Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
wmsofts
Paddle
提交
635a69ba
P
Paddle
项目概览
wmsofts
/
Paddle
与 Fork 源项目一致
Fork自
PaddlePaddle / Paddle
通知
1
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
Paddle
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
体验新版 GitCode,发现更多精彩内容 >>
提交
635a69ba
编写于
12月 06, 2017
作者:
Y
ying
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
add doc for how to use C-API.
上级
229c2e78
变更
13
隐藏空白更改
内联
并排
Showing
13 changed file
with
677 addition
and
23 deletion
+677
-23
doc/howto/index_cn.rst
doc/howto/index_cn.rst
+1
-0
doc/howto/usage/capi/a_simple_example.md
doc/howto/usage/capi/a_simple_example.md
+211
-0
doc/howto/usage/capi/compile_paddle_lib.md
doc/howto/usage/capi/compile_paddle_lib.md
+68
-0
doc/howto/usage/capi/core_concepts.md
doc/howto/usage/capi/core_concepts.md
+0
-0
doc/howto/usage/capi/images/csr.png
doc/howto/usage/capi/images/csr.png
+0
-0
doc/howto/usage/capi/organization_of_the_inputs.md
doc/howto/usage/capi/organization_of_the_inputs.md
+154
-0
doc/howto/usage/capi/overview.md
doc/howto/usage/capi/overview.md
+5
-0
paddle/capi/examples/model_inference/dense/main.c
paddle/capi/examples/model_inference/dense/main.c
+42
-18
paddle/capi/examples/model_inference/dense/merge_v2_model.py
paddle/capi/examples/model_inference/dense/merge_v2_model.py
+8
-0
paddle/capi/examples/model_inference/dense/mnist_v2.py
paddle/capi/examples/model_inference/dense/mnist_v2.py
+117
-0
paddle/capi/examples/model_inference/sparse_binary/main.c
paddle/capi/examples/model_inference/sparse_binary/main.c
+7
-4
python/paddle/utils/dump_v2_config.py
python/paddle/utils/dump_v2_config.py
+62
-0
python/paddle/utils/merge_model.py
python/paddle/utils/merge_model.py
+2
-1
未找到文件。
doc/howto/index_cn.rst
浏览文件 @
635a69ba
...
...
@@ -12,6 +12,7 @@
usage/k8s/k8s_basis_cn.md
usage/k8s/k8s_cn.md
usage/k8s/k8s_distributed_cn.md
usage/capi/overview.md
开发标准
--------
...
...
doc/howto/usage/capi/a_simple_example.md
0 → 100644
浏览文件 @
635a69ba
## 使用 C-API 开发预测程序
这篇文档通过一个最简单的例子:手写数字识别,来介绍 CPU 下单线程使用 PaddlePaddle C-API 开发预测服务,完整代码见
[
此目录
](
https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/capi/examples/model_inference/dense/
)
。
### 使用流程
使用 C-API 分为:准备工作和预测程序开发两部分。
-
准备
1.
将神经网络模型结构进行序列化。
-
调用C-API预测时,需要提供序列化之后的网络结构和训练好的模型参数文件。
1.
将PaddlePaddle训练出的模型参数文件(多个)合并成一个文件。
-
神经网络模型结构和训练好的模型将被序列化合并入一个文件。
-
预测时只需加载这一个文件,便于发布。
-
**注意**
:以上两种方式只需选择其一即可。
-
调用 PaddlePaddle C-API 开发预测序
1.
初始化PaddlePaddle运行环境。
1.
创建神经网络的输入,组织输入数据。
1.
加载模型。
1.
进行前向计算,获得计算结果。
1.
清理。
这里我们以手写数字识别任务为例,介绍如何使用 C-API 进行预测,完整代码请查看
[
此目录
](
https://github.com/PaddlePaddle/Paddle/tree/develop/paddle/capi/examples/model_inference/dense
)
。
运行目录下的
`python mnist_v2.py`
可以使用 PaddlePaddle 内置的
[
MNIST 数据集
](
http://yann.lecun.com/exdb/mnist/
)
进行训练。脚本中的模型定义了一个简单的含有
[
两个隐层的全连接网络
](
https://github.com/PaddlePaddle/book/blob/develop/02.recognize_digits/README.cn.md#softmax回归softmax-regression
)
,网络接受一幅图片作为输入,将图片分类到 0 ~ 9 类别标签之一。训练好的模型默认保存在当前运行目录下的
`models`
目录中。下面,我们将调用 C-API 加载训练好的模型进行预测。
### 外部准备
1.
序列化神经网络模型配置
PaddlePaddle 使用 protobuf 来传输网络配置文件中定义的网络结构和相关参数,在使用 C-API 进行预测时,也需将网络结构使用 protobuf 进行序列化,写入文件中。
调用`paddle.utils.dump_v2_config`中的`dump_v2_config`函数能够将使用 PaddlePaddle V2 API 定义的神经网络结构 dump 到指定文件中。示例代码如下:
```python
from paddle.utils.dump_v2_config import dump_v2_config
from mnist_v2 import network
predict = network(is_infer=True)
dump_v2_config(predict, "trainer_config.bin", True)
```
对本例,或运行 `python mnist_v2.py --task dump_config`,会对示例中的网络结构进行序列化,并将结果写入当前目录下的`trainer_config.bin`文件中。
当选择使用这种方式调用 C-API 时,如果神经网络有多个可学习参数,请将它们全部放在同一文件夹内,C-API会从指定的目录寻找并加载训练好的模型。
2.
