Skip to content
体验新版
项目
组织
正在加载...
登录
切换导航
打开侧边栏
空巢青年_rui
PaddleOCR
提交
b7837fcf
P
PaddleOCR
项目概览
空巢青年_rui
/
PaddleOCR
与 Fork 源项目一致
Fork自
PaddlePaddle / PaddleOCR
通知
1
Star
0
Fork
0
代码
文件
提交
分支
Tags
贡献者
分支图
Diff
Issue
0
列表
看板
标记
里程碑
合并请求
0
Wiki
0
Wiki
分析
仓库
DevOps
项目成员
Pages
P
PaddleOCR
项目概览
项目概览
详情
发布
仓库
仓库
文件
提交
分支
标签
贡献者
分支图
比较
Issue
0
Issue
0
列表
看板
标记
里程碑
合并请求
0
合并请求
0
Pages
分析
分析
仓库分析
DevOps
Wiki
0
Wiki
成员
成员
收起侧边栏
关闭侧边栏
动态
分支图
创建新Issue
提交
Issue看板
前往新版Gitcode,体验更适合开发者的 AI 搜索 >>
提交
b7837fcf
编写于
9月 06, 2021
作者:
G
grasswolfs
浏览文件
操作
浏览文件
下载
电子邮件补丁
差异文件
test=document_fix, test=dygraph
上级
2a77aca8
变更
2
隐藏空白更改
内联
并排
Showing
2 changed file
with
16 addition
and
11 deletion
+16
-11
README_ch.md
README_ch.md
+16
-11
doc/ppocrv2_framework.jpg
doc/ppocrv2_framework.jpg
+0
-0
未找到文件。
README_ch.md
浏览文件 @
b7837fcf
...
...
@@ -24,23 +24,23 @@ PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力
## 注意
PaddleOCR同时支持动态图与静态图两种编程范式
-
动态图版本:release/2.
2
(默认分支,开发分支为dygraph分支),需将paddle版本升级至2.0.0或以上版本(
[
快速安装
](
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.2/doc/doc_ch/installation.md
)
)
-
动态图版本:release/2.
3
(默认分支,开发分支为dygraph分支),需将paddle版本升级至2.0.0或以上版本(
[
快速安装
](
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.2/doc/doc_ch/installation.md
)
)
-
静态图版本:develop分支
**近期更新**
-
PaddleOCR研发团队对最新发版内容技术深入解读,8月4日晚上20:15,
[
直播地址
](
https://live.bilibili.com/21689802
)
。
-
2021.8.3 正式发布PaddleOCR v2.2,新增文档结构分析
[
PP-Structure
](
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.2/ppstructure/README_ch.md
)
工具包,支持版面分析与表格识别(含Excel导出)。
-
PaddleOCR研发团队对最新发版内容技术深入解读,9月8日晚上20:15,
[
直播地址
](
https://live.bilibili.com/21689802
)
。
-
2021.9.7 发布PaddleOCR v2.3,发布PP-OCRv2算法,CPU推理速度相比于PP-OCR server提升220%;效果相比于PP-OCR mobile 提升7%。
-
2021.8.3 发布PaddleOCR v2.2,新增文档结构分析
[
PP-Structure
](
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.2/ppstructure/README_ch.md
)
工具包,支持版面分析与表格识别(含Excel导出)。
-
2021.6.29
[
FAQ
](
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.2/doc/doc_ch/FAQ.md
)
新增5个高频问题,总数248个,每周一都会更新,欢迎大家持续关注。
-
2021.4.8 release 2.1版本,新增AAAI 2021论文
[
端到端识别算法PGNet
](
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.2/doc/doc_ch/pgnet.md
)
开源,
[
多语言模型
](
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.2/doc/doc_ch/multi_languages.md
)
支持种类增加到80+。
-
2021.2.8 正式发布PaddleOCRv2.0(branch release/2.0)并设置为推荐用户使用的默认分支. 发布的详细内容,请参考: https://github.com/PaddlePaddle/PaddleOCR/releases/tag/v2.0.0
-
2021.1.26,28,29 PaddleOCR官方研发团队带来技术深入解读三日直播课,1月26日、28日、29日晚上19:30,
[
直播地址
](
https://live.bilibili.com/21689802
)
-
[
More
](
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.2/doc/doc_ch/update.md
)
## 特性
-
PPOCR系列高质量预训练模型,准确的识别效果
-
超轻量ppocrv2系列:检测(3.1M)+ 识别(8.5M)= 11.6M
-
超轻量ppocr_mobile移动端系列:检测(3.0M)+方向分类器(1.4M)+ 识别(5.0M)= 9.4M
-
通用ppocr_server系列:检测(47.1M)+方向分类器(1.4M)+ 识别(94.9M)= 143.4M
-
支持中英文数字组合识别、竖排文本识别、长文本识别
...
