2020-09-08 18:35:52
Showing
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
{kind=link}

655 字节
{kind=link}
3.3 KB
{kind=link}

32.0 KB
{kind=link}
4.7 KB
{kind=link}
12.6 KB
{kind=link}
2.3 KB
{kind=link}
5.6 KB
{kind=link}
9.5 KB
{kind=link}
3.7 KB
{kind=link}
38.1 KB
{kind=link}

865 字节
{kind=link}
15.4 KB
{kind=link}

14.6 KB
{kind=link}

19.2 KB
{kind=link}

27.6 KB
{kind=link}

26.5 KB
{kind=link}
3.8 KB
{kind=link}
3.4 KB
{kind=link}

8.2 KB
{kind=link}
6.8 KB
{kind=link}
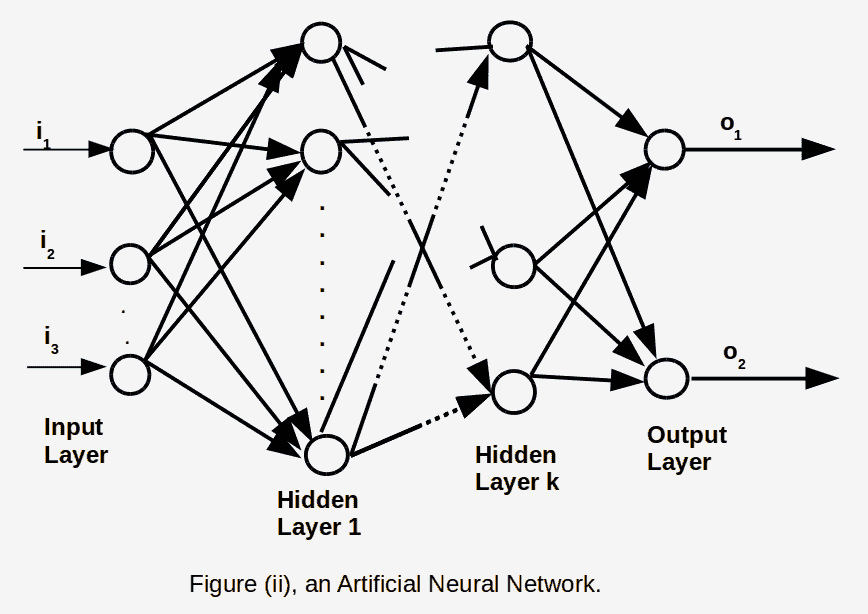
16.9 KB
{kind=link}
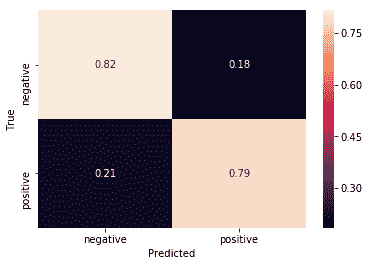
2.8 KB
{kind=link}
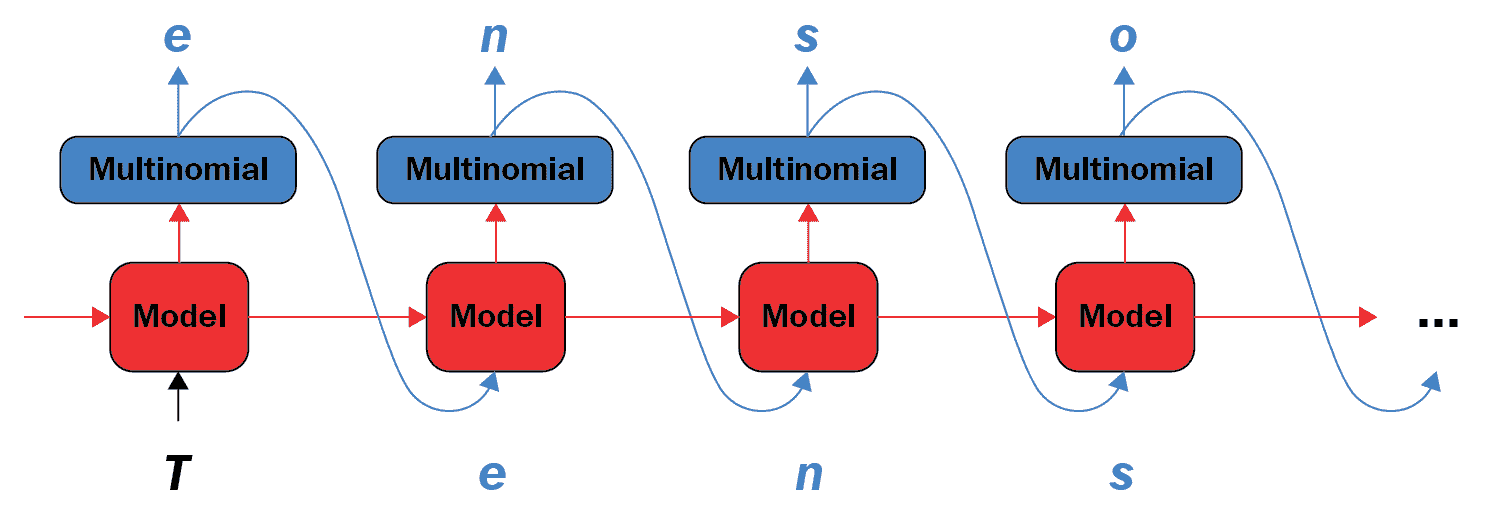
12.8 KB
{kind=link}
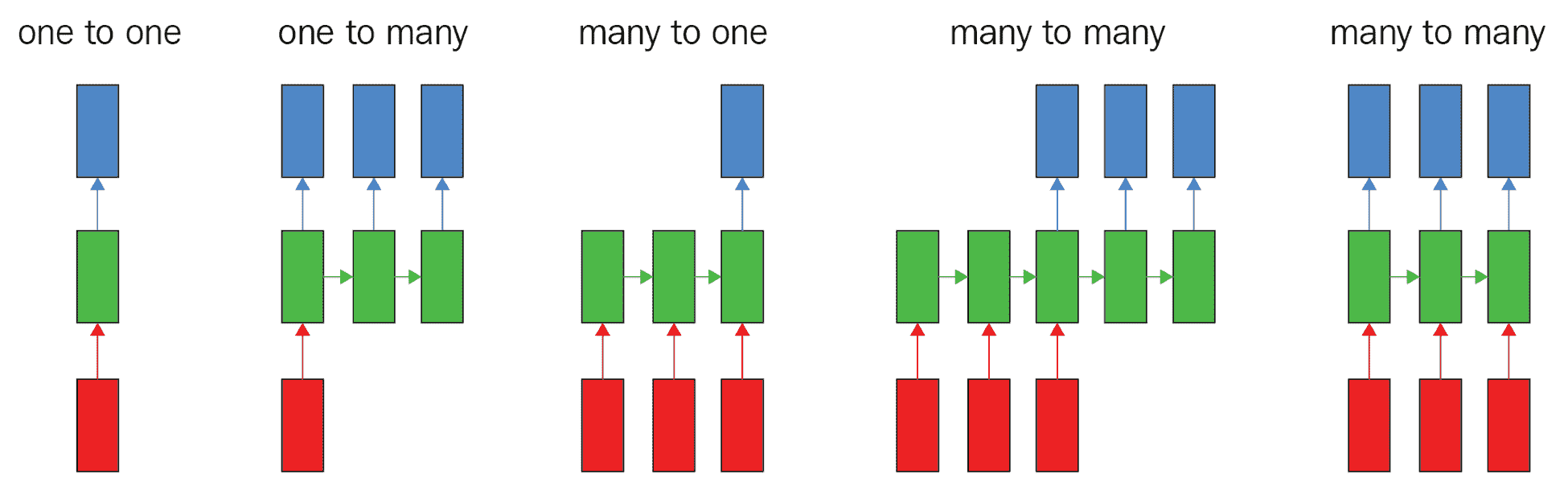
10.5 KB
{kind=link}
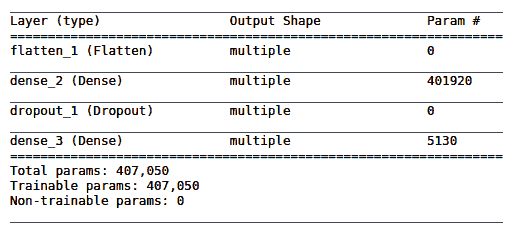
3.2 KB
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
{kind=link}
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。