合并模型文件(可选)
一些情况下为了便于发布,希望能够将序列化后的神经网络结构和训练好的模型参数打包进一个文件,这时可以使用`paddle.utils.merge_model`中的`merge_v2_model`接口对神经网络结构和训练好的参数进行序列化,将序列化结果写入一个文件内,调用C-API时直接只需加载这一个文件。
代码示例如下:
```python
from paddle.utils.merge_model import merge_v2_model
from mnist_v2 import network
net = network(is_infer=True)
param_file = "models/params_pass_4.tar"
output_file = "output.paddle.model"
merge_v2_model(net, param_file, output_file)
```
对本例,或者直接运行 `python merge_v2_model.py`,序列化结果将会写入当前目录下的`output.paddle.model`文件中,该文件在调用C-API时,可被直接加载。
#### 注意事项
1.
C-API 需要序列化之后神经网络结构,在调用
`dump_v2_config`
时,参数
`binary`
必须指定为
`True`
。
1.
**预测使用的网络结构往往不同于训练**
,通常需要去掉网络中的:(1)类别标签层;(2)损失函数层;(3)
`evaluator`
等,只留下核心计算层,请注意是否需要修改网络结构。
1.
预测时,可以获取网络中定义的任意多个(大于等于一个)层前向计算的结果,需要哪些层的计算结果作为输出,就将这些层加入一个Python list中,作为调用
`dump_v2_config`
的第一个参数。
### 编写预测代码
#### step 1. 初始化及加载模型
1.
初始化PaddlePaddle运行环境。
```
c
// Initalize the PaddlePaddle runtime environment.
char
*
argv
[]
=
{
"--use_gpu=False"
};
CHECK
(
paddle_init
(
1
,
(
char
**
)
argv
));
```
1.
加载训练好的模型。
这里需要介绍C-API使用中的一个重要概念:Gradient Machine。概念上,在 PaddlePaddle 内部,一个GradientMachine类的对象管理着一组计算层(PaddlePaddle Layers)来完成前向和反向计算,并处理与之相关的所有细节。特别的,在调用C-API预测时只需进行前向计算。这篇文档的之后部分我们会使用`gradient machine`来特指调用PaddlePaddle C-API创建的GradientMachine类的对象。
每一个 `gradient machine` 都会管理维护一份训练好的模型,模型可以通过以下两种方式获取:
1. 从磁盘加载;这时`gradient machine`会独立拥有一份训练好的模型;
1. 共享自其它`gradient machine`的模型;这种情况多出现在使用多线程预测时;
下面的代码片段创建 `gradient machine`,并从指定路径加载训练好的模型。
```c
// Read the binary configuration file generated by `convert_protobin.sh`
long size;
void* buf = read_config(CONFIG_BIN, &size);
// Create the gradient machine for inference.
paddle_gradient_machine machine;
CHECK(paddle_gradient_machine_create_for_inference(&machine, buf, (int)size));
// Load the trained model. Modify the parameter MODEL_PATH to set the correct
// path of the trained model.
CHECK(paddle_gradient_machine_load_parameter_from_disk(machine, MODEL_PATH));
```
##### 注意事项
1.
以上代码片段使用“仅序列化神经网络结构”的方式加载模型,需要同时指定模型参数存储的路径。
-
使用PaddlePaddle V2 API训练,模型中所有可学习参数会被存为一个压缩文件,需要手动进行解压,将它们放在同一目录中,C-API不会直接加载 V2 API 存储的压缩文件。
1.
如果使用
`merge model`
方式将神经网络结构和训练好的参数序列化到一个文件,请参考此
[
示例
](
https://github.com/PaddlePaddle/Mobile/blob/develop/Demo/linux/paddle_image_recognizer.cpp#L59
)
。
#### step 2. 创建神经网络输入,组织输入数据
基本使用概念:
-
在PaddlePaddle内部,神经网络中一个计算层的输入/输出被组织为一个
`Argument`
结构体,如果神经网络有多个输入或者多个输入,每一个输入/输入都会对应有自己的
`Argument`
。
-
`Argument`
并不真正“存储”数据,而是将输入/输出数据有机地组织在一起。
-
在
`Argument`
内部由:1.
`Matrix`
(二维矩阵,存储浮点类型输入/输出);2.
`IVector`
(一维数组,
**仅用于存储整型值**
,多用于自然语言处理任务)来实际存储数据。
*注:这篇文档使用的示例任务手写数字识别不涉及一维整型序列输入/输出,因此不讨论一维整型输入/输出数据相关的内容。更多信息请参考:[输入数据组织](organization_of_the_inputs.md)。*
在这篇文档的后面部分,我们会使用
`argument`
来
**特指**
PaddlePaddle C-API中神经网的一个输入/输出,使用
`matrix`
**特指**
`argument`
中用于存储数据的
`Matrix`
类的对象,用
`ivector`
特指
`argument`
中用于存储数据的
`IVector`
类的对象。
于是,在组织神经网络输入,获取输出时,需要思考完成以下工作:
1.
为每一个输入/输出创建
`argument`
;
1.
为每一个
`argument`
创建
`matrix`
或者
`ivector`
来存储数据;
与输入不同的是,输出
`argument`
的
`matrix`
变量并不需在使用C-API时为之要分配存储空间。PaddlePaddle内部,神经网络进行前向计算时会自己分配/管理每个计算层的存储空间;这些细节C-API会代为处理,只需在概念上理解,并按照约定调用相关的 C-API 接口即可。
下面是示例代码片段。在这段代码中,生成了一条随机输入数据作为测试样本。
```
c
// Inputs and outputs of the network are organized as paddle_arguments object
// in C-API. In the comments below, "argument" specifically means one input of
// the neural network in PaddlePaddle C-API.
paddle_arguments
in_args
=
paddle_arguments_create_none
();
// There is only one data layer in this demo MNIST network, invoke this
// function to create one argument.
