
last commit
Showing
00 Paper/Wskh/问题三.docx
0 → 100644
文件已添加
00 Paper/总论文.docx
0 → 100644
文件已添加
02 Data/C题.pdf
0 → 100644
文件已添加
02 Data/附件.xlsx
0 → 100644
文件已添加
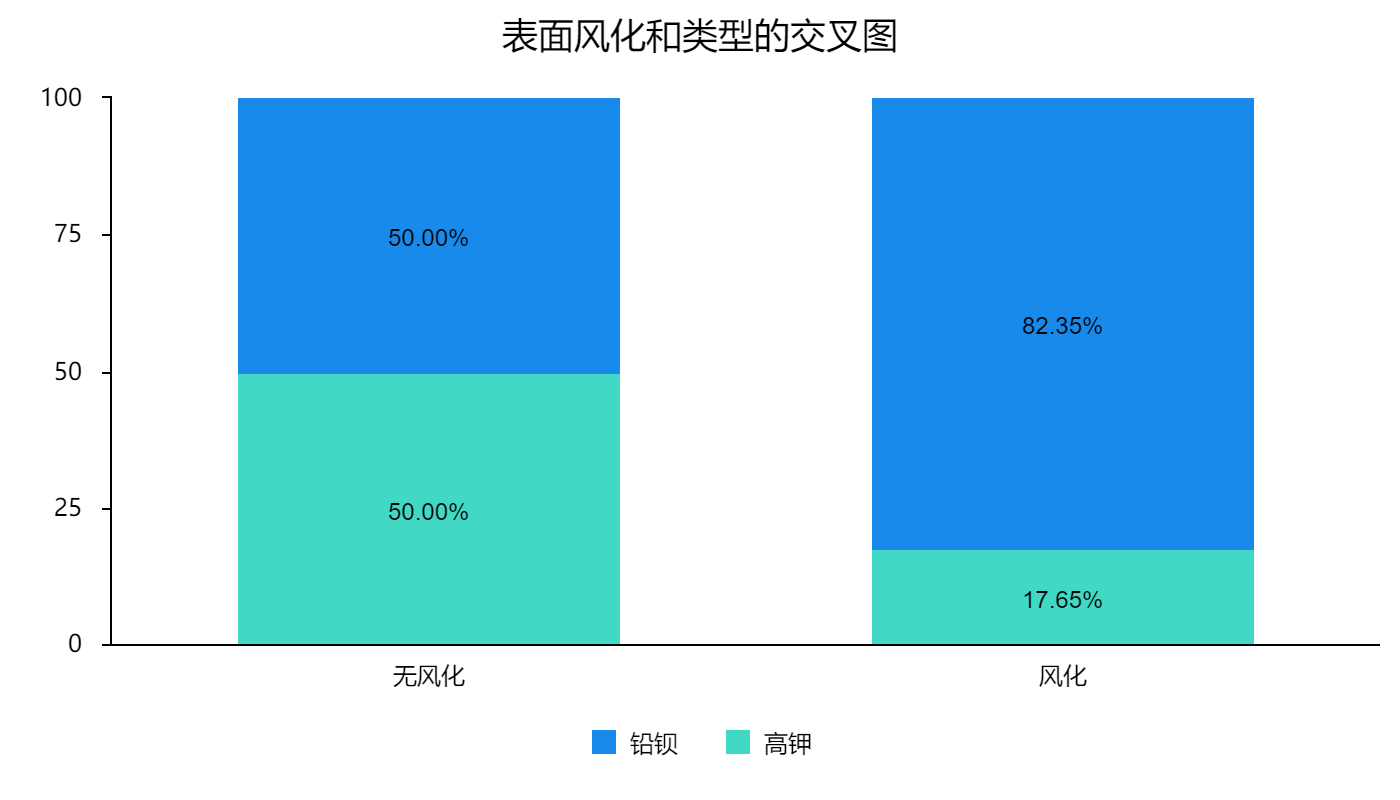
03 Images/简单均值分类模型流程图.png
