In Neural Network, the backpropagation algorithm follows the chain rule, so we need to compound the fundmental gradient operators/expressions together with chain rule . Every forward network need a backward network to construct the full computation graph, the operator/expression's backward pass will be generated respect to forward pass.
In Neural Network, the backpropagation algorithm follows the chain rule, so we need to compound the gradient operators/expressions together with the chain rule. Every forward network needs a backward network to construct the full computation graph, the operator/expression's backward pass will be generated respect to forward pass.
## Backward Operator Registry
A backward network is built up with several backward operators. Backward operators take forward operators' inputs, outputs and output gradients and then calculate its input gradients.
A backward network is built up with several backward operators. Backward operators take forward operators' inputs outputs, and output gradients and then calculate its input gradients.
In most cases, there is a one-to-one correspondence between forward and backward operators. These correspondences are recorded by a global hash map(`OpInfoMap`). To follow the philosophy of minimum core and make operators pluggable, the registry mechanism is introduced.
In most cases, there is a one-to-one correspondence between the forward and backward operators. These correspondences are recorded by a global hash map(`OpInfoMap`). To follow the philosophy of minimum core and make operators pluggable, the registry mechanism is introduced.
For example, we have got a `mul_op`, and we can register it's information and corresponding backward operator by the following macro:
For example, we have got a `mul_op`, and we can register its information and corresponding backward operator by the following macro:
The function `BuildGradOp` will sequentially execute following processes:
1. Get the `type_` of given forward operator, and then get the corresponding backward operator's type by looking up the `OpInfoMap`.
2. Build two maps named `inputs` and `outputs` to temporary storage backward operator's inputs and outputs. Copy forward operator's `inputs_` and `outputs_` to map `inputs`, except these are not necessary for gradient computing.
2. Build two maps named `inputs` and `outputs` to temporary storage backward operator's inputs and outputs. Copy forward operator's `inputs_` and `outputs_` to map `inputs`, except these, are not necessary for gradient computing.
3. Add forward inputs' gradient variables into map `output`, adding forward outputs' gradient variables into map `input`.
...
...
@@ -49,31 +49,31 @@ A backward network is a series of backward operators. The main idea of building
In our design, the network itself is also a kind of operator. So the operators contained by a big network may be some small network.
given a forward network, it generates the backward network. We only care about the Gradients—`OutputGradients`,`InputGradients`.
given a forward network, it generates the backward network. We only care about the Gradients—`OutputGradients`,`InputGradients`.
1. Op
when the input forward network is a Op, return its gradient Operator Immediately.
when the input forward network is an Op, return its gradient Operator Immediately.
2. NetOp
when the input forward network is a NetOp, it need to call the sub NetOp/Operators backward function recursively. During the process, we need to collect the `OutputGradients` name according to forward NetOp.
when the input forward network is a NetOp, it needs to call the sub NetOp/Operators backward function recursively. During the process, we need to collect the `OutputGradients` name according to the forward NetOp.
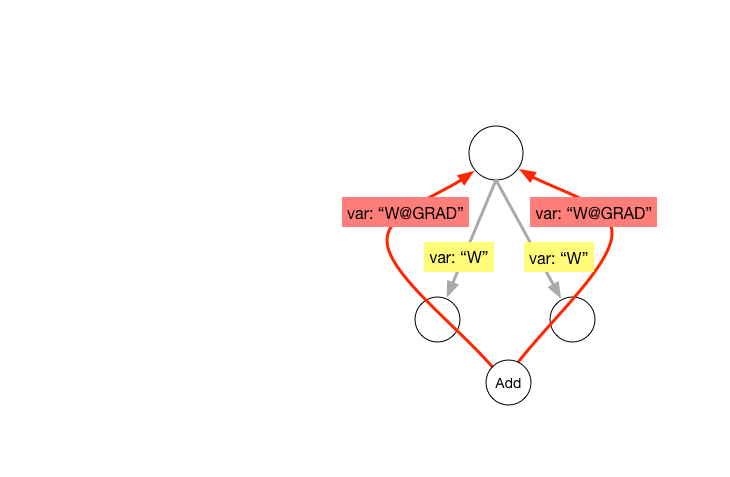
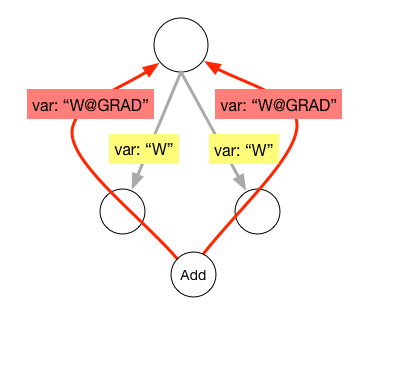
**shared variable**. As illustrated in the pictures, two operator's `Output``Gradient` will overwirte their shared input variable.
**shared variable**. As illustrated in the pictures, two operator's `Output``Gradient` will overwrite their shared input variable.
Share variable between operators or same input variable used in multiple operators lead to a duplicate gradient variable. As demo show above, we need to rename gradient name recursively, and add a generic add operator replace the overwirte links.
Share variable between operators or same input variable used in multiple operators leads to a duplicate gradient variable. As demo show above, we need to rename gradient name recursively and add a generic add operator replace the overwrite links.
{kind=link}
{kind=link}