CHECK
(
paddle_arguments_resize
(
in_args
,
1
));
// Each argument needs one matrix or one ivector (integer vector, for sparse
// index input, usually used in NLP task) to holds the real input data.
// In the comments below, "matrix" specifically means the object needed by
// argument to hold the data. Here we create the matrix for the above created
// agument to store the testing samples.
paddle_matrix
mat
=
paddle_matrix_create
(
/* height = batch size */
1
,
/* width = dimensionality of the data layer */
784
,
/* whether to use GPU */
false
);
paddle_real
*
array
;
// Get the pointer pointing to the start address of the first row of the
// created matrix.
CHECK
(
paddle_matrix_get_row
(
mat
,
0
,
&
array
));
// Fill the matrix with a randomly generated test sample.
srand
(
time
(
0
));
for
(
int
i
=
0
;
i
<
784
;
++
i
)
{
array
[
i
]
=
rand
()
/
((
float
)
RAND_MAX
);
}
// Assign the matrix to the argument.
CHECK
(
paddle_arguments_set_value
(
in_args
,
0
,
mat
));
```
#### step 3. 前向计算
完成上述准备之后,通过调用
`paddle_gradient_machine_forward`
接口完成神经网络的前向计算。
示例代码片段如下:
```
c
// Create the output argument.
paddle_arguments
out_args
=
paddle_arguments_create_none
();
// Invoke the forward computation.
CHECK
(
paddle_gradient_machine_forward
(
machine
,
in_args
,
out_args
,
/* is train taks or not */
false
));
// Create the matrix to hold the forward result of the neural network.
paddle_matrix
prob
=
paddle_matrix_create_none
();
// Access the matrix of the output argument, the predicted result is stored in
// which.
CHECK
(
paddle_arguments_get_value
(
out_args
,
0
,
prob
));
uint64_t
height
;
uint64_t
width
;
CHECK
(
paddle_matrix_get_shape
(
prob
,
&
height
,
&
width
));
CHECK
(
paddle_matrix_get_row
(
prob
,
0
,
&
array
));
printf
(
"Prob:
\n
"
);
for
(
int
i
=
0
;
i
<
height
*
width
;
++
i
)
{
printf
(
"%.4f "
,
array
[
i
]);
if
((
i
+
1
)
%
width
==
0
)
{
printf
(
"
\n
"
);
}
}
printf
(
"
\n
"
);
```
#### step 4. 清理
结束预测之后,对使用的中间变量和资源进行清理和释放:
```
c
// The cleaning up.
CHECK
(
paddle_matrix_destroy
(
prob
));
CHECK
(
paddle_arguments_destroy
(
out_args
));
CHECK
(
paddle_matrix_destroy
(
mat
));
CHECK
(
paddle_arguments_destroy
(
in_args
));
CHECK
(
paddle_gradient_machine_destroy
(
machine
));
```
doc/howto/usage/capi/compile_paddle_lib.md
0 → 100644
浏览文件 @
635a69ba
## 编译 PaddlePaddle 链接库
使用 C-API 进行预测依赖于将 PaddlePaddle 核心代码编译成链接库,只需在编译时指定编译选项:
`-DWITH_C_API=ON`
。同时,
**建议将:`DWITH_PYTHON`,`DWITH_SWIG_PY`,`DWITH_GOLANG`,均设置为`OFF`**
,以避免链接不必要的库。其它编译选项按需进行设定。
```
shell
INSTALL_PREFIX
=
/path/of/capi/
PADDLE_ROOT
=
/path/of/paddle_source/
cmake
$PADDLE_ROOT
-DCMAKE_INSTALL_PREFIX
=
$INSTALL_PREFIX
\
-DCMAKE_BUILD_TYPE
=
Release
\
-DWITH_C_API
=
ON
\
-DWITH_SWIG_PY
=
OFF
\
-DWITH_GOLANG
=
OFF
\
-DWITH_PYTHON
=
OFF
\
-DWITH_MKLML
=
OFF
\
-DWITH_MKLDNN
=
OFF
\
-DWITH_GPU
=
OFF
\
...
```
在上面的代码片段中,
`PADDLE_ROOT`
表示 PaddlePaddle 源码所在目录,生成Makefile文件后执行:
`make && make install`
。成功执行后,使用CAPI所需的依赖(包括:(1)编译出的PaddlePaddle 链接和头文件;(2)第三方链接库和头文件)均会存放于
`INSTALL_PREFIX`
目录中。
编译成功后在
`INSTALL_PREFIX`
下会看到如下目录结构(包括了编译出的PaddlePaddle头文件和链接库,以及第三方依赖链接库和头文件(如果需要,由链接方式决定)):
```
text
├── include
│ └── paddle
│ ├── arguments.h
│ ├── capi.h
│ ├── capi_private.h
│ ├── config.h
│ ├── error.h
│ ├── gradient_machine.h
│ ├── main.h
│ ├── matrix.h
│ ├── paddle_capi.map
│ └── vector.h
├── lib
│ ├── libpaddle_capi_engine.a
│ ├── libpaddle_capi_layers.a
│ ├── libpaddle_capi_shared.dylib
│ └── libpaddle_capi_whole.a
└── third_party
├── ......
```
## 链接方式说明
目前提供三种链接方式:
1.
链接
`libpaddle_capi_shared.so`
动态库
-
使用 PaddlePaddle C-API 开发预测程序链接
`libpaddle_capi_shared.so`
时,需注意:
1.