0 → 100644
{kind=link}

1.4 MB
03 Images/简单均值分类模型流程图.vsdx
0 → 100644
文件已添加
03 Images/绘图.pptx
0 → 100644
文件已添加
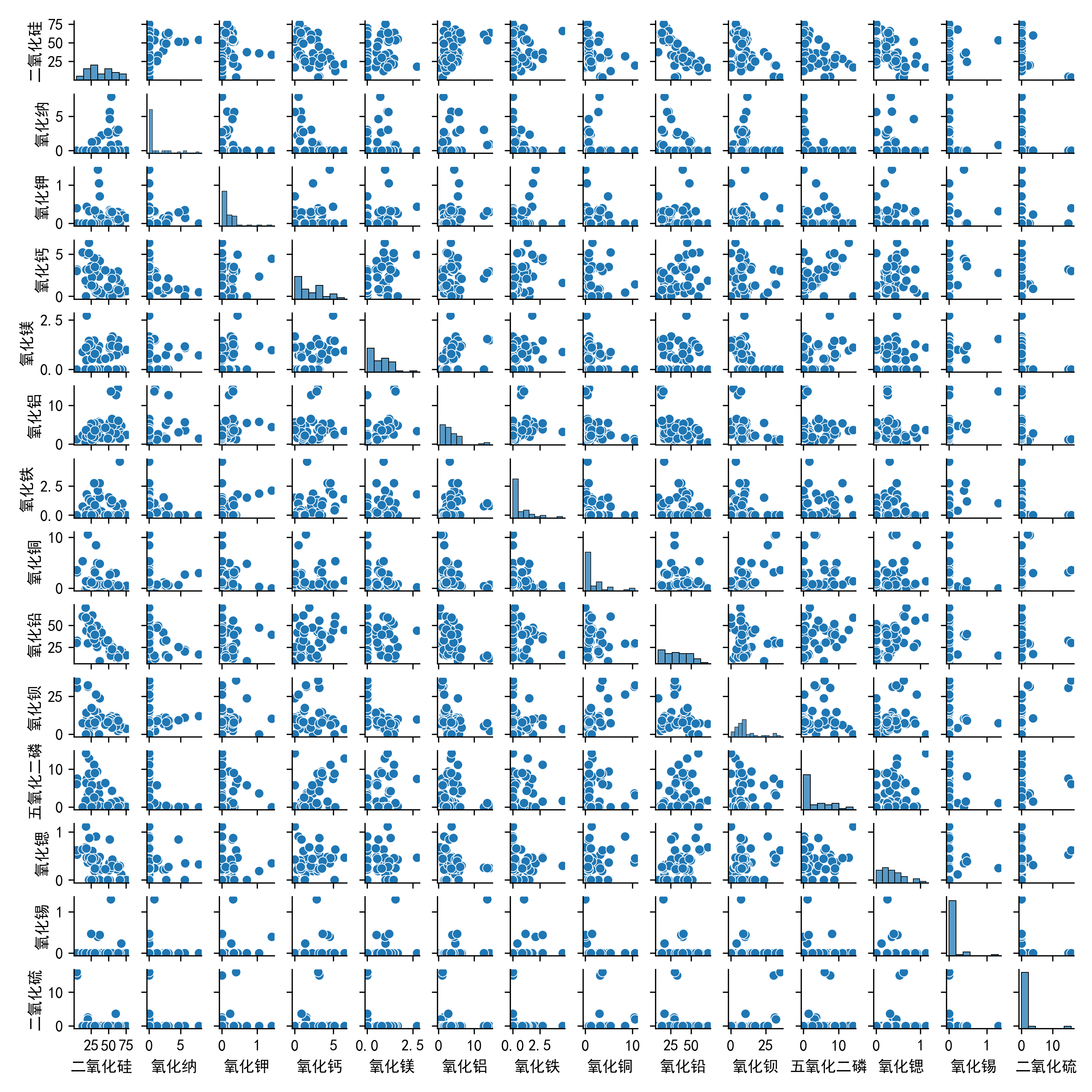
03 Images/铅钡玻璃化学成分散点图.png
0 → 100644
{kind=link}
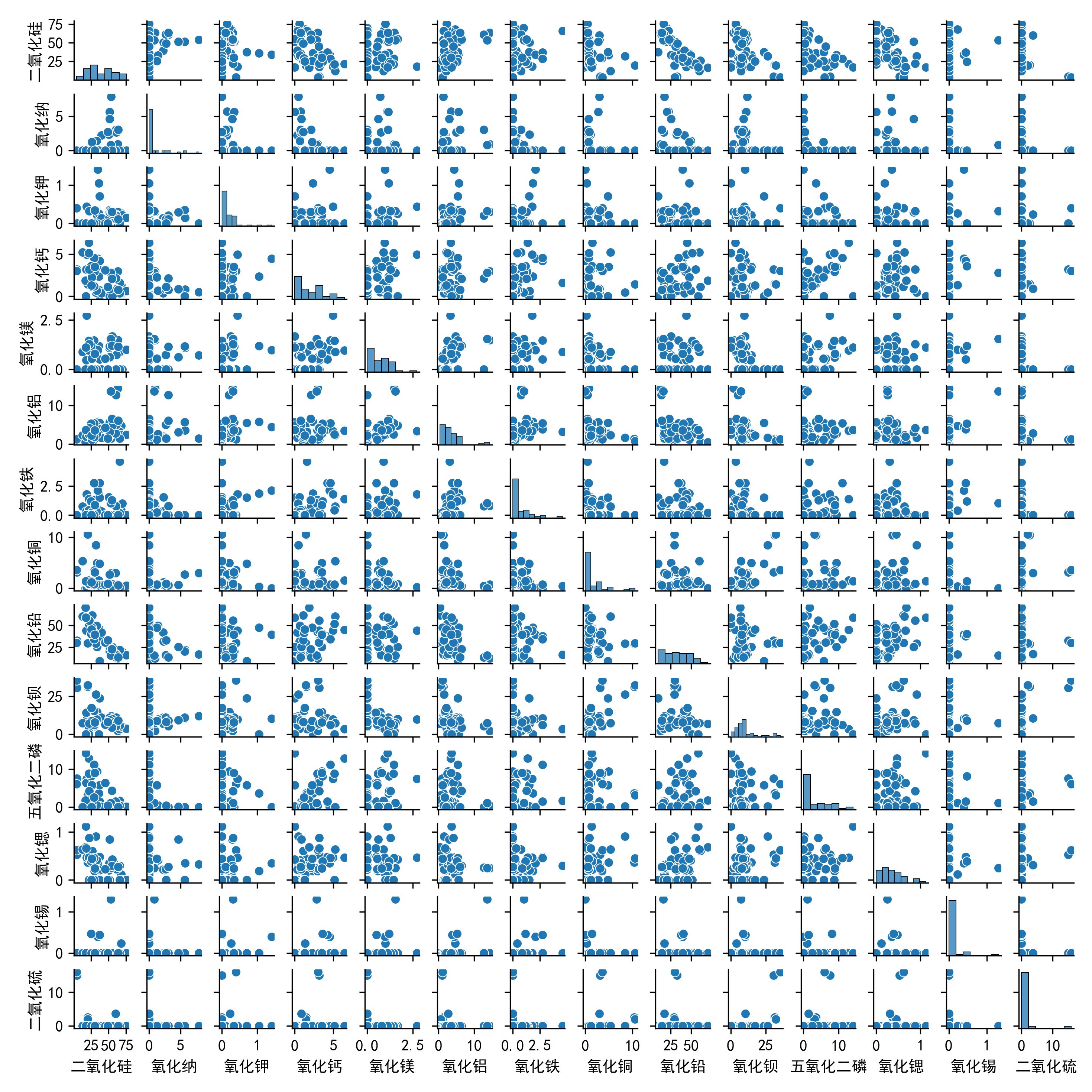
