added inception model
Showing
.gitmodules
0 → 100644
WORKSPACE
0 → 100644
inception/BUILD
0 → 100644
inception/README.md
0 → 100644
此差异已折叠。
此差异已折叠。
此差异已折叠。
此差异已折叠。
inception/dataset.py
0 → 100644
inception/flowers_data.py
0 → 100644
inception/flowers_eval.py
0 → 100644
inception/flowers_train.py
0 → 100644
{kind=link}
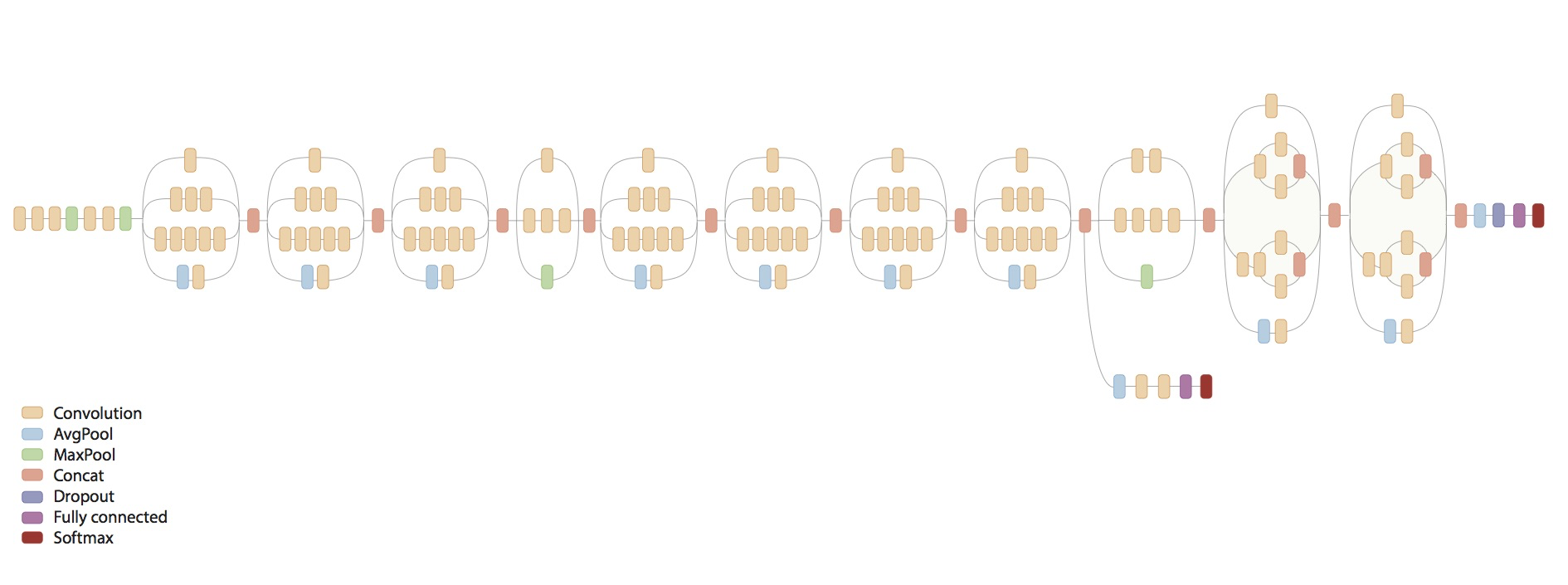
338.7 KB
inception/image_processing.py
0 → 100644
inception/imagenet_data.py
0 → 100644
inception/imagenet_eval.py
0 → 100644
inception/imagenet_train.py
0 → 100644
inception/inception_eval.py
0 → 100644
inception/inception_model.py
0 → 100644
inception/inception_train.py
0 → 100644
此差异已折叠。
inception/slim/BUILD
0 → 100644
inception/slim/README.md
0 → 100644
此差异已折叠。
inception/slim/inception_model.py
0 → 100644
此差异已折叠。
inception/slim/inception_test.py
0 → 100644
此差异已折叠。
inception/slim/losses.py
0 → 100644
此差异已折叠。
inception/slim/losses_test.py
0 → 100644
此差异已折叠。
inception/slim/ops.py
0 → 100644
此差异已折叠。
inception/slim/ops_test.py
0 → 100644
此差异已折叠。
inception/slim/scopes.py
0 → 100644
此差异已折叠。
inception/slim/scopes_test.py
0 → 100644
此差异已折叠。
inception/slim/slim.py
0 → 100644
此差异已折叠。
inception/slim/variables.py
0 → 100644
此差异已折叠。
inception/slim/variables_test.py
0 → 100644
此差异已折叠。
third_party
0 → 120000
tools
0 → 120000