如果编译时指定编译CPU版本,且使用
`OpenBLAS`
矩阵库,在使用CAPI开发预测程序时,只需要链接
`libpaddle_capi_shared.so`
这一个库。
1.
如果是用编译时指定CPU版本,且使用
`MKL`
矩阵库,由于
`MKL`
库有自己独立的动态库文件,在使用PaddlePaddle CAPI开发预测程序时,需要自己链接MKL链接库。
1.
如果编译时指定编译GPU版本,CUDA相关库会在预测程序运行时动态装载,需要将CUDA相关的库设置到
`LD_LIBRARY_PATH`
环境变量中。
-
这种方式最为简便,链接相对容易,
**在无特殊需求情况下,推荐使用此方式**
。
2.
链接静态库
`libpaddle_capi_whole.a`
-
使用PaddlePaddle C-API 开发预测程序链接
`libpaddle_capi_whole.a`
时,需注意:
1.
需要指定
`-Wl,--whole-archive`
链接选项。
1.
需要显式地链接
`gflags`
、
`glog`
、
`libz`
、
`protobuf`
等第三方库,可在
`INSTALL_PREFIX\third_party`
下找到。
1.
如果在编译 C-API 时使用OpenBLAS矩阵库,需要显示地链接
`libopenblas.a`
。
1.
如果在编译 C-API 是使用 MKL 矩阵库,需要显示地链接 MKL 的动态库。
3.
链接静态库
`libpaddle_capi_layers.a`
和
`libpaddle_capi_engine.a`
-
使用PaddlePaddle C-API 开发预测程序链接
`libpaddle_capi_whole.a`
时,需注意:
1.
这种链接方式主要用于移动端预测。
1.
为了减少生成链接库的大小把
`libpaddle_capi_whole.a`
拆成以上两个静态链接库。
1.
需指定
`-Wl,--whole-archive -lpaddle_capi_layers`
和
`-Wl,--no-whole-archive -lpaddle_capi_engine`
进行链接。
1.
第三方依赖库需要按照与方式2同样方法显示地进行链接。
doc/howto/usage/capi/core_concepts.md
0 → 100644
浏览文件 @
635a69ba
doc/howto/usage/capi/images/csr.png
0 → 100644
浏览文件 @
635a69ba
170.3 KB
doc/howto/usage/capi/organization_of_the_inputs.md
0 → 100644
浏览文件 @
635a69ba
## 输入/输出数据组织
这篇文档介绍在使用 PaddlePaddle C-API 时如何组织输入数据,以及如何解析神经网络前向计算的输出数据。
### 输入/输出数据类型
在C-API中,按照基本数据类型在PaddlePaddle内部的定义和实现,输入数据可分为:
1.
一维整型数组
2.
二维浮点型矩阵
-
稠密矩阵
-
稀疏矩阵
-
说明:
1.
一维数组
**仅支持整型值**
;
-
常用于自然语言处理任务,例如:表示词语在词典中的序号;
-
分类任务中类别标签;
1.
逻辑上高于二维的数据(例如含有多个通道的图片,视频等)在程序实现中都会转化为二维矩阵,转化方法在相应的领域都有通用解决方案,需要使用者自己了解相关的转化表示方法;
1.
二维矩阵可以表示行向量和列向量,任何时候,如果需要浮点型数组(向量)时,都应使用C-API中的矩阵来表示,而不是C-API中的一维数组。
不论是一维整型数组还是二维浮点数矩阵,
**为它们附加上序列信息,将变成序列输入。PaddlePaddle 会通过判数据是否附带有序列信息来判断一个向量/矩阵是否是一个序列**
。关于什么是“序列信息”,下文会进行详细地介绍。
PaddlePaddle 支持两种序列类型:
1.
单层序列
-
序列中的每一个元素是非序列,是进行计算的基本单位,不可再进行拆分。
-
例如:自然语言中的句子是一个序列,序列中的元素是词语;
1.
双层序列
-
序列中的每一个元素又是一个序列。
-
例如:自然语言中的段落是一个双层序列;段落是有句子构成的序列;句子是由词语构成的序列。
-
双层序列在处理长序列的任务或是构建层级模型时会发挥作用。
### 基本使用概念
-
在PaddlePaddle内部,神经网络中一个计算层的输入/输出被组织为一个
`Argument`
结构体,如果神经网络有多个输入或者多个输入,每一个输入/输入都会对应有自己的
`Argument`
。
-
`Argument`
并不真正“存储”数据,而是将输入/输出信息有机地组织在一起。
-
在
`Argument`
内部由
`IVector`
(对应着上文提到的一维整型数组)和
`Matrix`
(对应着上文提到的二维浮点型矩阵)来实际存储数据;由
`sequence start position`
(下文详细解释) 来记录输入/输出的序列信息。
**注意:这篇文档之后部分将会统一使用`argument`来特指PaddlePaddle中神经网络计算层一个输入/输出数据;使用`ivector`来特指PaddlePaddle中的一维整型数组;使用`matrix`来特指PaddlePaddle中的二维浮点型矩阵;使用`sequence_start_position`来特指PaddlePaddle中的序列信息。**
于是,在组织神经网络输入时,需要思考完成以下工作:
1.
为每一个输入/输出创建
`argument`
。
-
C-API 中操作
`argument`
的接口请查看
[
argument.h
](
https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/capi/arguments.h
)
。
1.
为每一个
`argument`
创建
`matrix`
或者
`ivector`
来存储数据。
-
C-API 中操作
`ivector`
的接口请查看
[
vector.h
](
https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/capi/vector.h
)
。
-
C-API 中操作
`matrix`
的接口请查看
[
matrix.h
](
https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/capi/matrix.h
)
。
1.
