Merge remote-tracking branch 'origin/develop' into feature/os
Showing
documentation20/Connector.md
已删除
100644 → 0
此差异已折叠。
documentation20/Model-ch.md
已删除
100644 → 0
此差异已折叠。
documentation20/Queries-ch.md
已删除
100644 → 0
此差异已折叠。
documentation20/TAOS SQL.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
documentation20/cluster.md
已删除
100644 → 0
此差异已折叠。
此差异已折叠。
documentation20/faq-ch.md
已删除
100644 → 0
此差异已折叠。
documentation20/faq.md
已删除
100644 → 0
此差异已折叠。
documentation20/insert-ch.md
已删除
100644 → 0
此差异已折叠。
{kind=link}
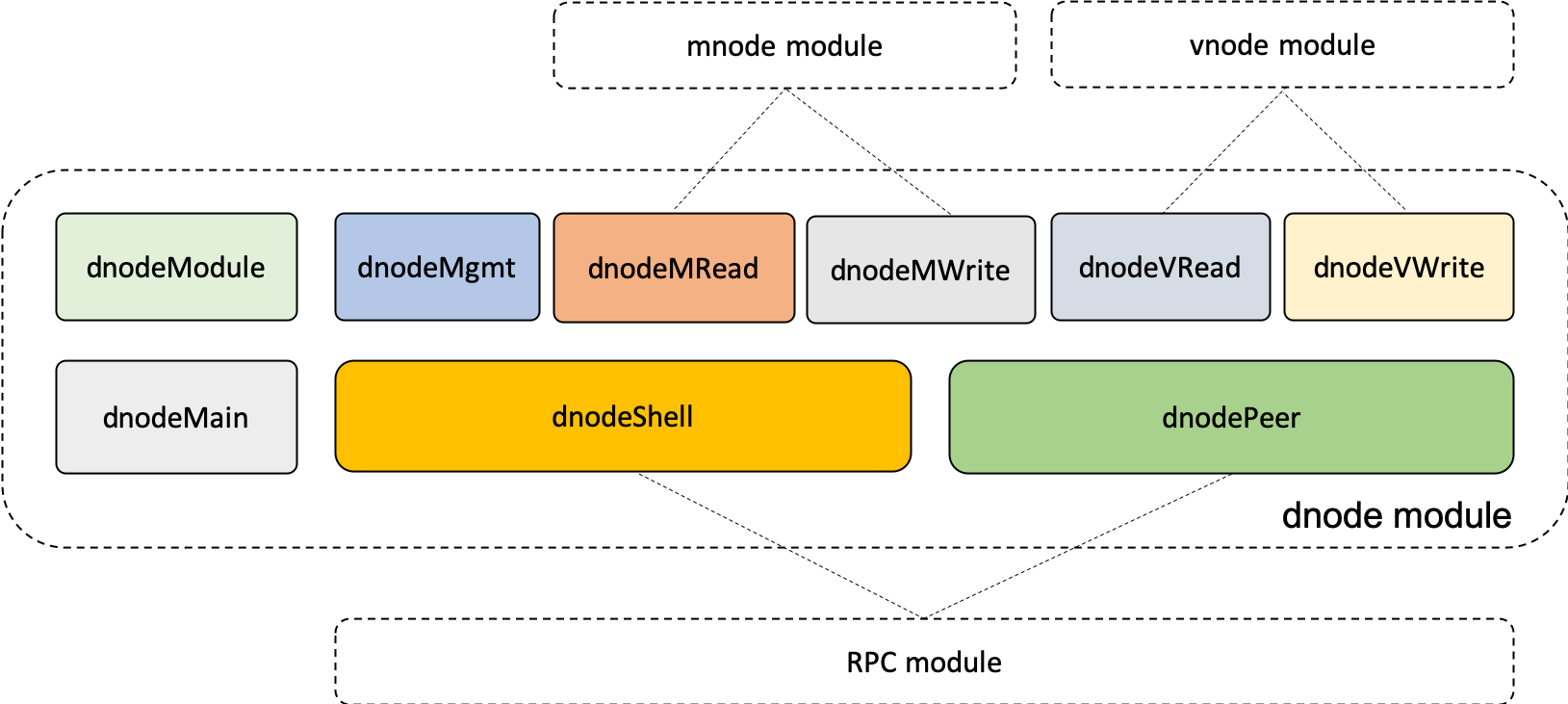
96.9 KB
{kind=link}

86.9 KB
{kind=link}

65.0 KB
{kind=link}

114.5 KB
{kind=link}

169.2 KB
{kind=link}
{kind=link}

| W: | H:
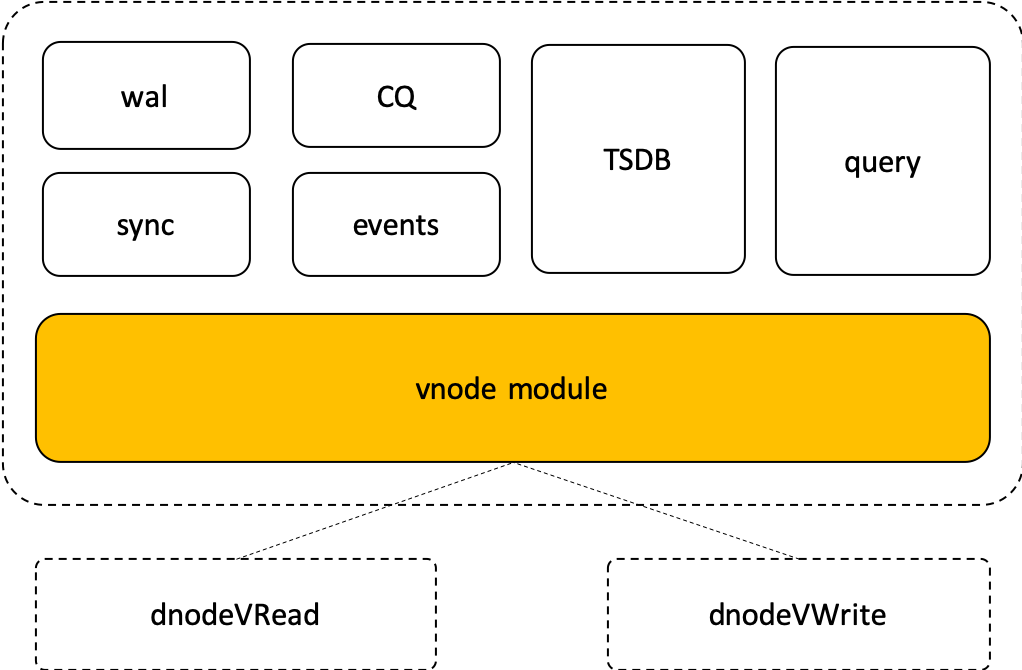
| W: | H:
此差异已折叠。
此差异已折叠。
此差异已折叠。