Initial commit
上级
Showing
.gitattributes
0 → 100644
.gitignore
0 → 100755
LICENSE
0 → 100644
此差异已折叠。
README.md
0 → 100755
cfg/coco.data
0 → 100644
cfg/yolov3.cfg
0 → 100755
data/coco.names
0 → 100755
data/coco_training_loss.png
0 → 100644
{kind=link}
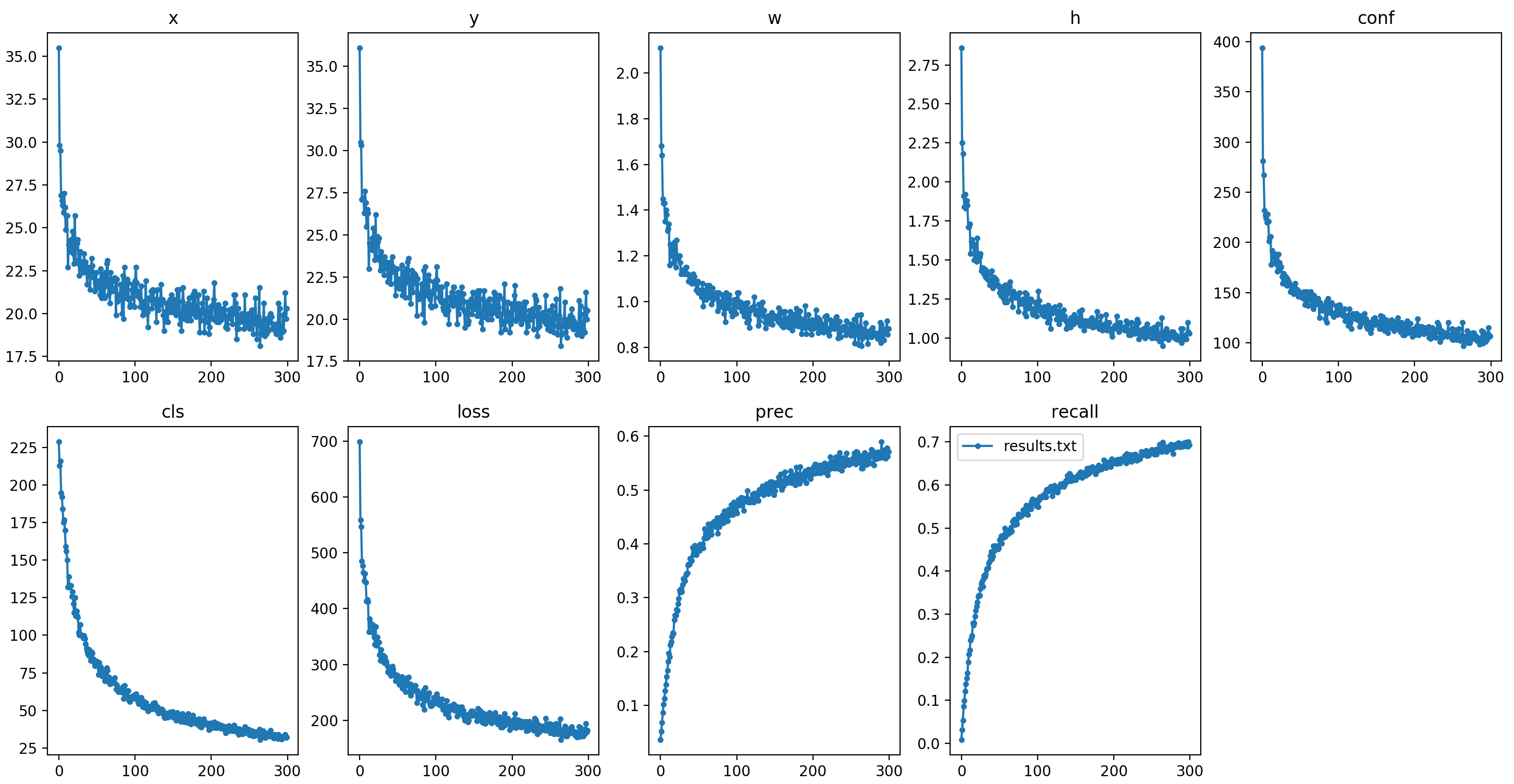
353.2 KB
data/get_coco_dataset.sh
0 → 100755
data/zidane_result.jpg
0 → 100644
{kind=link}
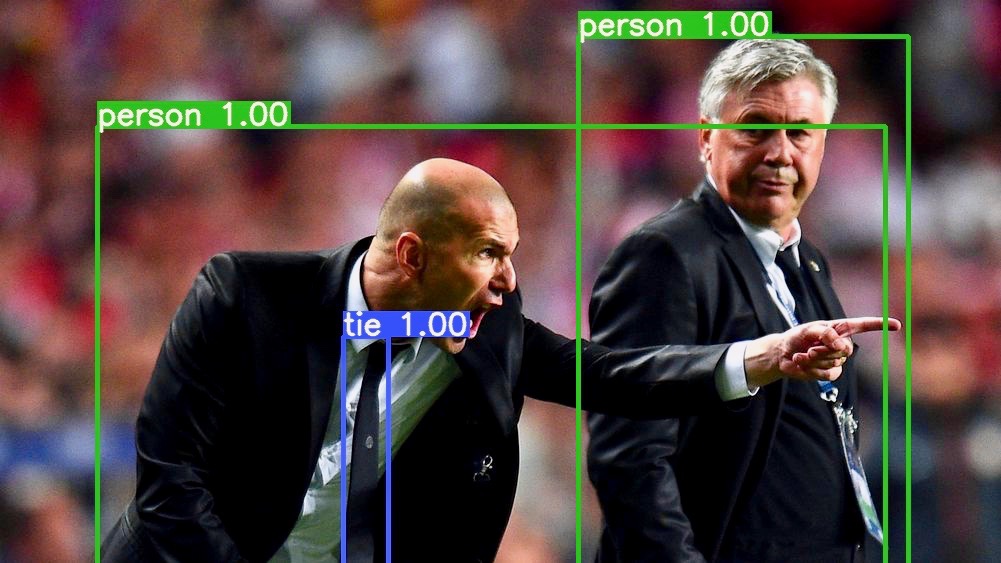
155.9 KB
detect.py
0 → 100755
models.py
0 → 100755
requirements.txt
0 → 100755
| # pip3 install -U -r requirements.txt | ||
| numpy | ||
| scipy | ||
| opencv-python | ||
| torch | ||
| matplotlib | ||
| tqdm | ||
| h5py | ||
| \ No newline at end of file |
results.txt
0 → 100644
此差异已折叠。
test.py
0 → 100644
train.py
0 → 100644
utils/datasets.py
0 → 100755
utils/gcp.sh
0 → 100644
utils/parse_config.py
0 → 100644
utils/utils.py
0 → 100755