如果输入是序列数据,需要创建并填写
`sequence_start_position`
信息。
-
通过调用
[
`paddle_arguments_set_sequence_start_pos`
](
https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/capi/arguments.h#L137
)
来为一个
`argument`
添加序列信息;
-
通过调用
[
`paddle_arguments_get_sequence_start_pos`
](
https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/capi/arguments.h#L150
)
来读取一个
`argument`
添加序列信息;
-
接口说明请查看
[
argument.h
](
https://github.com/PaddlePaddle/Paddle/blob/develop/paddle/capi/arguments.h
)
文件。
### 组织非序列数据
-
一维整型数组
概念上可以将`paddle_ivector`理解为一个一维的整型数组,通常用于表示离散的类别标签,或是在自然语言处理任务中表示词语在字典中的序号。下面的代码片段创建了含有三个元素`1`、`2`、`3`的`paddle_ivector`。
```cpp
int ids[] = {1, 2, 3};
paddle_ivector ids_array =
paddle_ivector_create(ids, sizeof(ids) / sizeof(int), false, false);
CHECK(paddle_arguments_set_ids(in_args, 0, ids_array));
```
-
**稠密矩阵**
-
一个$m×n$的稠密矩阵是一个由$m$行$n$列元素排列成的矩形阵列,矩阵里的元素是浮点数。对神经网络来说,矩阵的高度$m$是一次预测接受的样本数目,宽度$n$是神经网络定义时,
`paddle.layer.data`
的
`size`
。
-
下面的代码片段创建了一个高度为1,宽度为
`layer_size`
的稠密矩阵,矩阵中每个元素的值随机生成。
```cpp
paddle_matrix mat =
paddle_matrix_create(/* height = batch size */ 1,
/* width = dimensionality of the data layer */ layer_size,
/* whether to use GPU */ false);
paddle_real* array;
// Get the pointer pointing to the start address of the first row of the
// created matrix.
CHECK(paddle_matrix_get_row(mat, 0, &array));
// Fill the matrix with a randomly generated test sample.
srand(time(0));
for (int i = 0; i < layer_size; ++i) {
array[i] = rand() / ((float)RAND_MAX);
}
// Assign the matrix to the argument.
CHECK(paddle_arguments_set_value(in_args, 0, mat));
```
-
**稀疏矩阵**
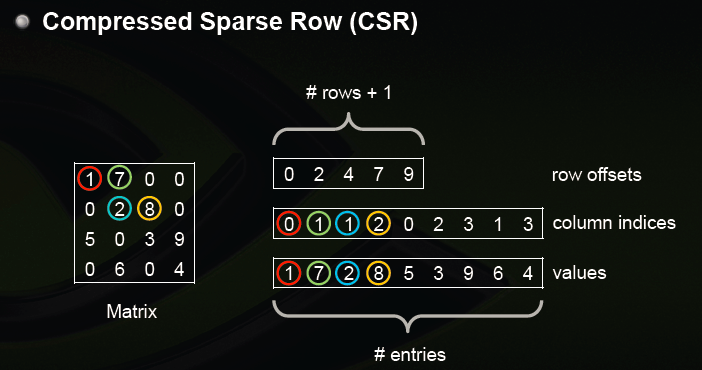
PaddlePaddle C-API 中 稀疏矩阵使用
[
CSR(Compressed Sparse Row Format)
](
https://en.wikipedia.org/wiki/Sparse_matrix#Compressed_sparse_row_(CSR,_CRS_or_Yale_format
)
)格式存储。下图是CSR存储稀疏矩阵的示意图,在CSR表示方式中,通过(1)行偏移;(2)列号;(3)值;来决定矩阵的内容。
<p
align=
"center"
>
<img
src=
"images/csr.png"
width=
75%
></br>
图1. CSR存储示意图.
</p>
在PaddlePaddle C-API中通过以下接口创建稀疏矩阵:
```
cpp
PD_API
paddle_matrix
paddle_matrix_create_sparse
(
uint64_t
height
,
uint64_t
width
,
uint64_t
nnz
,
bool
isBinary
,
bool
useGpu
);
```
1.
创建稀疏矩阵时需要显示地指定矩阵的(1)高度(
`height`
,在神经网络中等于一次预测处理的样本数)(2)宽度(
`width`
,
`paddle.layer.data`
的
`size`
)以及(3)非零元个数(
`nnz`
)。
1.
当上述接口第4个参数
`isBinary`
指定为
`true`
时,
**只需要设置行偏移(`row_offset`)和列号(`colum indices`),不需要提供元素值(`values`)**
,这时行偏移和列号指定的元素默认其值为1。
-
下面的代码片段创建了一个CPU上的二值稀疏矩阵:
```cpp
paddle_matrix mat = paddle_matrix_create_sparse(1, layer_size, nnz, true, false);
int colIndices[] = {9, 93, 109}; // layer_size here is greater than 109.
int rowOffset[] = {0, sizeof(colIndices) / sizeof(int)};
CHECK(paddle_matrix_sparse_copy_from(mat,
rowOffset,
sizeof(rowOffset) / sizeof(int),
colIndices,
sizeof(colIndices) / sizeof(int),
NULL /*values array is NULL.*/,
0 /*size of the value arrary is 0.*/));
CHECK(paddle_arguments_set_value(in_args, 0, mat));
```
-
下面的代码片段在创建了一个CPU上的带元素值的稀疏矩阵:
```
cpp
paddle_matrix
mat
=
paddle_matrix_create_sparse
(
1
,
layer_size
,
nnz
,
false
,
false
);
int
colIndices
[]
=
{
9
,
93
,
109
};
// layer_size here is greater than 109.