...
@@ -84,6 +84,7 @@ PaddleOCR同时支持动态图与静态图两种编程范式
<a
name=
"模型下载"
></a>
## PP-OCR 2.0系列模型列表(更新中)
**说明**
:2.0版模型和
[
1.1版模型
](
https://github.com/PaddlePaddle/PaddleOCR/blob/develop/doc/doc_ch/models_list.md
)
的主要区别在于动态图训练vs.静态图训练,模型性能上无明显差距。
| 模型简介 | 模型名称 |推荐场景 | 检测模型 | 方向分类器 | 识别模型 |
| ------------ | --------------- | ----------------|---- | ---------- | -------- |
| 中英文超轻量OCR模型(9.4M) | ch_ppocr_mobile_v2.0_xx |移动端&服务器端|
[
推理模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_infer.tar
)
/
[
预训练模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_det_train.tar
)
|
[
推理模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar
)
/
[
预训练模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_train.tar
)
|
[
推理模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_infer.tar
)
/
[
预训练模型
](
https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_rec_pre.tar
)
|
...
...
@@ -93,8 +94,8 @@ PaddleOCR同时支持动态图与静态图两种编程范式
## 文档教程
-
[
运行环境准备
](
./doc/doc_ch/environment.md
)
-
[
快速开始
](
./doc/doc_ch/quickstart.md
)
-
[
PaddleOCR全景图与
安装
](
./doc/doc_ch/paddleOCR_overview.md
)
-
[
快速开始
(中英文/多语言/文档分析)
](
./doc/doc_ch/quickstart.md
)
-
[
PaddleOCR全景图与
项目克隆
](
./doc/doc_ch/paddleOCR_overview.md
)
-
PP-OCR产业落地:从训练到部署
-
[
PP-OCR模型与配置文件
](
./doc/doc_ch/models_and_config.md
)
-
[
PP-OCR模型下载
](
./doc/doc_ch/models_list.md
)
...
...
@@ -137,13 +138,17 @@ PaddleOCR同时支持动态图与静态图两种编程范式
