(
list
);
```
```
也可以使用 concurrent 并发包下的 CopyOnWriteArrayList 类。
```
java
```
java
List
list
=
new
CopyOnWriteArrayList
();
List
<
String
>
list
=
new
CopyOnWriteArrayList
<>
();
```
```
## LinkedList
## LinkedList
[
LinkedList.java
](
https://github.com/CyC2018/JDK-Source-Code/tree/master/src/LinkedList.java
)
### 1. 概览
### 1. 概览
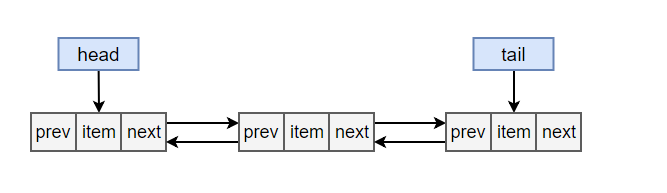
基于双向链表实现,内部使用 Node 来存储链表节点信息。
基于双向链表实现,内部使用 Node 来存储链表节点信息。
...
@@ -289,7 +276,7 @@ transient Node<E> first;
...
@@ -289,7 +276,7 @@ transient Node<E> first;
transient
Node
<
E
>
last
;
transient
Node
<
E
>
last
;
```
```
<div
align=
"center"
>
<img
src=
"../pics//
HowLinkedListWorks
.png"
/>
</div><br>
<div
align=
"center"
>
<img
src=
"../pics//
5158bc2f-83a6-4351-817e-c9b07f955d76
.png"
/>
</div><br>
### 2. ArrayList 与 LinkedList
### 2. ArrayList 与 LinkedList
...
@@ -299,19 +286,17 @@ transient Node<E> last;
...
@@ -299,19 +286,17 @@ transient Node<E> last;
## HashMap
## HashMap
[
HashMap.java
](
https://github.com/CyC2018/JDK-Source-Code/tree/master/src/HashMap.java
)
为了便于理解,以下源码分析以 JDK 1.7 为主。
为了便于理解,以下内容以 JDK 1.7 为主。
### 1. 存储结构
### 1. 存储结构
使用拉链法来解决冲突,内部包含了一个 Entry 类型的数组 table,数组中的每个位置被当成一个桶
。
内部包含了一个 Entry 类型的数组 table
。
```
java
```
java
transient
Entry
[]
table
;
transient
Entry
[]
table
;
```
```
其中,Entry 就是存储数据的键值对,它包含了四个字段。从 next 字段我们可以看出 Entry 是一个链表,即
每个桶会存放一个链表
。
其中,Entry 就是存储数据的键值对,它包含了四个字段。从 next 字段我们可以看出 Entry 是一个链表,即
数组中的每个位置被当成一个桶,一个桶存放一个链表,链表中存放哈希值相同的 Entry。也就是说,HashMap 使用拉链法来解决冲突
。
<div
align=
"center"
>
<img
src=
"../pics//8fe838e3-ef77-4f63-bf45-417b6bc5c6bb.png"
width=
"600"
/>
</div><br>
<div
align=
"center"
>
<img
src=
"../pics//8fe838e3-ef77-4f63-bf45-417b6bc5c6bb.png"
width=
"600"
/>
</div><br>
...
@@ -437,7 +422,7 @@ public V put(K key, V value) {
...
@@ -437,7 +422,7 @@ public V put(K key, V value) {
}
}
```
```
HashMap 允许插入键
位 null 的键值对,
因为无法调用 null 的 hashCode(),也就无法确定该键值对的桶下标,只能通过强制指定一个桶下标来存放。HashMap 使用第 0 个桶存放键为 null 的键值对。
HashMap 允许插入键
为 null 的键值对。
因为无法调用 null 的 hashCode(),也就无法确定该键值对的桶下标,只能通过强制指定一个桶下标来存放。HashMap 使用第 0 个桶存放键为 null 的键值对。
```
java
```
java
private
V
putForNullKey
(
V
value
)
{
private
V
putForNullKey
(
V
value
)
{
...