int
rowOffset
[]
=
{
0
,
sizeof
(
colIndices
)
/
sizeof
(
int
)};
float
values
[]
=
{
0.5
,
0.5
,
0.5
};
CHECK
(
paddle_matrix_sparse_copy_from
(
mat
,
rowOffset
,
sizeof
(
rowOffset
)
/
sizeof
(
int
),
colIndices
,
sizeof
(
colIndices
)
/
sizeof
(
int
),
values
,
sizeof
(
values
)
/
sizeof
(
float
)));
```
### 组织序列数据
### Python 端数据类型说明
下表列出了Python端训练接口暴露的数据类型(
`paddle.layer.data`
函数
`type`
字段的取值)对应于调用C-API时需要创建的数据类型:
Python 端数据类型 | C-API 输入数据类型|
:-------------: | :-------------:
`paddle.data_type.integer_value`
|一维整型数组,无需附加序列信息|
`paddle.data_type.dense_vector`
|二维浮点型稠密矩阵,无需附加序列信息|
`paddle.data_type.sparse_binary_vector`
|二维浮点型稀疏矩阵,无需提供非零元的值,默认为1,无需附加序列信息|
`paddle.data_type.sparse_vector`
|二维浮点型稀疏矩阵,需提供非零元的值,无需附加序列信息|
`paddle.data_type.integer_value_sequence`
|一维整型数组,需附加序列信息|
`paddle.data_type.dense_vector_sequence`
|二维浮点型稠密矩阵,需附加序列信息|
`paddle.data_type.sparse_binary_vector_sequence`
|二维浮点型稀疏矩阵,无需提供非零元的值,默认为1,需附加序列信息|
`paddle.data_type.sparse_vector_sequence`
|二维浮点型稀疏矩阵,需提供非零元的值,需附加序列信息|
`paddle.data_type.integer_value_sub_sequence`
|一维整型数组,需附加双层序列信息|
`paddle.data_type.dense_vector_sub_sequence`
|二维浮点型稠密矩阵,需附加双层序列信息|
`paddle.data_type.sparse_binary_vector_sub_sequence`
|二维浮点型稀疏矩阵,无需提供非零元的值,默认为1,需附加双层序列信息|
`paddle.data_type.sparse_vector_sub_sequence`
|二维浮点型稀疏矩阵,需提供非零元的值,需附加双层序列信息|
doc/howto/usage/capi/overview.md
0 → 100644
浏览文件 @
635a69ba
-
[
编译 PaddlePaddle 链接库
](
compile_paddle_lib.md
)
-
[
C-API 使用示例
](
a_simple_example.md
)
-
[
输入数据组织
](
organize_input_data.md
)
-
[
核心概念介绍
](
core_concepts.md
)
-
[
F&Q
](
)
paddle/capi/examples/model_inference/dense/main.c
浏览文件 @
635a69ba
...
...
@@ -3,59 +3,82 @@
#include "../common/common.h"
// Modify this path as needed.
#define CONFIG_BIN "./trainer_config.bin"
// Modify this path as needed.
// This demo assumes that merged model is not used, then this path is the
// directory storing all the trained parameters.
// If the model is trained by PaddlePaddle V2 API, the model is saved as
// a compressed file. You need to uncompress the compressed file first.
#define MODEL_PATH "models/pass_4"
int
main
()
{
// Initalize
Paddle
// Initalize
the PaddlePaddle runtime environment.
char
*
argv
[]
=
{
"--use_gpu=False"
};
CHECK
(
paddle_init
(
1
,
(
char
**
)
argv
));
// Read
ing config binary file. It is
generated by `convert_protobin.sh`
// Read
the binary configuration file
generated by `convert_protobin.sh`
long
size
;
void
*
buf
=
read_config
(
CONFIG_BIN
,
&
size
);
// Create
a
gradient machine for inference.
// Create
the
gradient machine for inference.
paddle_gradient_machine
machine
;
CHECK
(
paddle_gradient_machine_create_for_inference
(
&
machine
,
buf
,
(
int
)
size
));
CHECK
(
paddle_gradient_machine_randomize_param
(
machine
));
// Loading parameter. Uncomment the following line and change the directory.
// CHECK(paddle_gradient_machine_load_parameter_from_disk(machine,
// "./some_where_to_params"));
// Load the trained model. Modify the parameter MODEL_PATH to set the correct
// path of the trained model.
CHECK
(
paddle_gradient_machine_load_parameter_from_disk
(
machine
,
MODEL_PATH
));
// Inputs and outputs of the network are organized as paddle_arguments object
// in C-API. In the comments below, "argument" specifically means one input of
// the neural network in PaddlePaddle C-API.
paddle_arguments
in_args
=
paddle_arguments_create_none
();
// There is only one input of this network.
// There is only one data layer in this demo MNIST network, invoke this
// function to create one argument.
CHECK
(
paddle_arguments_resize
(
in_args
,
1
));
// Create input matrix.
paddle_matrix
mat
=
paddle_matrix_create
(
/* sample_num */
1
,
/* size */
784
,
/* useGPU */
false
);
srand
(
time
(
0
));
// Each argument needs one matrix or one ivector (integer vector, for sparse
// index input, usually used in NLP task) to holds the real input data.
// In the comments below, "matrix" specifically means the object needed by
// argument to hold the data. Here we create the matrix for the above created
// agument to store the testing samples.
paddle_matrix
mat
=
paddle_matrix_create
(
/* height = batch size */
1
,
/* width = dimensionality of the data layer */
784
,
/* whether to use GPU */
false
);
paddle_real
*
array
;
//
Get First row
.