788.3 KB
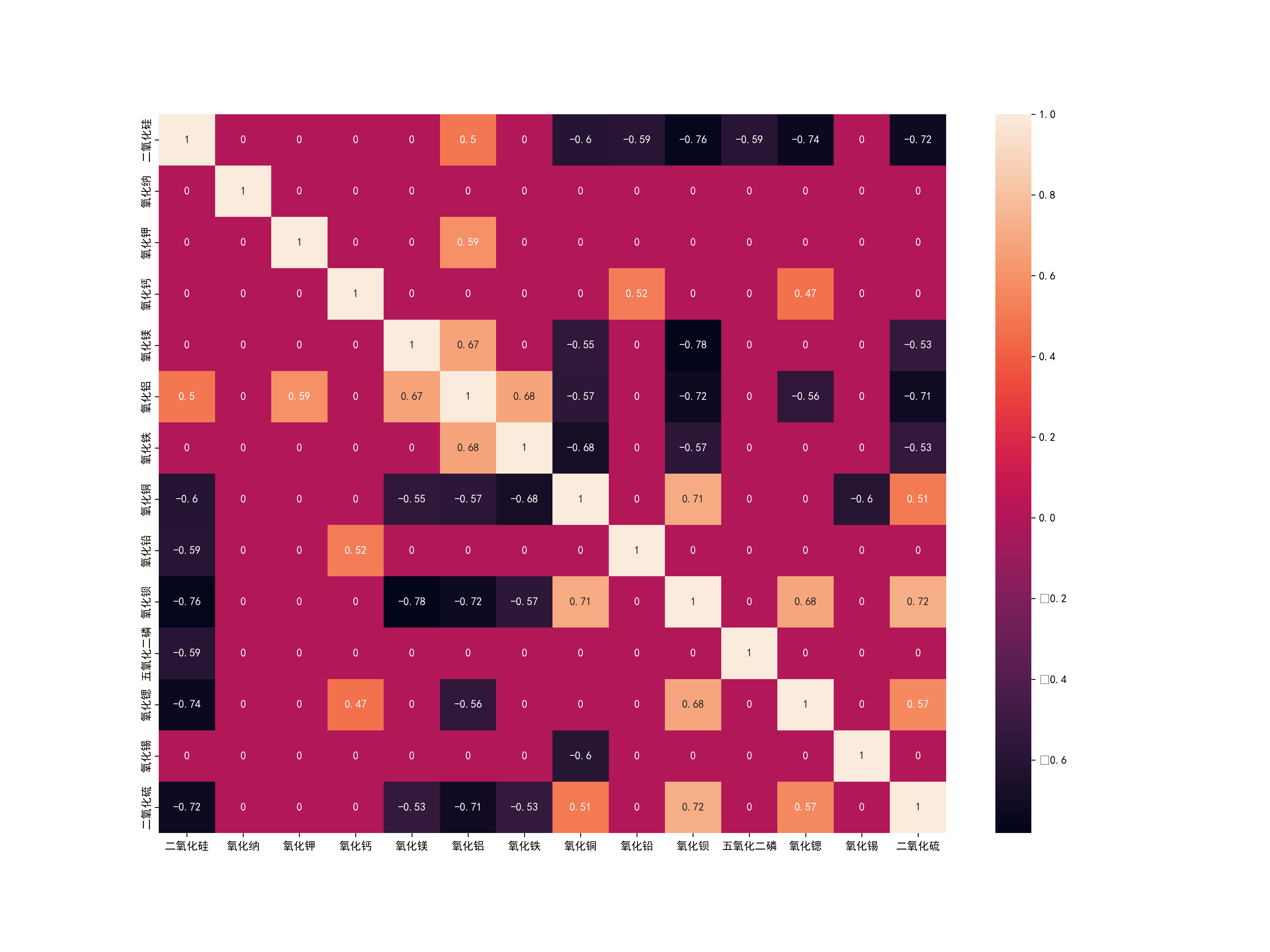
03 Images/铅钡玻璃化学成分相关系数热力图.png
0 → 100644
{kind=link}
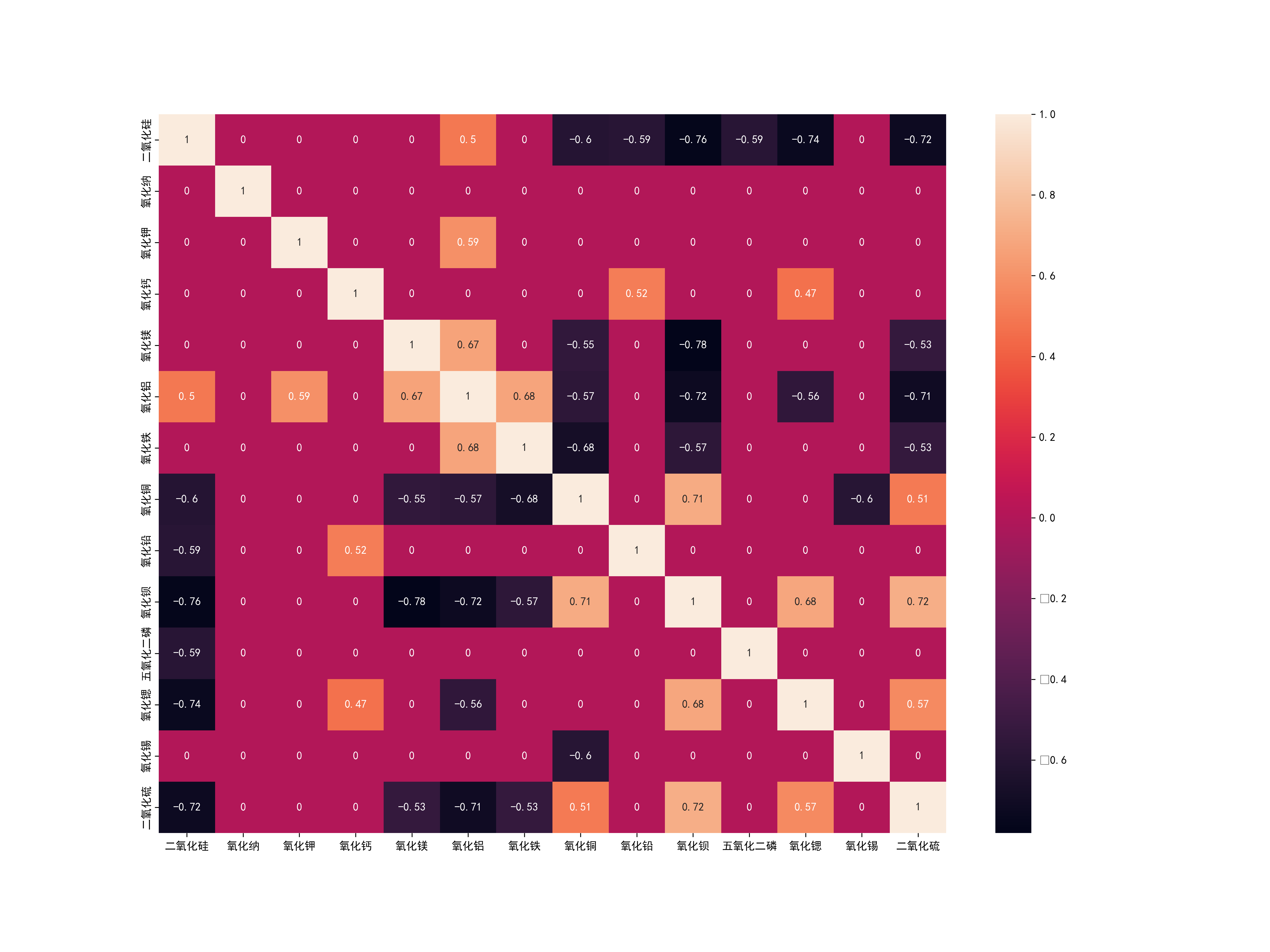
324.1 KB
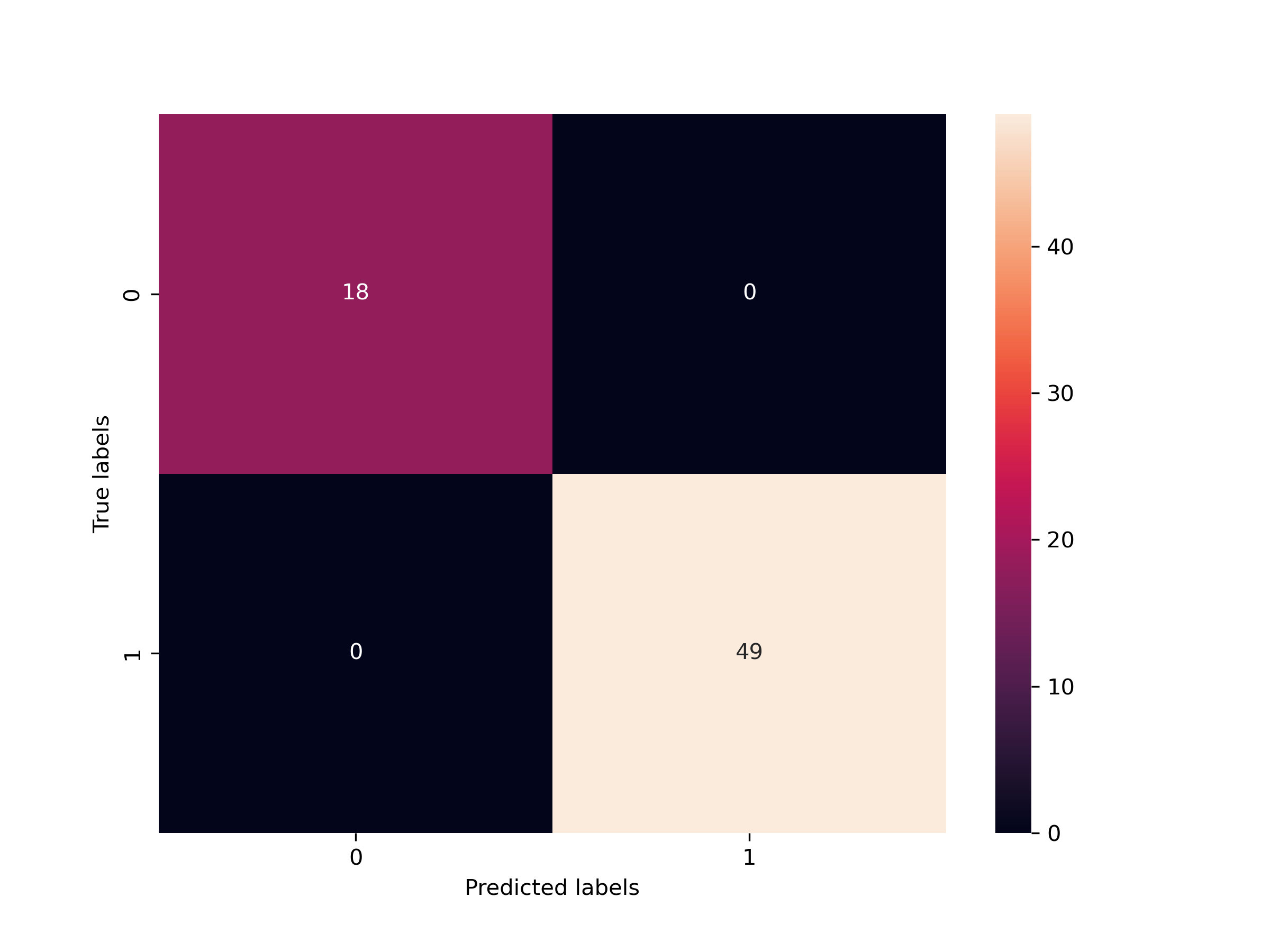
03 Images/问题三敏感性分析.png
