调整了目录结构,修订了部分文档
Showing
Day61-65/75.常见反爬策略及应对方案.md
已删除
100644 → 0
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Day71-80/71.人工智能和机器学习概述.md
0 → 100644
Day71-80/72.k最近邻分类.md
0 → 100644
{kind=link}

309.7 KB
Day71-80/res/face_paying.png
0 → 100644
{kind=link}
709.6 KB
Day71-80/res/quickdraw.png
0 → 100644
{kind=link}

168.1 KB
Day71-80/res/sweep_robot.jpg
0 → 100644
{kind=link}

174.1 KB
{kind=link}

173.0 KB
Day71-90/71.机器学习基础.md
已删除
100644 → 0
Day71-90/72.k最近邻分类.md
已删除
100644 → 0
res/python-bj-salary.png
已删除
100644 → 0
{kind=link}

116.1 KB
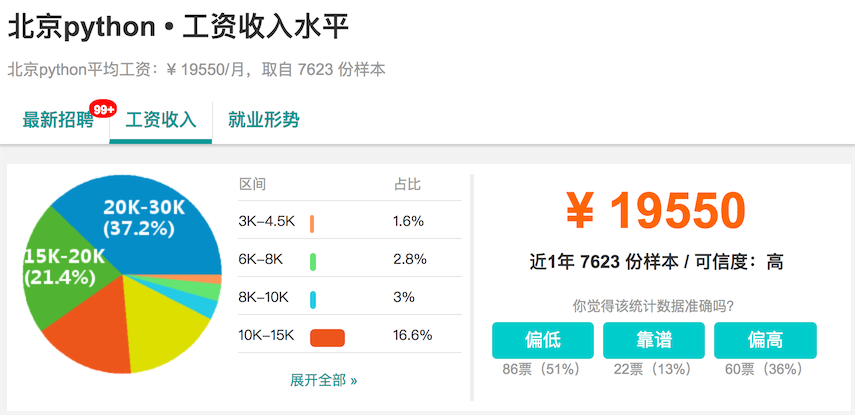
res/python-salary-beijing.png
已删除
100644 → 0
{kind=link}
100.3 KB
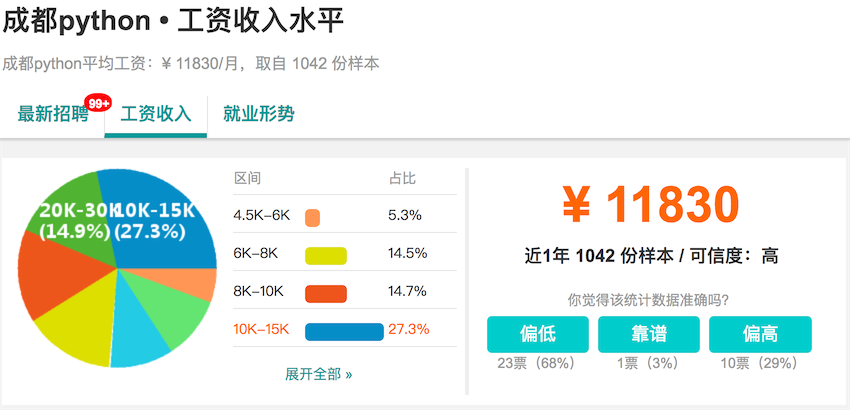
res/python-salary-chengdu.png
已删除
100644 → 0
{kind=link}
100.1 KB
res/python-salary.png
已删除
100644 → 0
{kind=link}
47.0 KB
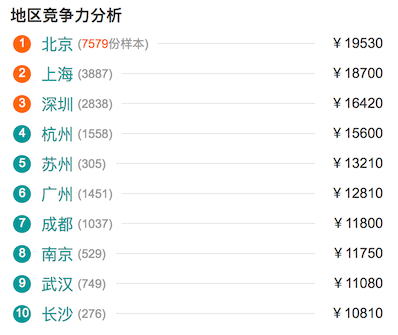
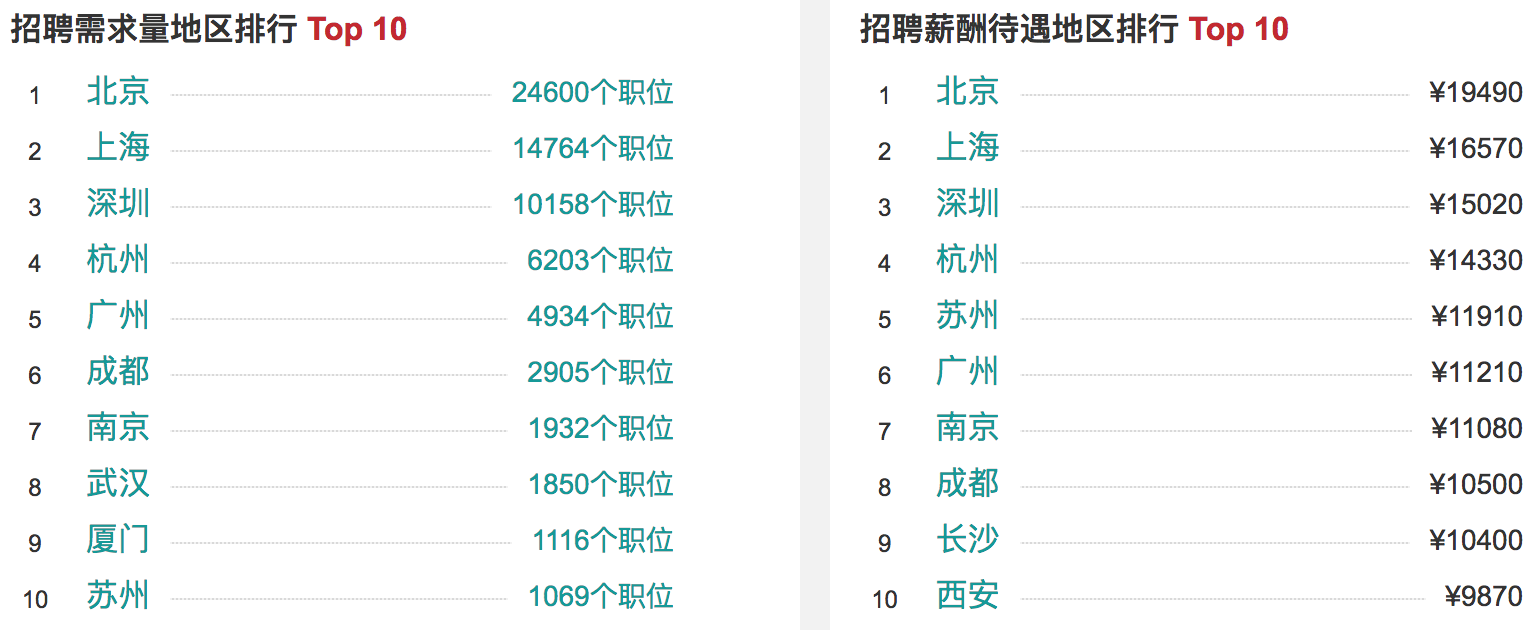
res/python-top-10.png
已删除
100644 → 0
{kind=link}
75.3 KB
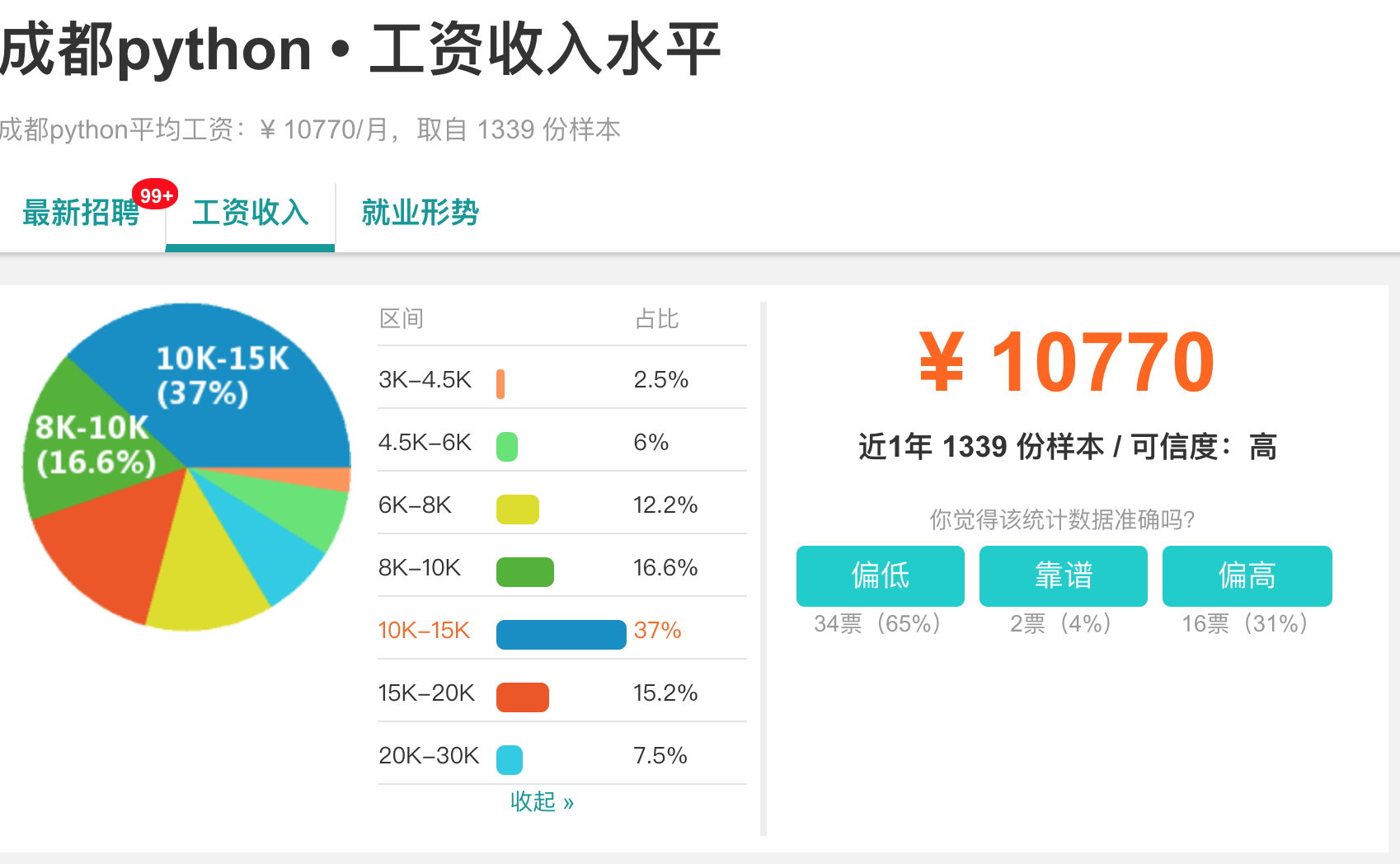
res/python_salary_chengdu.png
已删除
100644 → 0
{kind=link}
121.9 KB