// Get the pointer pointing to the start address of the first row of the
//
created matrix
.
CHECK
(
paddle_matrix_get_row
(
mat
,
0
,
&
array
));
// Fill the matrix with a randomly generated test sample.
srand
(
time
(
0
));
for
(
int
i
=
0
;
i
<
784
;
++
i
)
{
array
[
i
]
=
rand
()
/
((
float
)
RAND_MAX
);
}
// Assign the matrix to the argument.
CHECK
(
paddle_arguments_set_value
(
in_args
,
0
,
mat
));
// Create the output argument.
paddle_arguments
out_args
=
paddle_arguments_create_none
();
// Invoke the forward computation.
CHECK
(
paddle_gradient_machine_forward
(
machine
,
in_args
,
out_args
,
/* isTrain */
false
));
paddle_matrix
prob
=
paddle_matrix_create_none
();
/* is train taks or not */
false
));
// Create the matrix to hold the forward result of the neural network.
paddle_matrix
prob
=
paddle_matrix_create_none
();
// Access the matrix of the output argument, the predicted result is stored in
// which.
CHECK
(
paddle_arguments_get_value
(
out_args
,
0
,
prob
));
uint64_t
height
;
uint64_t
width
;
CHECK
(
paddle_matrix_get_shape
(
prob
,
&
height
,
&
width
));
CHECK
(
paddle_matrix_get_row
(
prob
,
0
,
&
array
));
...
...
@@ -68,6 +91,7 @@ int main() {
}
printf
(
"
\n
"
);
// The cleaning up.
CHECK
(
paddle_matrix_destroy
(
prob
));
CHECK
(
paddle_arguments_destroy
(
out_args
));
CHECK
(
paddle_matrix_destroy
(
mat
));
...
...
paddle/capi/examples/model_inference/dense/merge_v2_model.py
0 → 100644
浏览文件 @
635a69ba
from
paddle.utils.merge_model
import
merge_v2_model
from
mnist_v2
import
network
net
=
network
(
is_infer
=
True
)
param_file
=
"models/params_pass_4.tar"
output_file
=
"output.paddle.model"
merge_v2_model
(
net
,
param_file
,
output_file
)
paddle/capi/examples/model_inference/dense/mnist_v2.py
0 → 100644
浏览文件 @
635a69ba
import
os
import
sys
import
gzip
import
logging
import
argparse
from
PIL
import
Image
import
numpy
as
np
import
paddle.v2
as
paddle
from
paddle.utils.dump_v2_config
import
dump_v2_config
logger
=
logging
.
getLogger
(
"paddle"
)
logger
.
setLevel
(
logging
.
INFO
)
def
multilayer_perceptron
(
img
,
layer_size
,
lbl_dim
):
for
idx
,
size
in
enumerate
(
layer_size
):
hidden
=
paddle
.
layer
.
fc
(
input
=
(
img
if
not
idx
else
hidden
),
size
=
size
,
act
=
paddle
.
activation
.
Relu
())
return
paddle
.
layer
.
fc
(
input
=
hidden
,
size
=
lbl_dim
,
act
=
paddle
.
activation
.
Softmax
())
def
network
(
input_dim
=
784
,
lbl_dim
=
10
,
is_infer
=
False
):
images
=
paddle
.
layer
.
data
(
name
=
'pixel'
,
type
=
paddle
.
data_type
.
dense_vector
(
input_dim
))
predict
=
multilayer_perceptron
(
images
,
layer_size
=
[
128
,
64
],
lbl_dim
=
lbl_dim
)
if
is_infer
:
return
predict
else
:
label
=
paddle
.
layer
.
data
(
name
=
'label'
,
type
=
paddle
.
data_type
.
integer_value
(
lbl_dim
))
return
paddle
.
layer
.
classification_cost
(
input
=
predict
,
label
=
label
)
def
main
(
task
=
"train"
,
use_gpu
=
False
,
trainer_count
=
1
,
save_dir
=
"models"
):
if
task
==
"train"
:
if
not
os
.
path
.
exists
(
save_dir
):
os
.
mkdir
(
save_dir
)
paddle
.
init
(
use_gpu
=
use_gpu
,
trainer_count
=
trainer_count
)
cost
=
network
()
parameters
=
paddle
.
parameters
.
create
(
cost
)
optimizer
=
paddle
.
optimizer
.
Momentum
(
learning_rate
=
0.1
/
128.0
,
momentum
=
0.9
,
regularization
=
paddle
.
optimizer
.
L2Regularization
(
rate
=
0.0005
*
128
))
trainer
=
paddle
.
trainer
.
SGD
(
cost
=
cost
,
parameters
=
parameters
,
update_equation
=
optimizer
)
def
event_handler
(
event
):
if
isinstance
(
event
,
paddle
.
event
.
EndIteration
):
if
event
.
batch_id
%
100
==
0
:
logger
.
info
(
"Pass %d, Batch %d, Cost %f, %s"
%
(
event
.
pass_id
,
event
.
batch_id
,
event
.
cost
,
event
.
metrics
))
if
isinstance
(
event
,
paddle
.
event
.
EndPass
):
with
gzip
.
open
(
os
.
path
.
join
(
save_dir
,
"params_pass_%d.tar"
%
event
.
pass_id
),
"w"
)
as
f
:
trainer
.
save_parameter_to_tar
(
f
)
trainer
.
train
(
reader
=
paddle
.
batch
(
paddle
.
reader
.
shuffle
(
paddle
.
dataset
.
mnist
.
train
(),
buf_size
=
8192
),
batch_size
=
128
),
event_handler
=
event_handler
,
num_passes
=
5
)
elif
task
==
"dump_config"
:
predict
=
network
(
is_infer
=
True
)
dump_v2_config
(
predict
,
"trainer_config.bin"
,
True
)
else
:
raise
RuntimeError
((
"Error value for parameter task. "
"Available options are: train and dump_config."