0 → 100644
{kind=link}
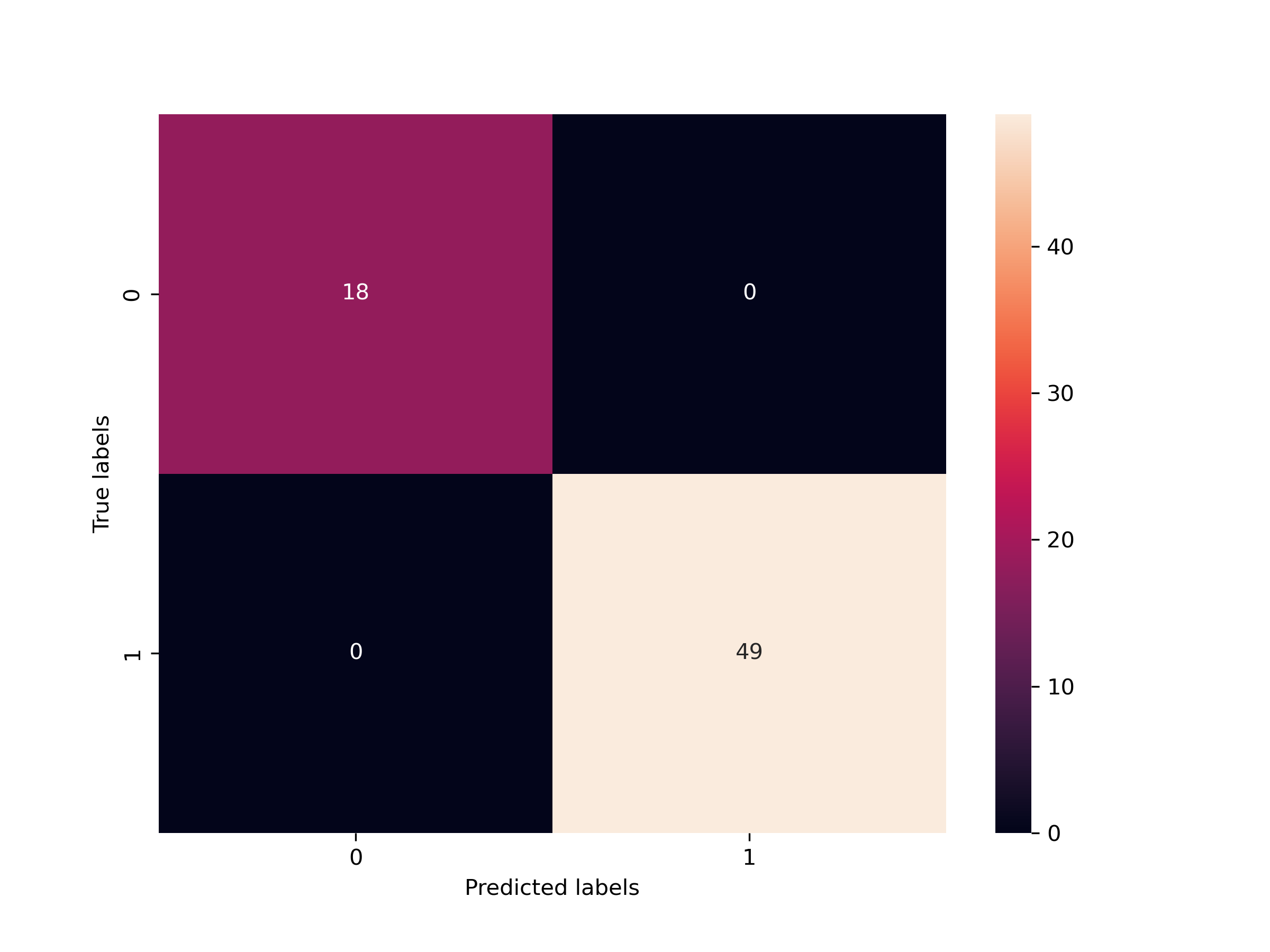
46.0 KB
03 Images/问题三流程图.png
0 → 100644
{kind=link}

336.7 KB
03 Images/问题三流程图.vsdx
0 → 100644
文件已添加
03 Images/高钾玻璃化学成分散点图.png
0 → 100644
{kind=link}