@@ -544,9 +529,9 @@ y : 10110010
...
@@ -544,9 +529,9 @@ y : 10110010
y%x : 00000010
y%x : 00000010
```
```
我们知道,位运算的代价比求模运算小的多,因此在进行这种计算时
能
用位运算的话能带来更高的性能。
我们知道,位运算的代价比求模运算小的多,因此在进行这种计算时用位运算的话能带来更高的性能。
确定桶下标的最后一步是将 key 的 hash 值对桶个数取模:hash%capacity,如果能保证 capacity 为 2 的
幂
次方,那么就可以将这个操作转换为位运算。
确定桶下标的最后一步是将 key 的 hash 值对桶个数取模:hash%capacity,如果能保证 capacity 为 2 的
n
次方,那么就可以将这个操作转换为位运算。
```
java
```
java
static
int
indexFor
(
int
h
,
int
length
)
{
static
int
indexFor
(
int
h
,
int
length
)
{
...
@@ -564,10 +549,10 @@ static int indexFor(int h, int length) {
...
@@ -564,10 +549,10 @@ static int indexFor(int h, int length) {
| 参数 | 含义 |
| 参数 | 含义 |
| :--: | :-- |
| :--: | :-- |
| capacity | table 的容量大小,默认为 16,需要注意的是 capacity 必须保证为 2 的次方。|
| capacity | table 的容量大小,默认为 16,需要注意的是 capacity 必须保证为 2 的
n
次方。|
| size | table 的实际使用量。 |
| size | table 的实际使用量。 |
| threshold | size 的临界值,size 必须小于 threshold,如果大于等于,就必须进行扩容操作。 |
| threshold | size 的临界值,size 必须小于 threshold,如果大于等于,就必须进行扩容操作。 |
| load_factor | table 能够使用的比例,threshold = capacity
*
load_factor。|
| load_factor |
装载因子,
table 能够使用的比例,threshold = capacity
*
load_factor。|
```
java
```
java
static
final
int
DEFAULT_INITIAL_CAPACITY
=
16
;
static
final
int
DEFAULT_INITIAL_CAPACITY
=
16
;
...
@@ -608,7 +593,6 @@ void resize(int newCapacity) {
...
@@ -608,7 +593,6 @@ void resize(int newCapacity) {
threshold
=
Integer
.
MAX_VALUE
;
threshold
=
Integer
.
MAX_VALUE
;
return
;
return
;
}
}
Entry
[]
newTable
=
new
Entry
[
newCapacity
];
Entry
[]
newTable
=
new
Entry
[
newCapacity
];
transfer
(
newTable
);
transfer
(
newTable
);
table
=
newTable
;
table
=
newTable
;
...
@@ -645,11 +629,11 @@ capacity : 00010000
...
@@ -645,11 +629,11 @@ capacity : 00010000
new capacity : 00100000
new capacity : 00100000
```
```
对于一个 Key,它的
hash
如果在第 6 位上为 0,那么取模得到的结果和之前一样;如果为 1,那么得到的结果为原来的结果 + 8。
对于一个 Key,它的
哈希值
如果在第 6 位上为 0,那么取模得到的结果和之前一样;如果为 1,那么得到的结果为原来的结果 + 8。
### 7. 扩容-计算数组容量
### 7. 扩容-计算数组容量
HashMap 构造函数允许用户传入的容量不是 2 的
幂次方,因为它可以自动地将传入的容量转换为 2 的幂
次方。
HashMap 构造函数允许用户传入的容量不是 2 的
n 次方,因为它可以自动地将传入的容量转换为 2 的 n
次方。
先考虑如何求一个数的掩码,对于 10010000,它的掩码为 11111111,可以使用以下方法得到:
先考虑如何求一个数的掩码,对于 10010000,它的掩码为 11111111,可以使用以下方法得到:
...
@@ -659,7 +643,7 @@ mask |= mask >> 2 11111100
...