-
[
代码组织结构
](
./doc/doc_ch/tree.md
)
<a
name=
"PP-OCR"
></a>
## PP-OCR Pipeline
<a
name=
"PP-OCRv2"
></a>
## PP-OCRv2 Pipeline
<div
align=
"center"
>
<img
src=
"./doc/ppocr
_framework.pn
g"
width=
"800"
>
<img
src=
"./doc/ppocr
v2_framework.jp
g"
width=
"800"
>
</div>
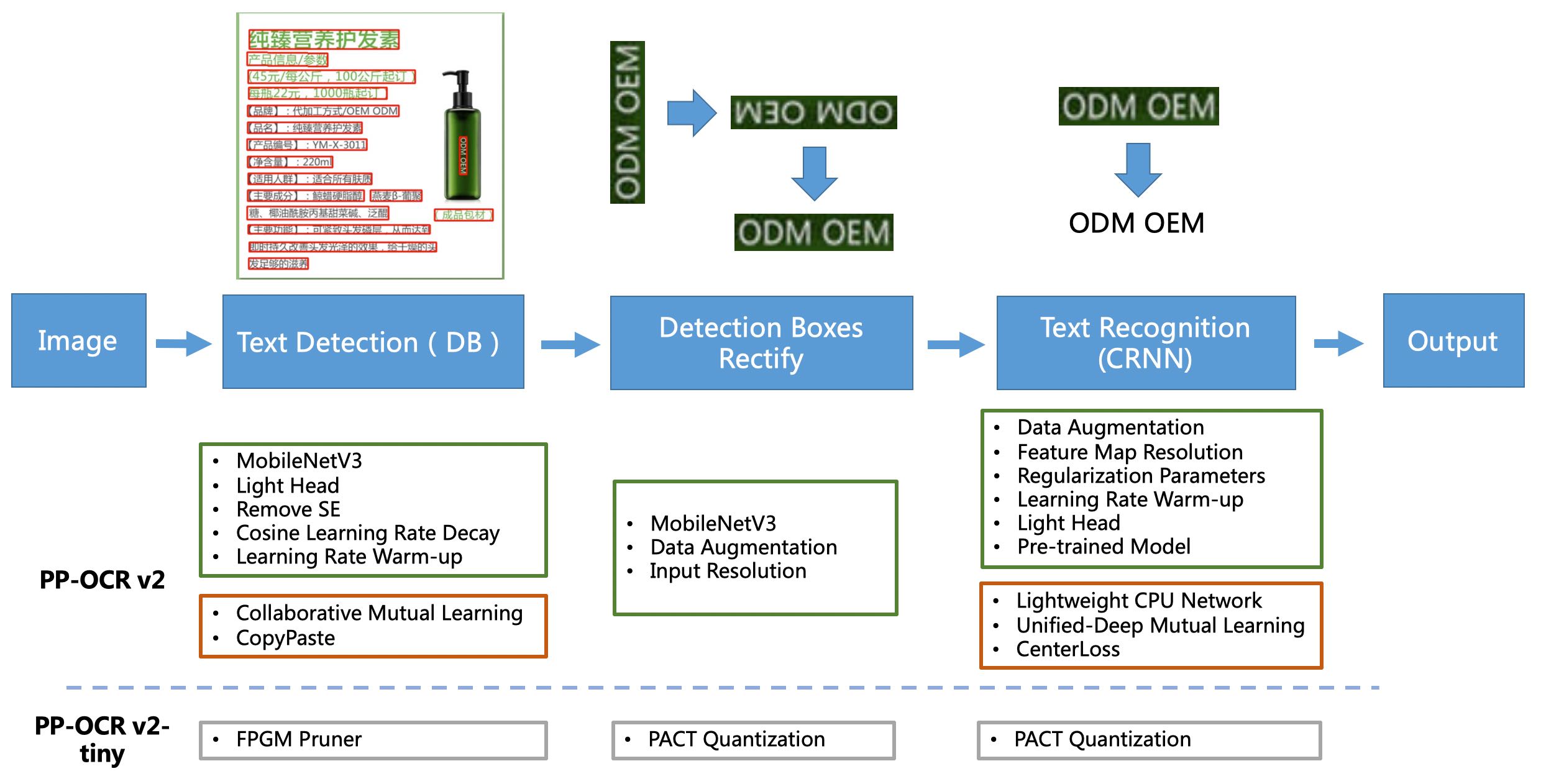
PP-OCR是一个实用的超轻量OCR系统。主要由DB文本检测
[
2]、检测框矫正和CRNN文本识别三部分组成[7]。该系统从骨干网络选择和调整、预测头部的设计、数据增强、学习率变换策略、正则化参数选择、预训练模型使用以及模型自动裁剪量化8个方面,采用19个有效策略,对各个模块的模型进行效果调优和瘦身,最终得到整体大小为3.5M的超轻量中英文OCR和2.8M的英文数字OCR。更多细节请参考PP-OCR技术方案 https://arxiv.org/abs/2009.09941 。其中FPGM裁剪器[8]和PACT量化[9]的实现可以参考[PaddleSlim
](
https://github.com/PaddlePaddle/PaddleSlim
)
。
[1] PP-OCR是一个实用的超轻量OCR系统。主要由DB文本检测、检测框矫正和CRNN文本识别三部分组成。该系统从骨干网络选择和调整、预测头部的设计、数据增强、学习率变换策略、正则化参数选择、预训练模型使用以及模型自动裁剪量化8个方面,采用19个有效策略,对各个模块的模型进行效果调优和瘦身(如绿框所示),最终得到整体大小为3.5M的超轻量中英文OCR和2.8M的英文数字OCR。更多细节请参考PP-OCR技术方案 https://arxiv.org/abs/2009.09941
[2] PP-OCRv2在PP—OCR的基础上,进一步在5个方面重点优化,检测模型采用CML协同互学习知识蒸馏策略和CopyPaste数据增广策略;识别模型采用LCNet轻量级骨干网络、UDML 改进知识蒸馏策略和Enhanced CTC loss损失函数改进(如上图红框所示),进一步在推理速度和预测效果上取得明显提升。更多细节请参考PP-OCR技术方案(arxiv链接生成中)。
<a
name=
"效果展示"
></a>
## 效果展示 [more](./doc/doc_ch/visualization.md)
...
...
doc/ppocrv2_framework.jpg
0 → 100644
浏览文件 @
b7837fcf
260.7 KB
编辑
预览
Markdown
is supported
0%
请重试
或
添加新附件
.
添加附件
取消
You are about to add
0
people
to the discussion. Proceed with caution.
先完成此消息的编辑!
取消
想要评论请
注册
或
登录
{kind=link}