452.4 KB
03 Images/高钾玻璃化学成分相关系数热力图.png
0 → 100644
{kind=link}
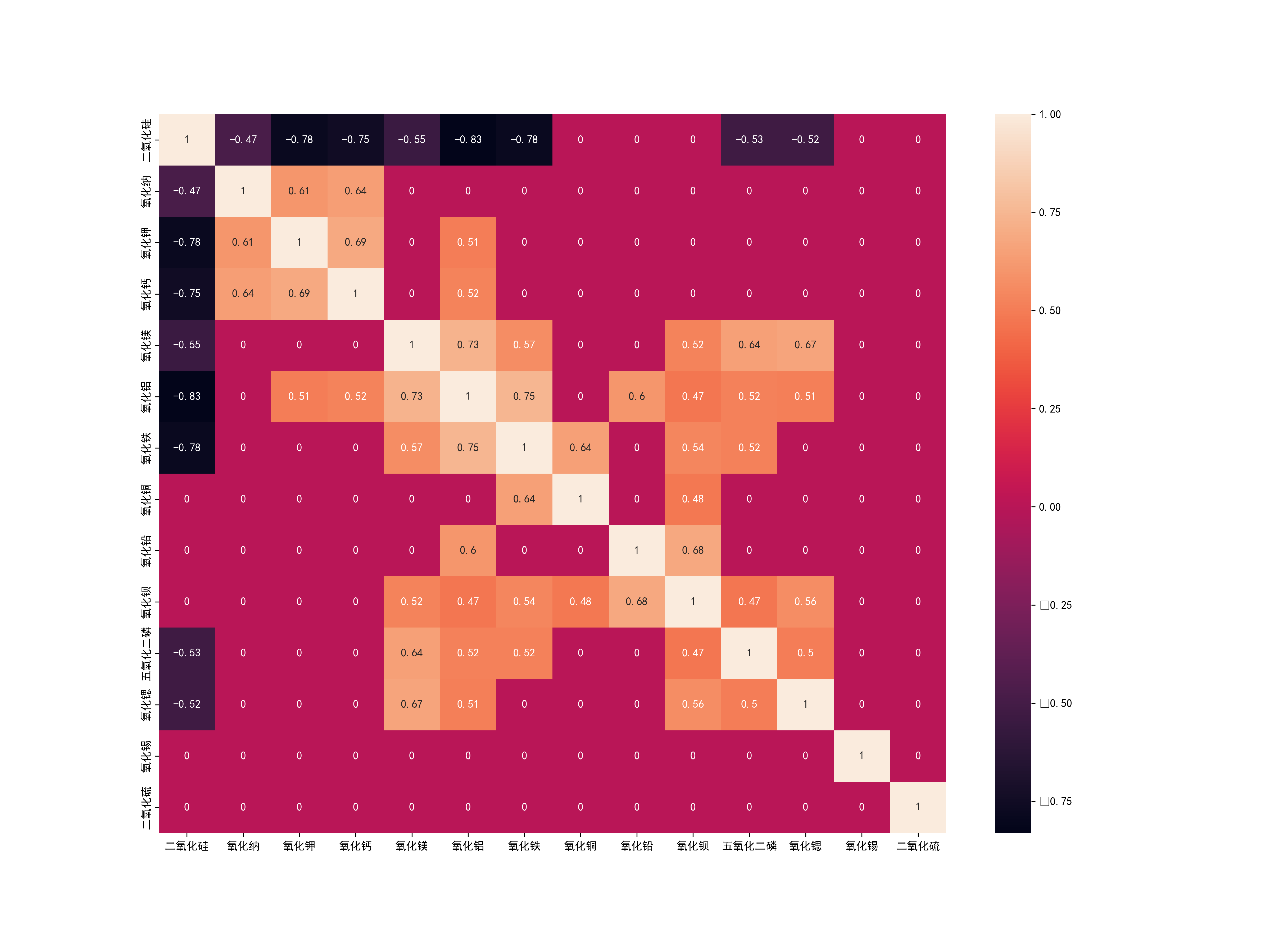
333.8 KB
05 Wskh/Java/CUMCM2022/pom.xml
0 → 100644
文件已添加
文件已添加
文件已添加
文件已添加
文件已添加
文件已添加
文件已添加
文件已添加
文件已添加
文件已添加
文件已添加
文件已添加
文件已添加