@@ -659,7 +643,7 @@ mask |= mask >> 2 11111100
mask |= mask >> 4 11111111
mask |= mask >> 4 11111111
```
```
mask+1 是大于原始数字的最小的 2
幂
次方。
mask+1 是大于原始数字的最小的 2
的 n
次方。
```
```
num 10010000
num 10010000
...
@@ -682,20 +666,17 @@ static final int tableSizeFor(int cap) {
...
@@ -682,20 +666,17 @@ static final int tableSizeFor(int cap) {
### 8. 链表转红黑树
### 8. 链表转红黑树
应该注意到,
从 JDK 1.8 开始,一个桶存储的链表长度大于 8 时会将链表转换为红黑树。
从 JDK 1.8 开始,一个桶存储的链表长度大于 8 时会将链表转换为红黑树。
### 9. HashMap 与 HashTable
### 9. HashMap 与 HashTable
-
HashTable
是同步的,它使用了 synchronized 来进行同步。它也是线程安全的,多个线程可以共享同一个 HashTable。HashMap 不是同步的,但是可以使用 ConcurrentHashMap,它是 HashTable 的替代,而且比 HashTable 可扩展性更好
。
-
HashTable
使用 synchronized 来进行同步
。
-
HashMap 可以插入键为 null 的 Entry。
-
HashMap 可以插入键为 null 的 Entry。
-
HashMap 的迭代器是 fail-fast 迭代器,而 Hashtable 的 enumerator 迭代器不是 fail-fast 的。
-
HashMap 的迭代器是 fail-fast 迭代器。
-
由于 Hashtable 是线程安全的也是 synchronized,所以在单线程环境下它比 HashMap 要慢。
-
HashMap 不能保证随着时间的推移 Map 中的元素次序是不变的。
-
HashMap 不能保证随着时间的推移 Map 中的元素次序是不变的。
## ConcurrentHashMap
## ConcurrentHashMap
[
ConcurrentHashMap.java
](
https://github.com/CyC2018/JDK-Source-Code/blob/master/src/1.7/ConcurrentHashMap.java
)
### 1. 存储结构
### 1. 存储结构
```
java
```
java
...
@@ -819,22 +800,12 @@ public int size() {
...
@@ -819,22 +800,12 @@ public int size() {
### 3. JDK 1.8 的改动
### 3. JDK 1.8 的改动
[
ConcurrentHashMap.java
](
https://github.com/CyC2018/JDK-Source-Code/blob/master/src/ConcurrentHashMap.java
)
JDK 1.7 使用分段锁机制来实现并发更新操作,核心类为 Segment,它继承自重入锁 ReentrantLock,并发程度与 Segment 数量相等。
JDK 1.7 使用分段锁机制来实现并发更新操作,核心类为 Segment,它继承自重入锁 ReentrantLock,并发程度与 Segment 数量相等。
JDK 1.8 使用了 CAS 操作来支持更高的并发度,在 CAS 操作失败时使用内置锁 synchronized。
JDK 1.8 使用了 CAS 操作来支持更高的并发度,在 CAS 操作失败时使用内置锁 synchronized。
并且 JDK 1.8 的实现也在链表过长时会转换为红黑树。
并且 JDK 1.8 的实现也在链表过长时会转换为红黑树。
## LinkedHashMap
[
LinkedHashMap.java
](
https://github.com/CyC2018/JDK-Source-Code/tree/master/src/HashMap.java
)
## TreeMap
[
TreeMap.java
](
https://github.com/CyC2018/JDK-Source-Code/tree/master/src/TreeMap.java
)
# 参考资料
# 参考资料
-
Eckel B. Java 编程思想 [M]. 机械工业出版社, 2002.
-
Eckel B. Java 编程思想 [M]. 机械工业出版社, 2002.
...
...
pics/5158bc2f-83a6-4351-817e-c9b07f955d76.png
0 → 100644
浏览文件 @
61e1a609
6.0 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}