Merge branch 'master' of v9.git.n.xiaomi.com:deep-computing/mace into refactor_target_deps
Showing
docs/introduction.rst
0 → 100644
{kind=link}
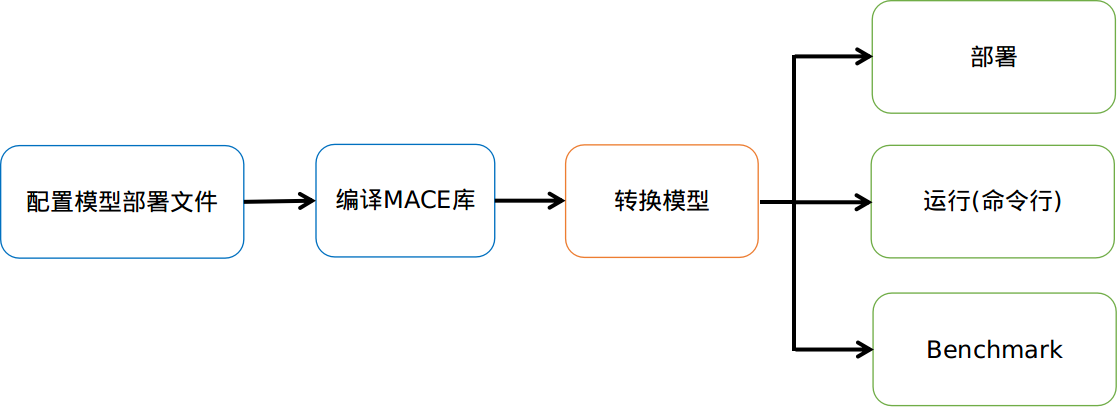
docs/mace-work-flow-zh.png
0 → 100644
{kind=link}
37.7 KB
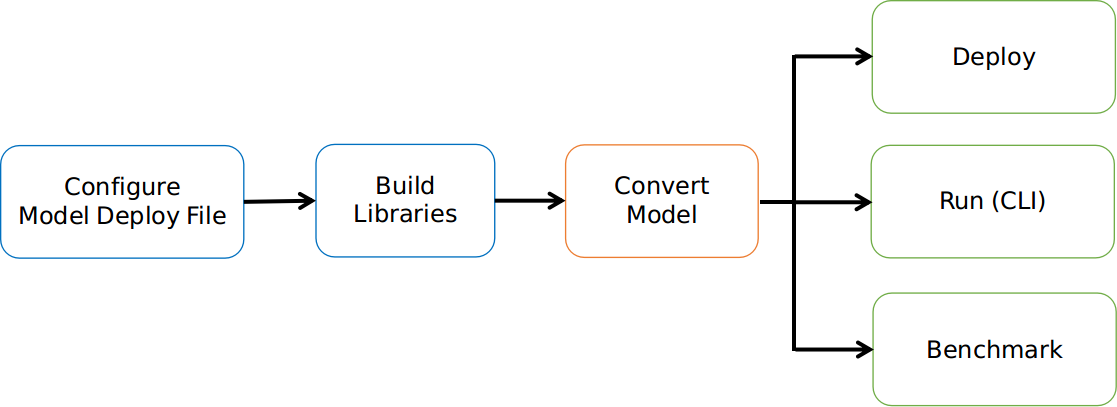
docs/mace-work-flow.png
0 → 100644
{kind=link}
34.7 KB
docs/user_guide/basic_usage.rst
0 → 100644