09 Submit/C题论文.pdf
0 → 100644
文件已添加
09 Submit/MD5码提交成功证明截图.png
0 → 100644
{kind=link}

116.2 KB
09 Submit/成功提交参数作品证明截图.png
0 → 100644
{kind=link}
107.3 KB
09 Submit/支撑材料.rar
0 → 100644
文件已添加
{kind=link}
1.4 MB
文件已添加
{kind=link}
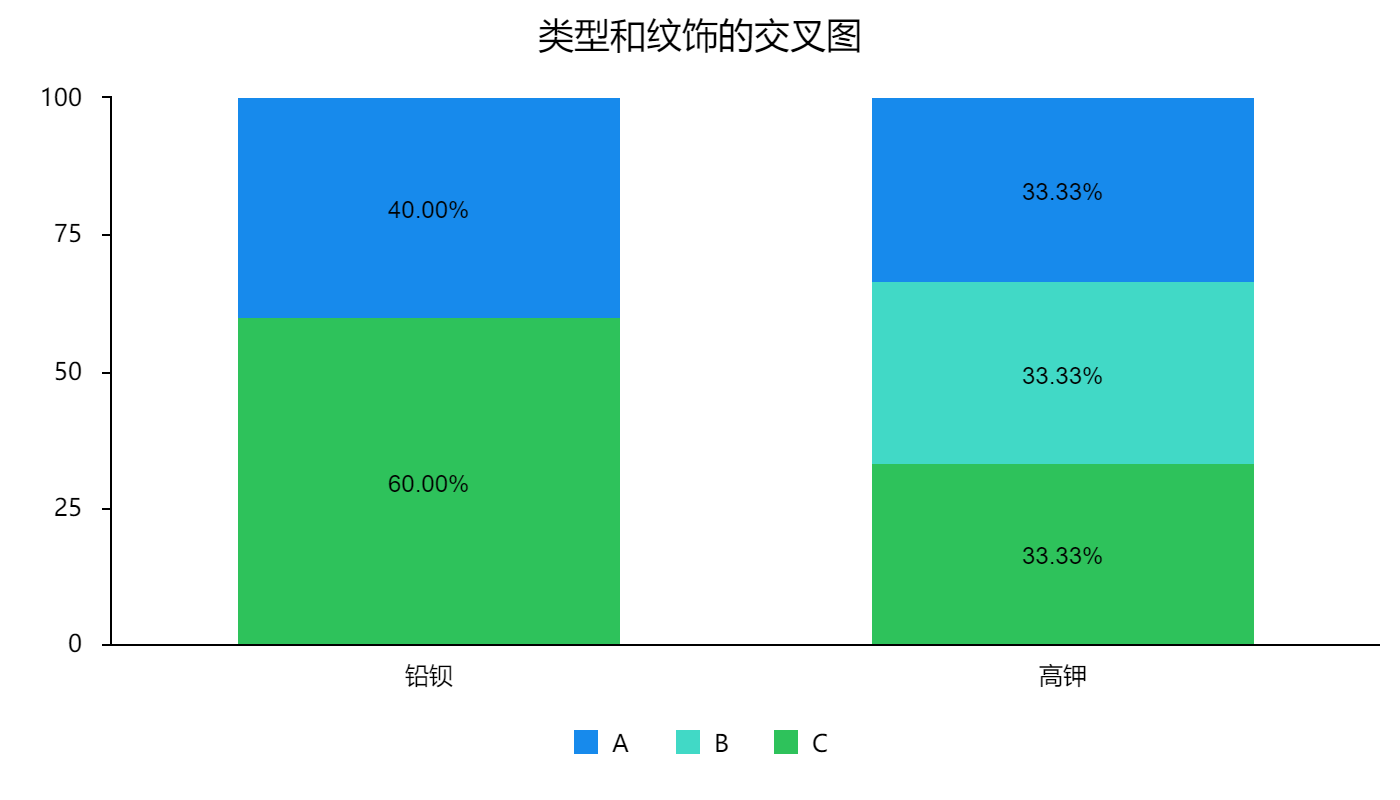
66.1 KB
{kind=link}
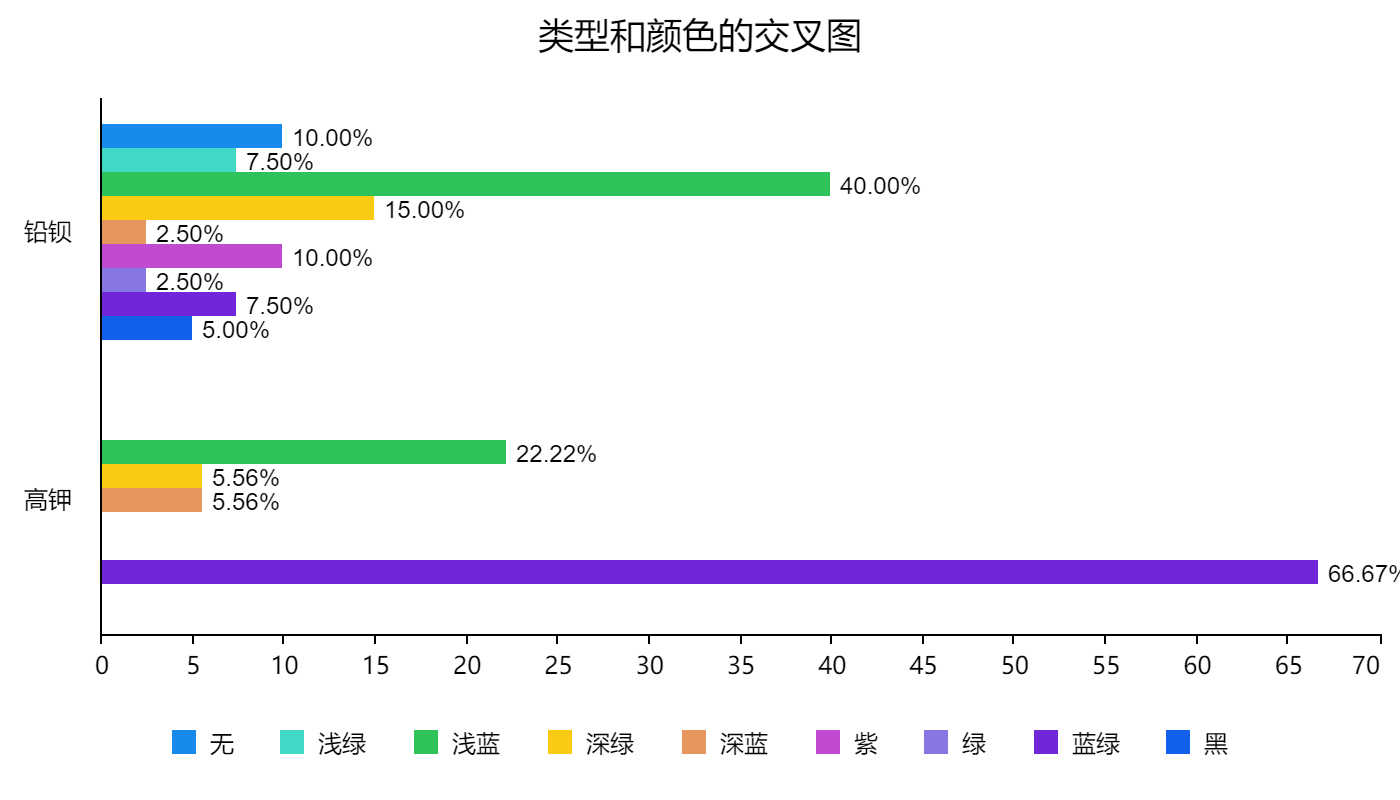
76.2 KB
09 Submit/支撑材料/01 Images/绘图.pptx
0 → 100644
文件已添加
{kind=link}
65.8 KB
{kind=link}
788.3 KB
{kind=link}
324.1 KB