))
def
parse_cmd
():
parser
=
argparse
.
ArgumentParser
(
description
=
"PaddlePaddle MNIST demo for CAPI."
)
parser
.
add_argument
(
"--task"
,
type
=
str
,
required
=
False
,
help
=
(
"A string indicating the taks type. "
"Available options are:
\"
train
\"
,
\"
dump_config
\"
."
),
default
=
"train"
)
parser
.
add_argument
(
"--use_gpu"
,
type
=
bool
,
help
=
(
"A bool flag indicating whether to use GPU device or not."
),
default
=
False
)
parser
.
add_argument
(
"--trainer_count"
,
type
=
int
,
help
=
(
"This parameter is only used in training task. It indicates "
"how many computing threads are created in training."
),
default
=
1
)
parser
.
add_argument
(
"--save_dir"
,
type
=
str
,
help
=
(
"This parameter is only used in training task. It indicates "
"path of the directory to save the trained models."
),
default
=
"models"
)
return
parser
.
parse_args
()
if
__name__
==
"__main__"
:
args
=
parse_cmd
()
main
(
args
.
task
,
args
.
use_gpu
,
args
.
trainer_count
,
args
.
save_dir
)
paddle/capi/examples/model_inference/sparse_binary/main.c
浏览文件 @
635a69ba
#include <paddle/capi.h>
#include <time.h>
#include "../common/common.h"
#define CONFIG_BIN "./trainer_config.bin"
...
...
@@ -9,16 +10,18 @@ int main() {
char
*
argv
[]
=
{
"--use_gpu=False"
};
CHECK
(
paddle_init
(
1
,
(
char
**
)
argv
));
// Reading config binary file. It is generated by `convert_protobin.sh`
// Read the binary configuration file which is generated by
// `convert_protobin.sh`
long
size
;
void
*
buf
=
read_config
(
CONFIG_BIN
,
&
size
);
// Create
a
gradient machine for inference.
// Create
the
gradient machine for inference.
paddle_gradient_machine
machine
;
CHECK
(
paddle_gradient_machine_create_for_inference
(
&
machine
,
buf
,
(
int
)
size
));
CHECK
(
paddle_gradient_machine_randomize_param
(
machine
));
// Loading parameter. Uncomment the following line and change the directory.
// Load the trained parameters. Uncomment the following line and change the
// directory as needed.
// CHECK(paddle_gradient_machine_load_parameter_from_disk(machine,
// "./some_where_to_params"));
paddle_arguments
in_args
=
paddle_arguments_create_none
();
...
...
@@ -26,7 +29,7 @@ int main() {
// There is only one input of this network.
CHECK
(
paddle_arguments_resize
(
in_args
,
1
));
// Create input matrix.
// Create
the
input matrix.
paddle_matrix
mat
=
paddle_matrix_create_sparse
(
1
,
784
,
3
,
true
,
false
);
srand
(
time
(
0
));
paddle_real
*
array
;
...
...
python/paddle/utils/dump_v2_config.py
0 → 100644
浏览文件 @
635a69ba
# Copyright (c) 2016 PaddlePaddle Authors. All Rights Reserved
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import
collections
from
paddle.trainer_config_helpers.layers
import
LayerOutput
from
paddle.v2.layer
import
parse_network
from
paddle.proto
import
TrainerConfig_pb2
__all__
=
[
"dump_v2_config"
]
def
dump_v2_config
(
topology
,
save_path
,
binary
=
False
):
""" Dump the network topology to a specified file.
This function is only used to dump network defined by using PaddlePaddle V2
APIs. This function will NOT dump configurations related to PaddlePaddle
optimizer.
:param topology: The output layers (can be more than one layers given in a
Python List or Tuple) of the entire network. Using the
specified layers (if more than one layer is given) as root,
traversing back to the data layer(s), all the layers
connected to the specified output layers will be dumped.
Layers not connceted to the specified will not be dumped.
:type topology: LayerOutput|List|Tuple
:param save_path: The path to save the dumped network topology.
:type save_path: str
:param binary: Whether to dump the serialized network topology or not.
The default value is false. NOTE that, if you call this
function to generate network topology for PaddlePaddle C-API,
a serialized version of network topology is required. When
using PaddlePaddle C-API, this flag MUST be set to True.
:type binary: bool
"""
if
isinstance
(
topology
,
LayerOutput
):
topology
=
[
topology
]
elif
isinstance
(
topology
,
collections
.
Sequence
):
for
out_layer
in
topology
:
assert
isinstance
(
out_layer
,
LayerOutput
),
(
"The type of each element in the parameter topology "
"should be LayerOutput."
)
else
:
raise
RuntimeError
(
"Error input type for parameter topology."
)
model_str
=
parse_network
(
topology
)
with
open
(
save_path
,
"w"
)
as
fout
:
if
binary
:
fout
.
write
(
model_str
.
SerializeToString
())
else
:
fout
.
write
(
str
(
model_str
))
python/paddle/utils/merge_model.py
浏览文件 @
635a69ba
...
...
@@ -30,7 +30,8 @@ def merge_v2_model(net, param_file, output_file):
which ends with .tar.gz.
@param net The output layer of the network for inference.
@param param_file Path of the parameters (.tar.gz) which is stored by v2 api.
@param param_file Path of the parameters (.tar.gz) which is stored by
v2 api.
@param output_file Path of the merged file which will be generated.
Usage:
...
...
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}