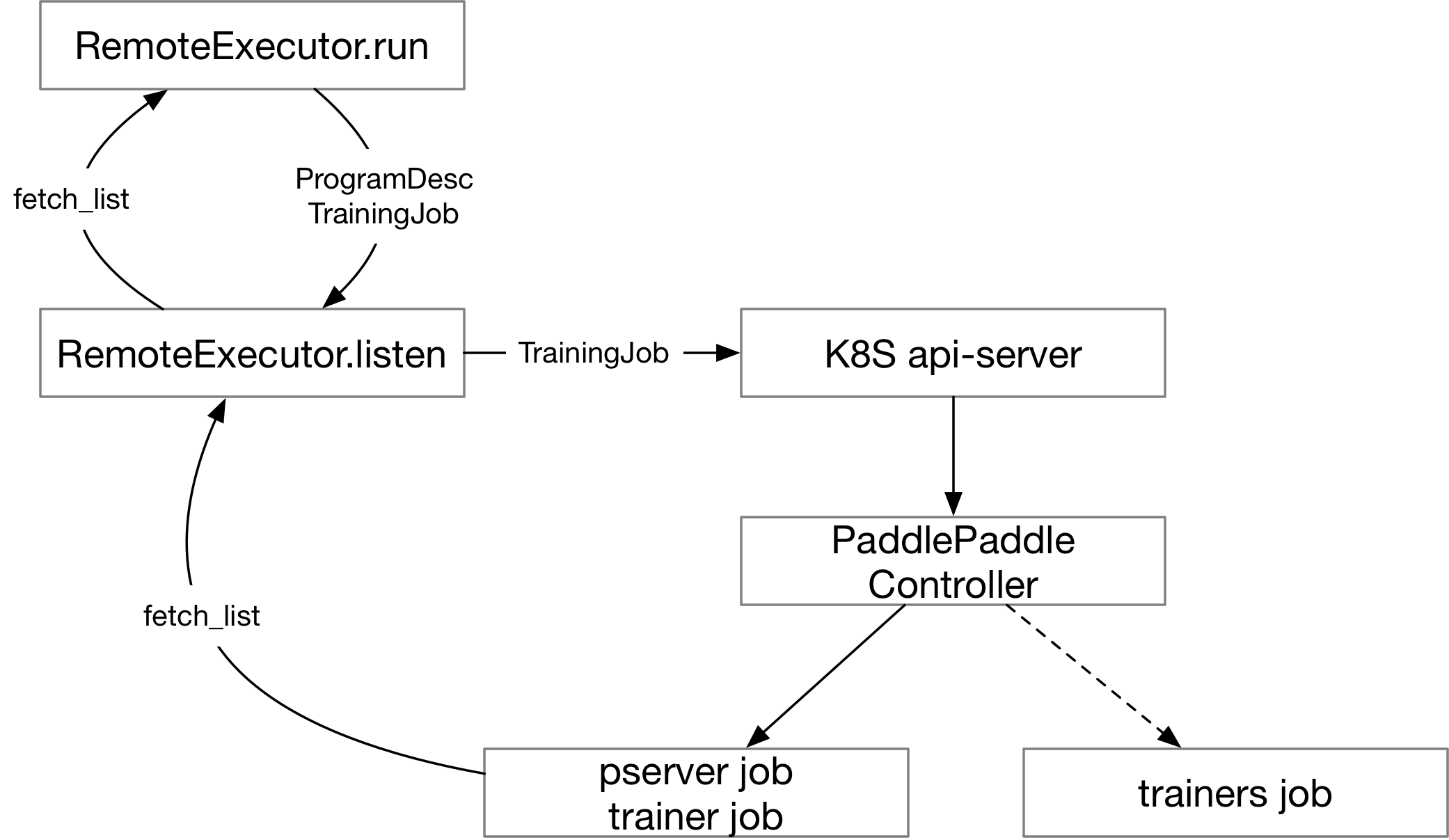
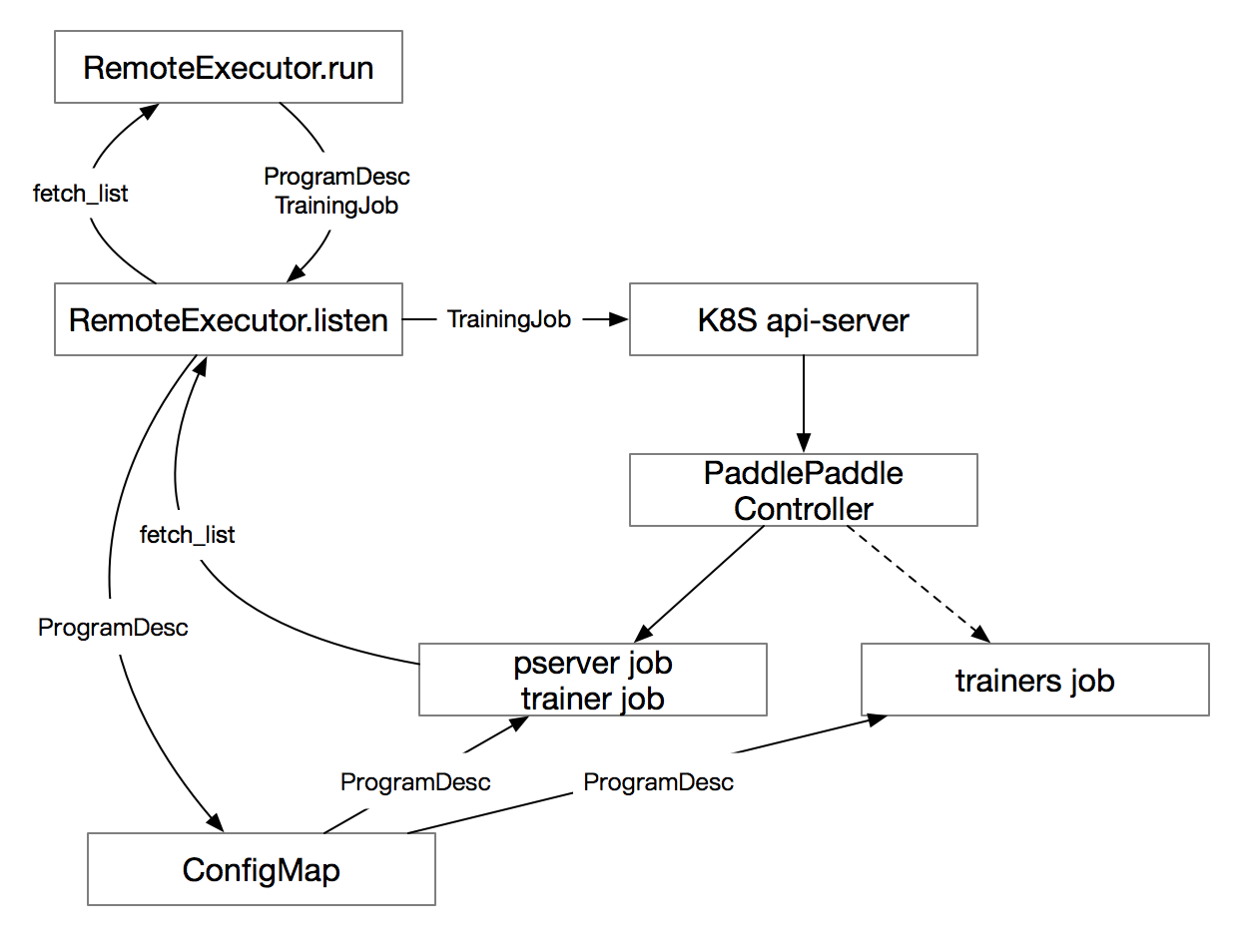
@@ -16,6 +16,12 @@ PaddlePaddle must be installed on all nodes. If you have GPU cards on your nodes
PaddlePaddle build and installation guide can be found [here](http://www.paddlepaddle.org/docs/develop/documentation/en/getstarted/build_and_install/index_en.html).
In addition to above, the `cmake` command should be run with the option `WITH_DISTRIBUTE` set to on. An example bare minimum `cmake` command would look as follows:
Please find the complete demo from [here](https://github.com/PaddlePaddle/Paddle/blob/develop/python/paddle/v2/fluid/tests/book_distribute/notest_dist_fit_a_line.py). In parameter server node run the following in the command line:
Please find the complete demo from [here](https://github.com/PaddlePaddle/Paddle/blob/develop/python/paddle/v2/fluid/tests/book_distribute/notest_dist_fit_a_line.py).
First `cd` into the folder that contains the `python` files. In this case:
```bash
cd /paddle/python/paddle/v2/fluid/tests/book_distribute
```
In parameter server node run the following in the command line:
{kind=link}
{kind=link}