{kind=link}
46.0 KB
{kind=link}

336.7 KB
文件已添加
{kind=link}

452.4 KB
{kind=link}
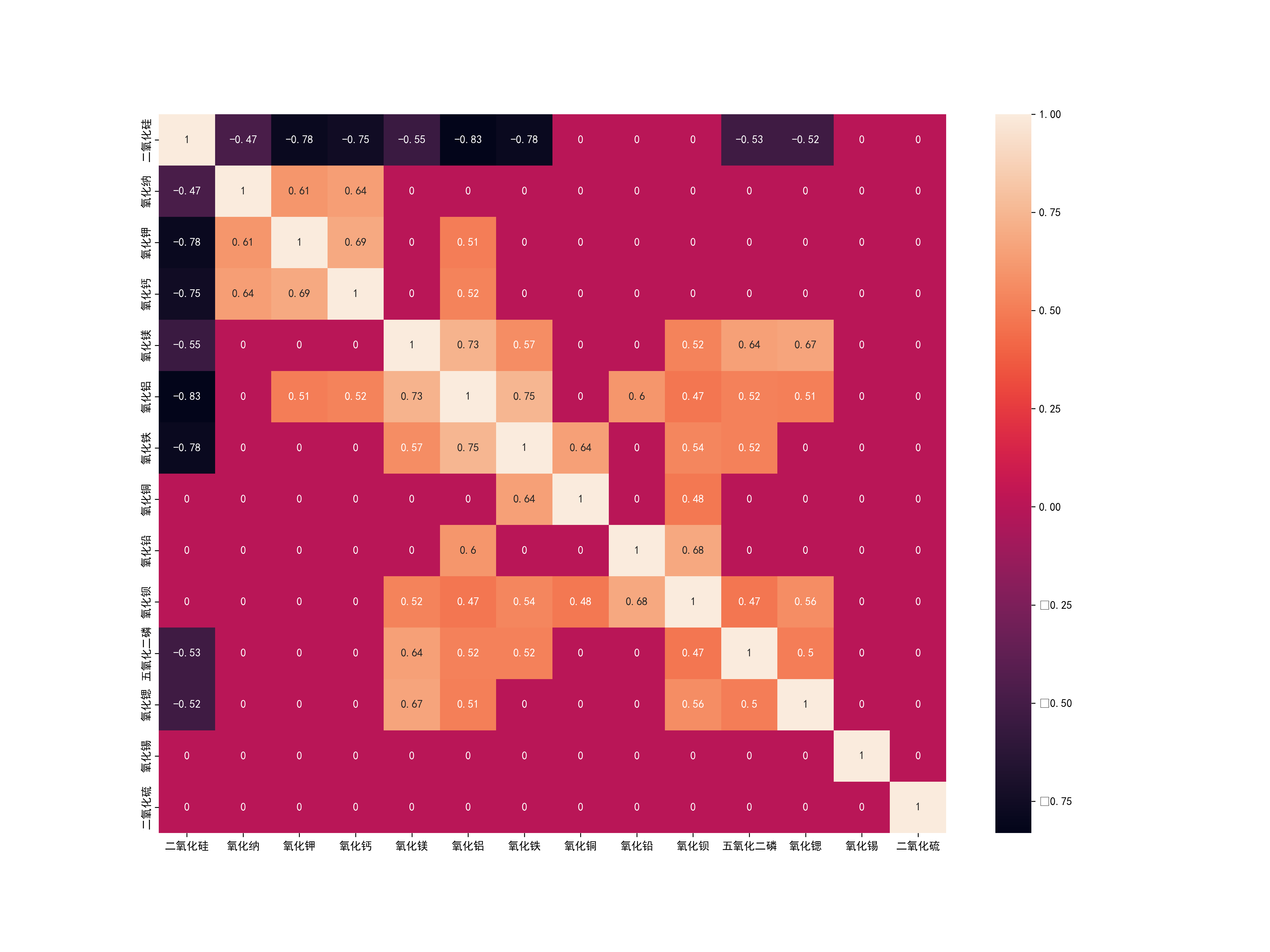
333.8 KB
文件已添加
文件已添加
文件已添加
文件已添加
文件已添加
文件已添加
文件已添加
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。